人工知能
Gemma 2の完全ガイド: Googleの新しいオープン大規模言語モデル

Gemma 2は、その前身に基づいており、パフォーマンスと効率が向上し、研究と実用的なアプリケーションの両方にとって特に魅力的である一連の革新的な機能を提供しています。Gemma 2を際立たせるのは、その大規模なプロプライエタリモデルに匹敵するパフォーマンスを提供する能力ですが、より幅広いアクセス性とより謙虚なハードウェア設定での使用に適したパッケージで提供されることです。
Gemma 2の技術仕様とアーキテクチャに深入してみると、その設計の工夫にますます感銘を受けるようになりました。モデルには、独自の注意メカニズムやトレーニングの安定性への革新的なアプローチなど、複数の高度なテクニックが組み込まれており、これらがその驚異的な能力に貢献しています。

Google Open Source LLM Gemma
この包括的なガイドでは、Gemma 2を詳細に調査し、そのアーキテクチャ、主要な機能、実用的なアプリケーションを検討します。経験豊富なAIの実践者であっても、フィールドの熱心な新人であっても、この記事はGemma 2の動作方法とその力を自分のプロジェクトで活用する方法についての貴重な洞察を提供することを目指しています。
Gemma 2とは何か?
Gemma 2は、Googleの最新のオープンソース大規模言語モデルであり、軽量でありながら強力です。Geminiモデルを作成するために使用された同じ研究と技術を基にしており、最先端のパフォーマンスをよりアクセスしやすいパッケージで提供します。Gemma 2は2つのサイズで利用できます。
Gemma 2 9B: 9億パラメータモデル
Gemma 2 27B: 27億パラメータのより大きなモデル
各サイズには2つのバリアントがあります。
ベースモデル: 広大なテキストデータコーパスで事前トレーニングされたもの
インストラクションチューニング(IT)モデル: 特定のタスクでのパフォーマンスを向上させるためにファインチューニングされたもの
Google AI Studioでモデルにアクセスする: Google AI Studio – Gemma 2
論文をここで読む: Gemma 2技術報告書
主要な機能と改善点
Gemma 2は、前身モデルに対していくつかの重大な進歩を導入しています。
1. トレーニングデータの増加
モデルは、実質的に多くのデータでトレーニングされています。
Gemma 2 27B: 13兆トークンでトレーニング
Gemma 2 9B: 8兆トークンでトレーニング
この拡張データセットは、主にウェブデータ(主に英語)、コード、数学で構成されており、モデルのパフォーマンスと汎用性の向上に貢献しています。
2. スライディングウィンドウ注意
Gemma 2は、注意メカニズムに対する新しいアプローチを実装しています。
毎-otherレイヤーは、4096トークンのローカルコンテキストを持つスライディングウィンドウ注意を使用
交互のレイヤーは、全体の8192トークンコンテキスト全体で二乗法的注意を使用
このハイブリッドアプローチは、効率性と入力内の長距離依存関係を捉える能力のバランスを目指しています。
3. ソフトキャップ
トレーニングの安定性とパフォーマンスを向上させるために、Gemma 2はソフトキャップメカニズムを導入しています。
def soft_cap(x, cap): return cap * torch.tanh(x / cap) # 注意ログを適用 attention_logits = soft_cap(attention_logits, cap=50.0) # 最終層ログを適用 final_logits = soft_cap(final_logits, cap=30.0)
このテクニックは、ハードトランケーションなしでロジットが過度に大きくなるのを防ぎ、トレーニングプロセスを安定化させながら、より多くの情報を保持します。
- Gemma 2 9B: 9億パラメータモデル
- Gemma 2 27B: 27億パラメータのより大きなモデル
各サイズには2つのバリアントがあります。
- ベースモデル: 広大なテキストデータコーパスで事前トレーニングされたもの
- インストラクションチューニング(IT)モデル: 特定のタスクでのパフォーマンスを向上させるためにファインチューニングされたもの
4. ナレッジディスティレーション
9Bモデルでは、Gemma 2はナレッジディスティレーションテクニックを使用しています。
- 事前トレーニング: 9Bモデルは、初期トレーニング中に大きな教師モデルから学習します
- 事後トレーニング: 9Bモデルと27Bモデルは、ポリシーの改善にオンプレーンディスティレーションを使用します
このプロセスは、小さいモデルが大きなモデルの能力をより効果的に捉えるのを助けます。
5. モデルマージング
Gemma 2は、Warpという名前の新しいモデルマージングテクニックを使用します。これは、3つのステージで複数のモデルを組み合わせます。
- 強化学習ファインチューニング中の指数移動平均(EMA)
- 複数のポリシーをファインチューニングした後、球面線形補間(SLERP)
- 最終ステップとして、初期化への線形補間(LITI)
このアプローチは、より強固で有能な最終モデルを作成することを目指しています。
パフォーマンスベンチマーク
Gemma 2は、さまざまなベンチマークで印象的なパフォーマンスを示しています。
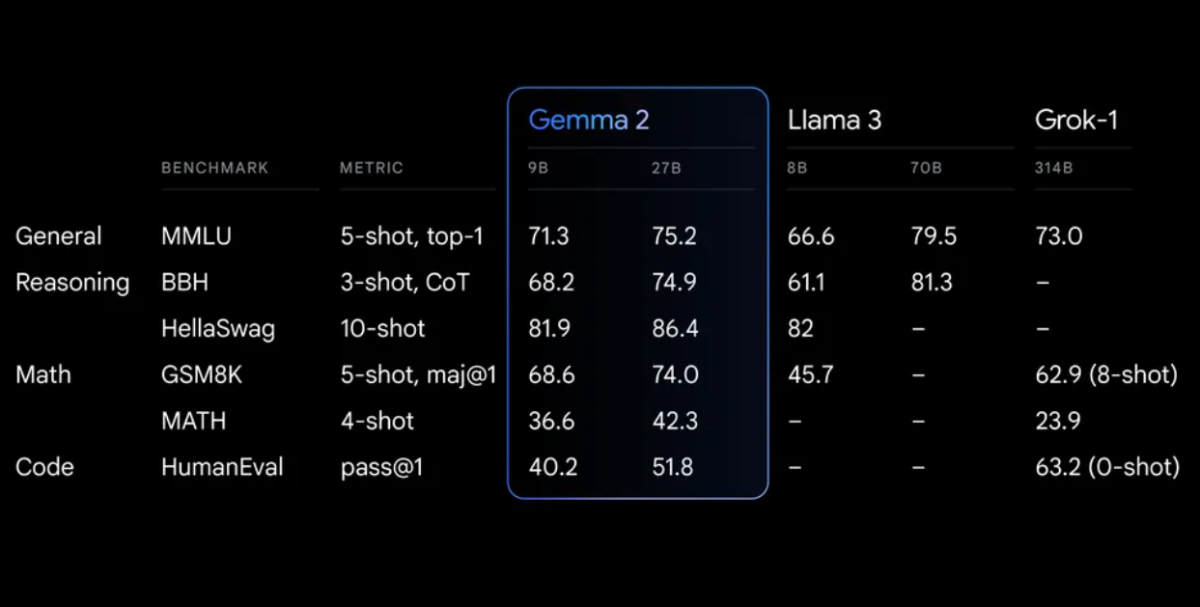
Gemma 2 on a redesigned architecture, engineered for both exceptional performance and inference efficiency
Gemma 2の使用を開始する
プロジェクトでGemma 2を使用するには、複数のオプションがあります。
1. Google AI Studio
ハードウェア要件なしで迅速に実験するには、Google AI Studioを介してGemma 2にアクセスできます。
2. Hugging Face Transformers
Gemma 2は、人気のあるHugging Face Transformersライブラリと統合されています。ここでは、どのように使用できるかを示します。
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # モデルとトークナイザーを読み込む model_name = "google/gemma-2-27b-it" # または「google/gemma-2-9b-it」より小さいバージョン tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # 入力を準備する prompt = "量子エンタングルメントの概念を簡単に説明してください。" inputs = tokenizer(prompt, return_tensors="pt") # テキストを生成する outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
TensorFlowユーザーの場合、Gemma 2はKerasを介して利用できます。
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# モデルを読み込む
model = GemmaCausalLM.from_preset("gemma_2b_en")
# テキストを生成する
prompt = "量子エンタングルメントの概念を簡単に説明してください。"
output = model.generate(prompt, max_length=200)
print(output)
高度な使用法: Gemma 2を使用したローカルRAGシステムの構築
Gemma 2の1つの強力な応用例は、検索による生成(RAG)システムの構築です。ここでは、Gemma 2とNomic埋め込みを使用したシンプルな完全ローカルRAGシステムを作成します。
ステップ1: 環境の設定
まず、必要なライブラリがインストールされていることを確認します。
pip install langchain ollama nomic chromadb
ステップ2: ドキュメントのインデックス作成
ドキュメントを処理するインデクサーを作成します。
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings












