Intelligenza Artificiale
Zero123++: una singola immagine per un modello base di diffusione multivista coerente

Negli ultimi anni si è assistito a un rapido progresso nelle prestazioni, nell’efficienza e nelle capacità generative dei romanzi emergenti Modelli generativi dell'intelligenza artificiale che sfruttano estesi set di dati e pratiche di generazione di diffusione 2D. Oggi, i modelli di intelligenza artificiale generativa sono estremamente capaci di generare diverse forme di contenuti multimediali 2D e, in una certa misura, 3D, inclusi testo, immagini, video, GIF e altro ancora.
In questo articolo parleremo del framework Zero123++, un modello di intelligenza artificiale generativa a diffusione condizionata dell'immagine con l'obiettivo di generare immagini a vista multipla coerenti in 3D utilizzando un input a vista singola. Per massimizzare il vantaggio ottenuto dai precedenti modelli generativi preaddestrati, il framework Zero123++ implementa numerosi schemi di training e condizionamento per ridurre al minimo lo sforzo necessario per mettere a punto i modelli di immagini di diffusione standard. Approfondiremo l'architettura, il funzionamento e i risultati del framework Zero123++ e analizzeremo le sue capacità di generare immagini a visualizzazione multipla coerenti di alta qualità da una singola immagine. Quindi iniziamo.
Zero123 e Zero123++: un'introduzione
Il framework Zero123++ è un modello di intelligenza artificiale generativa a diffusione condizionata dalle immagini che mira a generare immagini multi-view coerenti con il 3D utilizzando un singolo input di visualizzazione. Il framework Zero123++ è una continuazione del framework Zero123 o Zero-1-to-3 che sfrutta la nuova tecnica di sintesi delle immagini a vista zero-shot per avviare conversioni open source da immagine singola a 3D. Sebbene il framework Zero123++ offra prestazioni promettenti, le immagini generate dal framework presentano evidenti incoerenze geometriche, e questo è il motivo principale per cui persiste il divario tra scene 3D e immagini multi-view.
Il framework Zero-1-to-3 funge da base per numerosi altri framework tra cui SyncDreamer, One-2-3-45, Consistent123 e altri che aggiungono livelli aggiuntivi al framework Zero123 per ottenere risultati più coerenti durante la generazione di immagini 3D. Altri framework come ProlificDreamer, DreamFusion, DreamGaussian e altri seguono un approccio basato sull'ottimizzazione per ottenere immagini 3D distillando un'immagine 3D da vari modelli incoerenti. Sebbene queste tecniche siano efficaci e generino immagini 3D soddisfacenti, i risultati potrebbero essere migliorati con l'implementazione di un modello di diffusione di base in grado di generare immagini multi-vista in modo coerente. Di conseguenza, il framework Zero123++ porta da Zero-1 a-3 e mette a punto un nuovo modello di diffusione di base multi-vista di Stable Diffusion.
Nel quadro zero-1-3, ogni nuova vista viene generata in modo indipendente e questo approccio porta a incoerenze tra le viste generate poiché i modelli di diffusione hanno una natura di campionamento. Per affrontare questo problema, il framework Zero123++ adotta un approccio di layout a piastrellatura, con l'oggetto circondato da sei viste in un'unica immagine, e garantisce la modellazione corretta per la distribuzione congiunta delle immagini multi-vista di un oggetto.
Un'altra grande sfida affrontata dagli sviluppatori che lavorano sul framework Zero-1-to-3 è che sottoutilizza le capacità offerte da Diffusione stabile ciò alla fine porta a inefficienza e costi aggiuntivi. Esistono due ragioni principali per cui il framework Zero-1-to-3 non può massimizzare le capacità offerte da Stable Diffusion
- Durante l'addestramento con le condizioni dell'immagine, il framework Zero-1-to-3 non incorpora in modo efficace i meccanismi di condizionamento locale o globale offerti da Stable Diffusion.
- Durante l'addestramento, il framework Zero-1-to-3 utilizza una risoluzione ridotta, un approccio in cui la risoluzione di output viene ridotta al di sotto della risoluzione di addestramento che può ridurre la qualità della generazione dell'immagine per i modelli a diffusione stabile.
Per affrontare questi problemi, il framework Zero123++ implementa una serie di tecniche di condizionamento che massimizzano l'utilizzo delle risorse offerte da Stable Diffusion e mantengono la qualità della generazione di immagini per i modelli Stable Diffusion.
Migliorare il condizionamento e le consistenze
Nel tentativo di migliorare il condizionamento dell'immagine e la coerenza dell'immagine multi-vista, il framework Zero123++ ha implementato diverse tecniche, con l'obiettivo primario di riutilizzare le tecniche precedenti provenienti dal modello Stable Diffusion pre-addestrato.
Generazione multivista
La qualità indispensabile per generare immagini multi-vista coerenti risiede nel modellare correttamente la distribuzione congiunta di più immagini. Nel framework Zero-1-to-3, la correlazione tra immagini multi-vista viene ignorata perché per ogni immagine il framework modella la distribuzione marginale condizionale in modo indipendente e separato. Tuttavia, nel framework Zero123++, gli sviluppatori hanno optato per un approccio di layout affiancato che affianca 6 immagini in un singolo fotogramma/immagine per una generazione multi-vista coerente e il processo è dimostrato nell'immagine seguente.
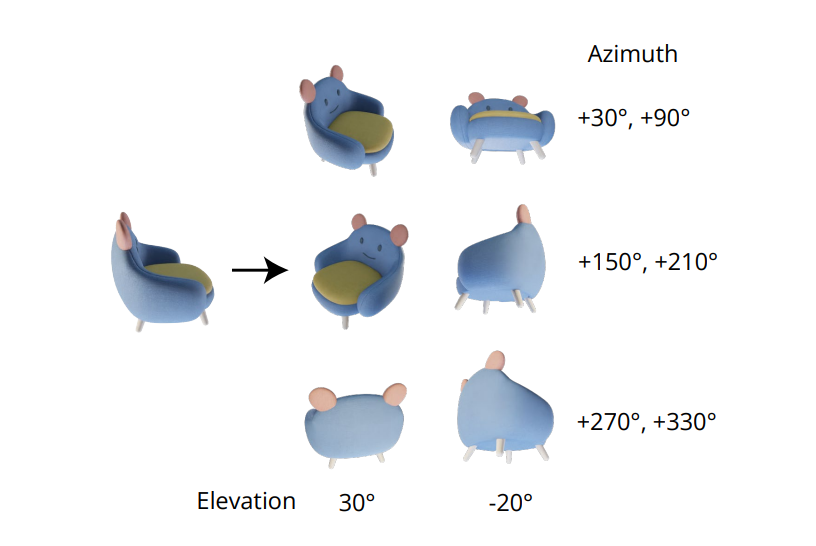

Inoltre, è stato notato che gli orientamenti degli oggetti tendono a disambiguare durante l'addestramento del modello sulle pose della fotocamera e, per evitare questa disambiguazione, il framework da zero a 1 addestra le pose della fotocamera con angoli di elevazione e azimut relativo all'input. Per implementare questo approccio, è necessario conoscere l'angolo di elevazione della vista dell'input che viene poi utilizzato per determinare la posa relativa tra le nuove viste dell'input. Nel tentativo di conoscere questo angolo di elevazione, i framework spesso aggiungono un modulo di stima dell'elevazione e questo approccio spesso comporta il costo di ulteriori errori in fase di elaborazione.
Programma del rumore
Programma lineare in scala, il programma del rumore originale per la diffusione stabile si concentra principalmente sui dettagli locali, ma come si può vedere nell'immagine seguente, ha pochissimi passaggi con SNR o rapporto segnale-rumore inferiore.


Questi passaggi di basso rapporto segnale-rumore si verificano nelle prime fasi della fase di denoising, una fase cruciale per determinare la struttura globale a bassa frequenza. La riduzione del numero di passaggi durante la fase di denoising, sia durante l'interferenza che durante l'addestramento, spesso comporta una maggiore variazione strutturale. Sebbene questa configurazione sia ideale per la generazione di immagini singole, limita la capacità del framework di garantire coerenza globale tra visualizzazioni diverse. Per superare questo ostacolo, il framework Zero123++ mette a punto un modello LoRA sul framework di previsione v Stable Diffusion 2 per eseguire un'attività giocattolo e i risultati sono illustrati di seguito.

Con il programma di rumore lineare in scala, il modello LoRA non si adatta eccessivamente, ma sbianca solo leggermente l'immagine. Al contrario, quando si lavora con la pianificazione del rumore lineare, il framework LoRA genera con successo un'immagine vuota indipendentemente dalla richiesta di input, indicando così l'impatto della pianificazione del rumore sulla capacità del framework di adattarsi ai nuovi requisiti a livello globale.
Attenzione di riferimento in scala per le condizioni locali
L'input della visualizzazione singola o le immagini di condizionamento nel framework da zero a 1 sono concatenati con gli input disturbati nella dimensione della caratteristica da disturbare per il condizionamento dell'immagine.
Questa concatenazione porta a una corrispondenza spaziale errata in termini di pixel tra l'immagine di destinazione e l'input. Per fornire un input di condizionamento locale adeguato, il framework Zero123++ fa uso di un'attenzione di riferimento in scala, un approccio in cui l'esecuzione di un modello UNet di denoising viene indirizzata su un'immagine di riferimento aggiuntiva, seguita dall'aggiunta di matrici di valori e chiave di auto-attenzione dal riferimento immagine ai rispettivi livelli di attenzione quando l'input del modello viene denoizzato, ed è dimostrato nella figura seguente.

L'approccio dell'attenzione di riferimento è in grado di guidare il modello di diffusione per generare immagini che condividono una trama simile con l'immagine di riferimento e il contenuto semantico senza alcuna messa a punto. Con la messa a punto, l'approccio dell'attenzione di riferimento fornisce risultati superiori con il ridimensionamento del latente.

Condizionamento globale: FlexDiffuse
Nell'approccio originale di Stable Diffusion, gli incorporamenti di testo sono l'unica fonte per gli incorporamenti globali e l'approccio utilizza il framework CLIP come codificatore di testo per eseguire esami incrociati tra gli incorporamenti di testo e i latenti del modello. Di conseguenza, gli sviluppatori sono liberi di utilizzare l'allineamento tra gli spazi di testo e le immagini CLIP risultanti per utilizzarlo per condizionamenti globali dell'immagine.
Il framework Zero123++ propone di utilizzare una variante addestrabile del meccanismo di guida lineare per incorporare il condizionamento globale dell'immagine nel framework con un minimo di ritocchi necessario, e i risultati sono illustrati nell'immagine seguente. Come si può vedere, senza la presenza di un condizionamento globale dell'immagine, la qualità del contenuto generato dal framework è soddisfacente per le regioni visibili che corrispondono all'immagine di input. Tuttavia, la qualità dell'immagine generata dal framework per le regioni non visibili subisce un significativo deterioramento, dovuto principalmente all'incapacità del modello di dedurre la semantica globale dell'oggetto.

Architettura di modello
Il framework Zero123++ viene addestrato con il modello Stable Diffusion 2v come base utilizzando i diversi approcci e tecniche menzionati nell'articolo. Il framework Zero123++ è pre-addestrato sul set di dati Objaverse di cui viene eseguito il rendering con illuminazione HDRI casuale. Il framework adotta inoltre l'approccio del programma di formazione a fasi utilizzato nel framework Stable Diffusion Image Variations nel tentativo di ridurre ulteriormente al minimo la quantità di messa a punto richiesta e preservare il più possibile la precedente Stable Diffusion.
Il funzionamento o l'architettura del framework Zero123++ può essere ulteriormente suddiviso in passaggi o fasi sequenziali. La prima fase vede il framework mettere a punto le matrici KV degli strati di attenzione incrociata e gli strati di autoattenzione di Diffusione Stabile con AdamW come ottimizzatore, 1000 passaggi di riscaldamento e il programma del tasso di apprendimento del coseno massimizzato a 7×10-5. Nella seconda fase, il quadro impiega un tasso di apprendimento costante altamente conservativo con 2000 serie di riscaldamento e impiega l'approccio Min-SNR per massimizzare l'efficienza durante l'allenamento.
Zero123++: risultati e confronto delle prestazioni
Prestazioni qualitative
Per valutare le prestazioni del framework Zero123++ sulla base della qualità generata, viene confrontato con SyncDreamer e Zero-1-to-3-XL, due dei migliori framework all'avanguardia per la generazione di contenuti. I framework vengono confrontati con quattro immagini di input con ambito diverso. La prima immagine è un gatto giocattolo elettrico, preso direttamente dal set di dati Objaverse, e vanta una grande incertezza sulla parte posteriore dell'oggetto. La seconda è l'immagine di un estintore e la terza è l'immagine di un cane seduto su un razzo, generata dal modello SDXL. L'immagine finale è un'illustrazione dell'anime. I passaggi di elevazione richiesti per i framework vengono ottenuti utilizzando il metodo di stima dell'elevazione del framework One-2-3-4-5 e la rimozione dello sfondo viene ottenuta utilizzando il framework SAM. Come si può vedere, il framework Zero123++ genera immagini multi-view di alta qualità in modo coerente ed è in grado di generalizzare altrettanto bene all'illustrazione 2D fuori dominio e alle immagini generate dall'intelligenza artificiale.


Analisi quantitativa
Per confrontare quantitativamente il framework Zero123++ con i framework Zero-1-to-3 e Zero-1to-3 XL all'avanguardia, gli sviluppatori valutano il punteggio LPIPS (Learn Perceptual Image Patch Similarity) di questi modelli sui dati suddivisi di convalida, un sottoinsieme del set di dati Objaverse. Per valutare le prestazioni del modello sulla generazione di immagini multi-vista, gli sviluppatori affiancano rispettivamente le immagini di riferimento di base e le 6 immagini generate, quindi calcolano il punteggio LPIPS (Learn Perceptual Image Patch Similarity). I risultati sono mostrati di seguito e, come si può vedere chiaramente, il framework Zero123++ raggiunge le migliori prestazioni sullo split set di validazione.

Testo per la valutazione multi-vista
Per valutare la capacità del framework Zero123++ nella generazione di contenuti da testo a multivista, gli sviluppatori utilizzano prima il framework SDXL con istruzioni di testo per generare un'immagine, quindi utilizzano il framework Zero123++ per l'immagine generata. I risultati sono mostrati nell'immagine seguente e, come si può vedere, rispetto al framework Zero-1-to-3 che non può garantire una generazione multi-view coerente, il framework Zero123++ restituisce multi-view coerenti, realistici e altamente dettagliati. visualizzare le immagini implementando il file da testo a immagine a visualizzazione multipla approccio o pipeline.

Zero123++ Rete di controllo della profondità
Oltre al framework Zero123++ di base, gli sviluppatori hanno rilasciato anche Depth ControlNet Zero123++, una versione con controllo della profondità del framework originale costruita utilizzando l'architettura ControlNet. Le immagini lineari normalizzate vengono renderizzate rispetto alle successive immagini RGB e un framework ControlNet viene addestrato per controllare la geometria del framework Zero123++ utilizzando la percezione della profondità.


Conclusione
In questo articolo abbiamo parlato di Zero123++, un modello di intelligenza artificiale generativa a diffusione condizionata dell'immagine con l'obiettivo di generare immagini a vista multipla coerenti in 3D utilizzando un unico input di visualizzazione. Per massimizzare il vantaggio ottenuto dai precedenti modelli generativi preaddestrati, il framework Zero123++ implementa numerosi schemi di training e condizionamento per ridurre al minimo lo sforzo necessario per mettere a punto i modelli di immagini di diffusione standard. Abbiamo anche discusso i diversi approcci e miglioramenti implementati dal framework Zero123++ che lo aiutano a raggiungere risultati paragonabili e addirittura superiori a quelli raggiunti dagli attuali framework all'avanguardia.
Tuttavia, nonostante la sua efficienza e la capacità di generare immagini multi-visione di alta qualità in modo coerente, il framework Zero123++ ha ancora un certo margine di miglioramento, con potenziali aree di ricerca che rappresentano
- Modello di raffinazione a due stadi ciò potrebbe risolvere l'incapacità di Zero123++ di soddisfare i requisiti globali di coerenza.
- Ulteriori scale-up per migliorare ulteriormente la capacità di Zero123++ di generare immagini di qualità ancora superiore.
