Intelligenza artificiale
I Pericoli dell’Utilizzo di Citazioni per Autenticare il Contenuto NLG

Opinione I modelli di Generazione di Linguaggio Naturale come GPT-3 sono propensi a ‘hallucinare’ materiale che presentano nel contesto di informazioni fattuali. In un’era che è straordinariamente preoccupata per la crescita delle notizie false basate su testo, questi ‘voli di fantasia’ rappresentano un ostacolo esistenziale per lo sviluppo di sistemi di scrittura e riassunto automatizzati e per il futuro del giornalismo guidato da AI, tra gli altri sottosettori dell’Elaborazione del Linguaggio Naturale (NLP).
Il problema centrale è che i modelli di linguaggio di stile GPT derivano caratteristiche e classi chiave da grandi corpora di testi di training, e imparano a utilizzare queste caratteristiche come blocchi costitutivi del linguaggio in modo abile e autentico, indipendentemente dall’accuratezza del contenuto generato, o anche dalla sua accettabilità.
I sistemi NLG si affidano quindi attualmente alla verifica umana dei fatti in uno di due approcci: che i modelli siano utilizzati come generatori di testo iniziali che vengono immediatamente passati agli utenti umani, per la verifica o per qualche altra forma di editing o adattamento; o che gli esseri umani siano utilizzati come filtri costosi per migliorare la qualità dei set di dati destinati a informare modelli meno astratti e ‘creativi’ (che in sé sono inevitabilmente ancora difficili da fidarsi in termini di accuratezza fattuale, e che richiederanno ulteriori livelli di supervisione umana).
Vecchie Notizie e Fatti Falsi
I modelli di Generazione di Linguaggio Naturale (NLG) sono in grado di produrre output convincenti e plausibili perché hanno appreso l’architettura semantica, piuttosto che assimilare in modo più astratto la storia reale, la scienza, l’economia o qualsiasi altro argomento su cui potrebbero essere richiesti di esprimersi, che sono effettivamente intrecciati come ‘passeggeri’ nei dati sorgente.
L’accuratezza fattuale delle informazioni che i modelli NLG generano presume che l’input su cui sono addestrati sia in sé affidabile e aggiornato, il che presenta un onere straordinario in termini di pre-elaborazione e ulteriore verifica umana – un ostacolo costoso che il settore della ricerca NLP sta attualmente affrontando su molti fronti.
I sistemi di scala GPT-3 richiedono un tempo e un denaro straordinari per l’addestramento, e una volta addestrati, sono difficili da aggiornare a livello di ‘nucleo’. Sebbene le modifiche locali basate su sessione e utente possano aumentare l’utilità e l’accuratezza dei modelli implementati, questi benefici utili sono difficili, a volte impossibili da riportare al modello di base senza richiedere un riaddestramento completo o parziale.
Per questo motivo, è difficile creare modelli di linguaggio addestrati che possano utilizzare le informazioni più recenti.

Addestrato prima ancora dell’avvento di COVID, text-davinci-002 – l’iterazione di GPT-3 considerata ‘più capace’ dal suo creatore OpenAI – può elaborare 4000 token per richiesta, ma non sa nulla di COVID-19 o dell’invasione ucraina del 2022 (questi prompt e risposte sono del 5 aprile 2022). È interessante notare che ‘sconosciuto’ è in realtà una risposta accettabile in entrambi i casi di fallimento, ma ulteriori prompt stabiliscono facilmente che GPT-3 è all’oscuro di questi eventi. Fonte: https://beta.openai.com/playground
Un modello addestrato può accedere solo alle ‘verità’ che ha internalizzato durante l’addestramento, ed è difficile ottenere una citazione precisa e pertinente per impostazione predefinita, quando si tenta di far verificare le affermazioni del modello. Il pericolo reale di ottenere citazioni dal GPT-3 predefinito (ad esempio) è che a volte produce citazioni corrette, portando a una falsa fiducia in questo aspetto delle sue capacità:

In alto, tre citazioni accurate ottenute dal GPT-3 dell’era 2021. Al centro, GPT-3 non riesce a citare una delle citazioni più famose di Einstein ("Dio non gioca a dadi con l’universo"), nonostante un prompt non criptico. In basso, GPT-3 assegna una citazione scandalosa e fittizia ad Albert Einstein, apparentemente un’espansione da domande su Winston Churchill nella stessa sessione. Fonte: L’articolo dell’autore del 2021 su https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
Nella speranza di affrontare questo difetto generale nei modelli NLG, Google’s DeepMind ha recentemente proposto GopherCite, un modello da 280 miliardi di parametri in grado di citare prove specifiche e accurate a sostegno delle risposte generate ai prompt.



Tre esempi di GopherCite che sostengono le sue affermazioni con citazioni reali. Fonte: https://arxiv.org/pdf/2203.11147.pdf
GopherCite sfrutta l’apprendimento per rinforzo dalle preferenze umane (RLHP) per addestrare modelli di query in grado di citare citazioni reali come prove a sostegno. Le citazioni sono tratte in tempo reale da più fonti di documenti ottenute dai motori di ricerca o da un documento specifico fornito dall’utente.
Le prestazioni di GopherCite sono state misurate attraverso la valutazione umana delle risposte del modello, che sono state trovate di ‘alta qualità’ l’80% delle volte nel set di dati NaturalQuestions di Google, e il 67% delle volte nel set di dati ELI5.
Citare Falsità
Tuttavia, quando testato contro il benchmark TruthfulQA dell’Università di Oxford, le risposte di GopherCite sono state raramente valutate come veritiere, in confronto alle risposte ‘corrette’ curate dagli esseri umani.
Gli autori suggeriscono che ciò è dovuto al fatto che il concetto di ‘risposte supportate’ non aiuta in alcun modo a definire la verità in sé, poiché l’utilità delle citazioni di fonti può essere compromessa da altri fattori, come la possibilità che l’autore della citazione stia ‘hallucinando’ (ad esempio, scrivendo di mondi fittizi, producendo contenuti pubblicitari o altrimenti fantasticando materiali non autentici.



Casi di GopherCite in cui la plausibilità non equivale necessariamente alla ‘verità’.
In effetti, diventa necessario distinguere tra ‘supportato’ e ‘vero’ in tali casi. La cultura umana è attualmente molto più avanti della tecnologia dell’apprendimento automatico nell’utilizzo di metodologie e framework progettati per ottenere definizioni oggettive di verità, e anche lì, lo stato nativo di ‘verità importante’ sembra essere contenzioso e negazione marginale.
Il problema è ricorsivo negli architetture NLG che cercano di elaborare meccanismi di ‘corroborazione’ definitivi: il consenso umano guidato è utilizzato come benchmark di verità attraverso modelli di tipo AMT, dove gli valutatori umani (e gli altri esseri umani che mediano le dispute tra loro) sono in sé parziali e distorti.
Ad esempio, gli esperimenti iniziali di GopherCite utilizzano un modello di ‘super-rater’ per scegliere i migliori soggetti umani per valutare l’output del modello, selezionando solo quei valutatori che hanno ottenuto almeno l’85% in confronto a un set di assicurazione della qualità. Infine, 113 super-rater sono stati selezionati per il compito.
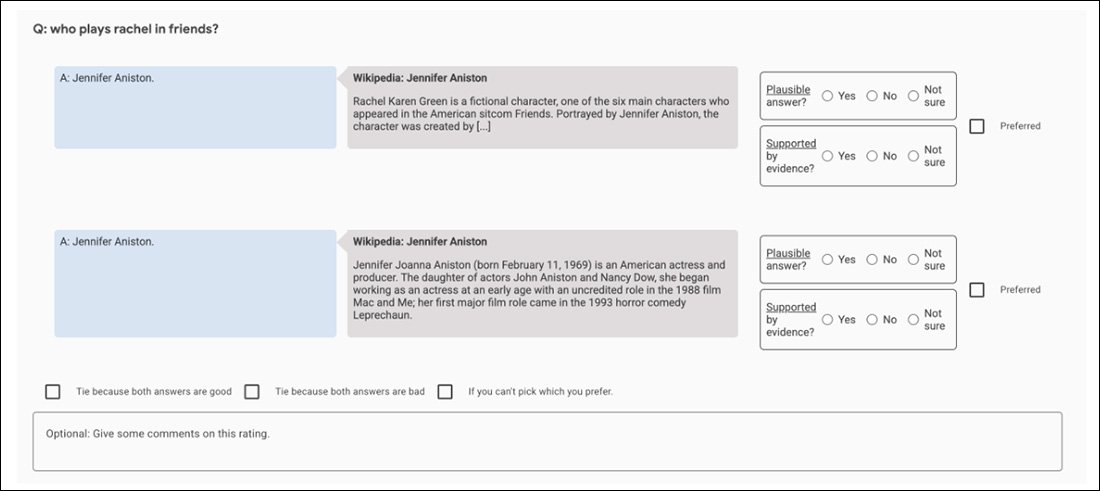
Screenshot dell’app di confronto utilizzata per aiutare a valutare l’output di GopherCite.
Sostenibilmente, questo è un quadro perfetto di un’inseguimento frattale senza fine: il set di assicurazione della qualità utilizzato per valutare i valutatori è in sé un altro ‘metrica di verità definita dall’uomo’, come è il set TruthfulQA di Oxford contro cui GopherCite è stato trovato carente.
In termini di contenuto supportato e ‘autenticato’, tutto ciò che i sistemi NLG possono sperare di sintetizzare dall’addestramento sui dati umani è la disparità e la diversità umana, in sé un problema mal posto e irrisolto. Abbiamo una tendenza innata a citare fonti che supportano le nostre prospettive e a parlare in modo autorevole e con convinzione in casi in cui le nostre informazioni di fonte possono essere obsolete, completamente inaccurate o altrimenti rappresentate in modo non autentico; e una disposizione a diffondere queste prospettive direttamente nel mondo, a una scala e a un’efficacia senza precedenti, direttamente nel percorso dei framework di raccolta delle conoscenze che alimentano nuovi framework NLG.
Pertanto, il pericolo insito nello sviluppo di sistemi NLG supportati da citazioni sembra legato alla natura imprevedibile del materiale di origine. Qualsiasi meccanismo (come la citazione diretta e le citazioni) che aumenta la fiducia dell’utente nell’output NLG è, allo stato attuale dell’arte, pericolosamente aggiunto all’autenticità, ma non alla veridicità dell’output.
Tali tecniche saranno probabilmente utili quando l’NLP ricreerà finalmente i ‘caleidoscopi’ della scrittura di finzione di Orwell in Novecento84; ma rappresentano un’inseguimento pericoloso per l’analisi dei documenti obiettivi, il giornalismo guidato da AI e altre possibili applicazioni ‘non di finzione’ della generazione e del riassunto del testo guidato o spontaneo.
Pubblicato per la prima volta il 5 aprile 2022. Aggiornato alle 15:29 EET per correggere il termine.












