Intelligenza Artificiale
Potenziamento di modelli linguistici di grandi dimensioni con previsione multi-token
By
Ayush Mittal Mittale
Grandi modelli linguistici (LLM) come GPT, LLaMA e altri hanno preso d'assalto il mondo con la loro straordinaria capacità di comprendere e generare testo simile a quello umano. Tuttavia, nonostante le loro impressionanti capacità, il metodo standard di addestramento di questi modelli, noto come “previsione del token successivo”, presenta alcune limitazioni intrinseche.
Nella previsione del token successivo, il modello viene addestrato a prevedere la parola successiva in una sequenza date le parole precedenti. Sebbene questo approccio si sia dimostrato efficace, può portare a modelli che lottano con dipendenze a lungo termine e compiti di ragionamento complessi. Inoltre, la discrepanza tra il regime di formazione forzata dell’insegnante e il processo di generazione autoregressiva durante l’inferenza può comportare prestazioni non ottimali.
Un recente articolo di ricerca di Gloeckle et al. (2024) da Meta AI introduce un nuovo paradigma di formazione chiamato “previsione multi-token" che mira ad affrontare queste limitazioni e a potenziare i modelli linguistici di grandi dimensioni. In questo articolo del blog, approfondiremo i concetti chiave, i dettagli tecnici e le potenziali implicazioni di questa ricerca innovativa.
Predizione a token singolo: l'approccio convenzionale
Prima di addentrarci nei dettagli della previsione multi-token, è essenziale comprendere l'approccio convenzionale che è stato adottato cavallo di battaglia del grande modello linguistico formazione per anni: previsione del token singolo, nota anche come previsione del token successivo.
Il paradigma di previsione del token successivo
Nel paradigma di previsione del token successivo, i modelli linguistici vengono addestrati a prevedere la parola successiva in una sequenza dato il contesto precedente. Più formalmente, il modello ha il compito di massimizzare la probabilità del prossimo token xt+1, dati i token precedenti x1, x2, …, xt. Questo viene tipicamente fatto minimizzando la perdita di entropia incrociata:
L = -Σt log P(xt+1 | x1, x2, …, xt)
Questo obiettivo formativo semplice ma potente è stato il fondamento di molti modelli linguistici di successo, come GPT (Radford et al., 2018), BERT (Devlin et al., 2019) e le loro varianti.
Forzatura dell'insegnante e generazione autoregressiva
La previsione del token successivo si basa su una tecnica di training chiamata “insegnante che costringe" in cui al modello viene fornita la verità fondamentale per ogni token futuro durante l'addestramento. Ciò consente al modello di apprendere dal contesto corretto e dalle sequenze target, facilitando un addestramento più stabile ed efficiente.
Tuttavia, durante l'inferenza o la generazione, il modello opera in modo autoregressivo, prevedendo un token alla volta in base ai token precedentemente generati. Questa discrepanza tra il regime di formazione (forzatura dell'insegnante) e il regime di inferenza (generazione autoregressiva) può portare a potenziali discrepanze e prestazioni non ottimali, soprattutto per sequenze più lunghe o compiti di ragionamento complessi.
Limitazioni della previsione del token successivo
Sebbene la previsione del token successivo abbia avuto un notevole successo, presenta anche alcune limitazioni intrinseche:
- Focus a breve termine: Predicendo solo il token successivo, il modello potrebbe avere difficoltà a catturare le dipendenze a lungo termine e la struttura complessiva e la coerenza del testo, portando potenzialmente a incoerenze o generazioni incoerenti.
- Blocco del modello locale: I modelli di previsione del token successivo possono agganciarsi a modelli locali nei dati di addestramento, rendendo difficile la generalizzazione a scenari o attività fuori distribuzione che richiedono un ragionamento più astratto.
- Capacità di ragionamento: Per compiti che coinvolgono ragionamento in più fasi, pensiero algoritmico o operazioni logiche complesse, la previsione del token successivo potrebbe non fornire pregiudizi o rappresentazioni induttive sufficienti per supportare tali capacità in modo efficace.
- Inefficienza del campione: A causa della natura locale della previsione del token successivo, i modelli potrebbero richiedere set di dati di addestramento più ampi per acquisire le conoscenze e le capacità di ragionamento necessarie, portando a potenziali inefficienze del campione.
Queste limitazioni hanno motivato i ricercatori a esplorare paradigmi di formazione alternativi, come la previsione multi-token, che mira a risolvere alcune di queste carenze e sbloccare nuove capacità per modelli linguistici di grandi dimensioni.
Confrontando l’approccio convenzionale di previsione del token successivo con la nuova tecnica di previsione multi-token, i lettori possono apprezzare meglio la motivazione e i potenziali benefici di quest’ultima, ponendo le basi per un’esplorazione più approfondita di questa ricerca innovativa.
Cos'è la previsione multi-token?
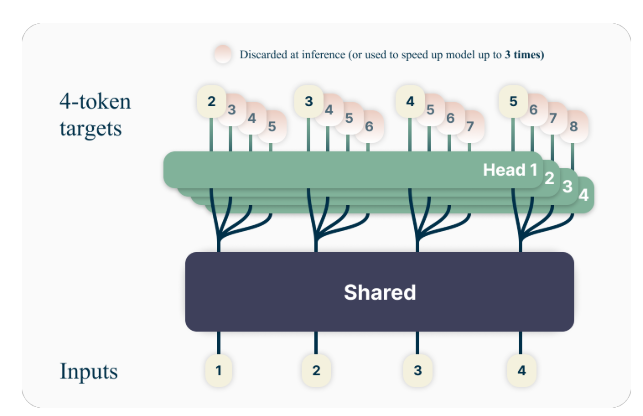
L’idea chiave alla base della previsione multi-token è quella di addestrare i modelli linguistici a prevedere più token futuri contemporaneamente, anziché solo il token successivo. Nello specifico, durante l'addestramento, il modello ha il compito di prevedere i successivi n token in ciascuna posizione nel corpo di addestramento, utilizzando n teste di output indipendenti che operano su un trunk del modello condiviso.
Ad esempio, con una configurazione di previsione a 4 token, il modello verrebbe addestrato a prevedere i successivi 4 token contemporaneamente, dato il contesto precedente. Questo approccio incoraggia il modello a catturare dipendenze a lungo termine e a sviluppare una migliore comprensione della struttura complessiva e della coerenza del testo.
Un esempio di giocattolo
Per comprendere meglio il concetto di previsione multi-token, consideriamo un semplice esempio. Supponiamo di avere la seguente frase:
"La veloce volpe marrone salta sopra il cane pigro."
Nell'approccio standard di previsione del token successivo, il modello verrebbe addestrato a prevedere la parola successiva dato il contesto precedente. Ad esempio, dato il contesto “La veloce volpe marrone salta sopra”, il modello avrebbe il compito di prevedere la parola successiva, “pigro”.
Con la previsione multi-token, tuttavia, il modello verrebbe addestrato a prevedere più parole future contemporaneamente. Ad esempio, se impostiamo n=4, il modello verrebbe addestrato a prevedere le successive 4 parole simultaneamente. Dato lo stesso contesto "La veloce volpe marrone salta sopra", il modello avrebbe il compito di prevedere la sequenza "cane pigro". (Notare lo spazio dopo “cane” per indicare la fine della frase).
Addestrando il modello a prevedere più token futuri contemporaneamente, si incoraggia a catturare le dipendenze a lungo termine e a sviluppare una migliore comprensione della struttura complessiva e della coerenza del testo.
Dettagli tecnici
Gli autori propongono un'architettura semplice ma efficace per implementare la previsione multi-token. Il modello è costituito da un tronco trasformatore condiviso che produce una rappresentazione latente del contesto di input, seguito da n strati di trasformatore indipendenti (teste di uscita) che prevedono i rispettivi token futuri.
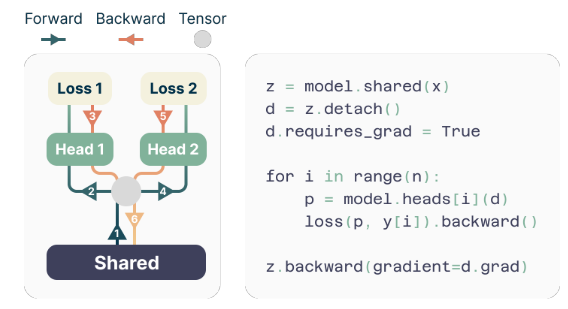
Durante l'addestramento, i passaggi avanti e indietro vengono attentamente orchestrati per ridurre al minimo l'ingombro della memoria della GPU. Il tronco condiviso calcola la rappresentazione latente, quindi ciascuna testa di uscita esegue sequenzialmente il suo passaggio in avanti e all'indietro, accumulando gradienti a livello del tronco. Questo approccio evita di materializzare simultaneamente tutti i vettori logit e i relativi gradienti, riducendo il picco di utilizzo della memoria della GPU O(nV+d) a O(V + d)Durante la serata, V Europe è dimensione del vocabolario e d Europe è dimensione della rappresentazione latente.
L'implementazione efficiente in termini di memoria
Una delle sfide nell'addestramento dei predittori multi-token è la riduzione dell'utilizzo della memoria della GPU. Dal momento che dimensione del vocabolario (V) è in genere molto più grande di dimensione della rappresentazione latente (D), i vettori logit diventano il collo di bottiglia nell'utilizzo della memoria della GPU.
Per affrontare questa sfida, gli autori propongono un'implementazione efficiente in termini di memoria che adatta attentamente la sequenza delle operazioni avanti e indietro. Invece di materializzare simultaneamente tutti i logit e i relativi gradienti, l’implementazione calcola in sequenza i passaggi in avanti e all’indietro per ciascuna testa di output indipendente, accumulando i gradienti a livello del trunk.
Questo approccio evita di archiviare simultaneamente tutti i vettori logit e i relativi gradienti in memoria, riducendo il picco di utilizzo della memoria della GPU O(nV+d) a O(V + d)Durante la serata, n è il numero di token futuri previsti.
Vantaggi della previsione multi-token
Il documento di ricerca presenta numerosi vantaggi interessanti derivanti dall'utilizzo della previsione multi-token per l'addestramento di modelli linguistici di grandi dimensioni:
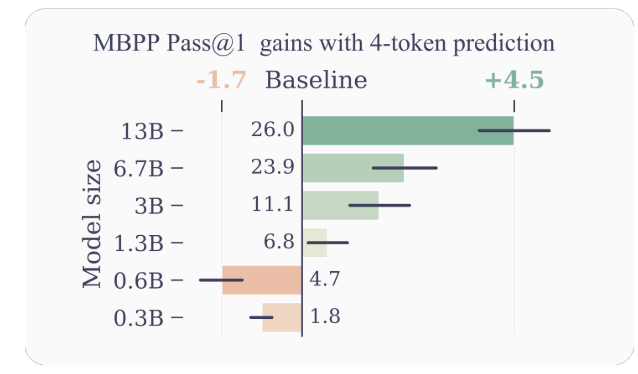
- Miglioramento dell'efficienza del campione: Incoraggiando il modello a prevedere più token futuri contemporaneamente, la previsione multi-token guida il modello verso una migliore efficienza del campione. Gli autori dimostrano miglioramenti significativi nelle prestazioni nelle attività di comprensione e generazione del codice, con modelli fino a 13B parametri che risolvono in media circa il 15% in più di problemi.
- Inferenza più veloce: Le teste di output aggiuntive addestrate con la previsione multi-token possono essere sfruttate per la decodifica auto-speculativa, una variante della decodifica speculativa che consente la previsione parallela dei token. Ciò si traduce in tempi di inferenza fino a 3 volte più rapidi su un'ampia gamma di dimensioni batch, anche per modelli di grandi dimensioni.
- Promozione delle dipendenze a lungo termine: la previsione multi-token incoraggia il modello a catturare dipendenze e modelli a lungo termine nei dati, il che è particolarmente utile per le attività che richiedono comprensione e ragionamento in contesti più ampi.
- Ragionamento algoritmico: Gli autori presentano esperimenti su compiti sintetici che dimostrano la superiorità dei modelli di previsione multi-token nello sviluppo di teste di induzione e capacità di ragionamento algoritmico, soprattutto per modelli di dimensioni più piccole.
- Coerenza e coerenza: Addestrando il modello a prevedere più token futuri contemporaneamente, la previsione multi-token incoraggia lo sviluppo di rappresentazioni coerenti e consistenti. Ciò è particolarmente utile per le attività che richiedono la generazione di testi più lunghi e coerenti, come la narrazione, la scrittura creativa o la generazione di manuali didattici.
- Generalizzazione migliorata: Gli esperimenti degli autori su compiti sintetici suggeriscono che i modelli di predizione multi-token mostrano migliori capacità di generalizzazione, soprattutto in contesti fuori distribuzione. Ciò è potenzialmente dovuto alla capacità del modello di catturare modelli e dipendenze a lungo termine, il che può aiutarlo a estrapolare in modo più efficace a scenari non osservati.

Esempi e intuizioni
Per comprendere meglio perché la previsione multi-token funziona così bene, prendiamo in considerazione alcuni esempi:
- Generazione di codice: nel contesto della generazione del codice, la previsione di più token contemporaneamente può aiutare il modello a comprendere e generare strutture di codice più complesse. Ad esempio, quando si genera una definizione di funzione, la previsione solo del token successivo potrebbe non fornire un contesto sufficiente affinché il modello possa generare correttamente l'intera firma della funzione. Tuttavia, prevedendo più token contemporaneamente, il modello può catturare meglio le dipendenze tra il nome della funzione, i parametri e il tipo restituito, portando a una generazione di codice più accurata e coerente.
- Ragionamento in linguaggio naturale: considera uno scenario in cui un modello linguistico ha il compito di rispondere a una domanda che richiede un ragionamento su più passaggi o informazioni. Prevedendo più token contemporaneamente, il modello può catturare meglio le dipendenze tra le diverse componenti del processo di ragionamento, portando a risposte più coerenti e accurate.
- Generazione di testo di lunga durata: quando si genera testo di lunga durata, come storie, articoli o rapporti, mantenere la coerenza e la coerenza per un periodo prolungato può essere difficile per i modelli linguistici addestrati con la previsione del token successivo. La previsione multi-token incoraggia il modello a sviluppare rappresentazioni che catturano la struttura complessiva e il flusso del testo, portando potenzialmente a generazioni di formato lungo più coerenti e consistenti.
Limitazioni e direzioni future
Sebbene i risultati presentati nel documento siano impressionanti, ci sono alcune limitazioni e domande aperte che meritano ulteriori indagini:
- Numero ottimale di token: L'articolo esplora diversi valori di n (il numero di token futuri da prevedere) e rileva che n=4 funziona bene per molti compiti. Tuttavia, il valore ottimale di n può dipendere dall'attività specifica, dal set di dati e dalle dimensioni del modello. Lo sviluppo di metodi basati su principi per determinare il n ottimale potrebbe portare a ulteriori miglioramenti delle prestazioni.
- Dimensione del vocabolario e tokenizzazione: Gli autori notano che la dimensione ottimale del vocabolario e la strategia di tokenizzazione per i modelli di previsione multi-token possono differire da quelli utilizzati per i modelli di previsione del token successivo. Esplorare questo aspetto potrebbe portare a migliori compromessi tra la lunghezza della sequenza compressa e l'efficienza computazionale.
- Perdite di previsione ausiliarie: Gli autori suggeriscono che il loro lavoro potrebbe stimolare l'interesse nello sviluppo di nuove perdite di previsione ausiliaria per modelli linguistici di grandi dimensioni, oltre la previsione standard del token successivo. Lo studio delle perdite ausiliarie alternative e delle loro combinazioni con la previsione multi-token rappresenta un'entusiasmante direzione di ricerca.
- Comprensione teorica: Sebbene l’articolo fornisca alcune intuizioni e prove empiriche sull’efficacia della previsione multi-token, sarebbe preziosa una comprensione teorica più approfondita del perché e del come questo approccio funziona così bene.
Conclusione
Il documento di ricerca “Better & Faster Large Language Models via Multi-token Prediction” di Gloeckle et al. introduce un nuovo paradigma di formazione che ha il potenziale per migliorare significativamente le prestazioni e le capacità di modelli linguistici di grandi dimensioni. Addestrando i modelli per prevedere più token futuri contemporaneamente, la previsione multi-token incoraggia lo sviluppo di dipendenze a lungo raggio, capacità di ragionamento algoritmico e una migliore efficienza del campione.
L'implementazione tecnica proposta dagli autori è elegante ed efficiente dal punto di vista computazionale, rendendo possibile l'applicazione di questo approccio alla formazione di modelli linguistici su larga scala. Inoltre, la capacità di sfruttare la decodifica auto-speculativa per un’inferenza più rapida rappresenta un vantaggio pratico significativo.
Sebbene vi siano ancora questioni aperte e aree da esplorare ulteriormente, questa ricerca rappresenta un entusiasmante passo avanti nel campo dei modelli linguistici di grandi dimensioni. Poiché la domanda di modelli linguistici più capaci ed efficienti continua a crescere, la previsione multi-token potrebbe diventare una componente chiave nella prossima generazione di questi potenti sistemi di intelligenza artificiale.
Ho trascorso gli ultimi cinque anni immergendomi nell'affascinante mondo del Machine Learning e del Deep Learning. La mia passione e competenza mi hanno portato a contribuire a oltre 50 diversi progetti di ingegneria del software, con un focus particolare su AI/ML. La mia continua curiosità mi ha anche attirato verso l'elaborazione del linguaggio naturale, un campo che non vedo l'ora di esplorare ulteriormente.

Ti potrebbe piacere
-


Il muro della GPU si sta rompendo: la rivoluzione invisibile nelle architetture post-trasformatore
-


Google NotebookLM introduce la funzionalità di ricerca approfondita
-


Yann LeCun, scienziato capo dell'intelligenza artificiale di Meta, pianifica l'uscita dalla startup
-


Come far passare di nascosto articoli scientifici assurdi ai revisori dell'intelligenza artificiale
-


L'attacco DDoS ai documenti di indagine che sta travolgendo la ricerca scientifica
-


I modelli di intelligenza artificiale preferiscono la scrittura umana a quella generata dall'intelligenza artificiale











