
Intelligenza Artificiale
Ottimizzazione delle preferenze dirette: una guida completa

Allineare i modelli linguistici di grandi dimensioni (LLM) con i valori e le preferenze umani è una sfida. Metodi tradizionali, come ad es Apprendimento di rinforzo dal feedback umano (RLHF), hanno aperto la strada integrando gli input umani per perfezionare i risultati del modello. Tuttavia, RLHF può essere complesso e dispendioso in termini di risorse, richiedendo una notevole potenza di calcolo e di elaborazione dei dati. Ottimizzazione diretta delle preferenze (DPO) emerge come un approccio nuovo e più snello, offrendo un’alternativa efficiente a questi metodi tradizionali. Semplificando il processo di ottimizzazione, DPO non solo riduce il carico computazionale ma migliora anche la capacità del modello di adattarsi rapidamente alle preferenze umane
In questa guida approfondiremo il DPO, esplorandone i fondamenti, l'implementazione e le applicazioni pratiche.
La necessità di un allineamento delle preferenze
Per comprendere il DPO, è fondamentale capire perché allineare gli LLM alle preferenze umane è così importante. Nonostante le loro capacità impressionanti, gli LLM formati su vasti set di dati possono talvolta produrre output incoerenti, distorti o non allineati con i valori umani. Questo disallineamento può manifestarsi in vari modi:
- Generazione di contenuti non sicuri o dannosi
- Fornire informazioni inesatte o fuorvianti
- Mostrare bias presenti nei dati di training
Per affrontare questi problemi, i ricercatori hanno sviluppato tecniche per mettere a punto gli LLM utilizzando il feedback umano. Il più importante di questi approcci è stato RLHF.
Comprendere RLHF: il precursore del DPO
L'apprendimento per rinforzo dal feedback umano (RLHF) è stato il metodo di riferimento per allineare gli LLM alle preferenze umane. Analizziamo il processo RLHF per comprenderne le complessità:
a) Fine tuning supervisionato (SFT): Il processo inizia mettendo a punto un LLM preaddestrato su un set di dati di risposte di alta qualità. Questo passaggio aiuta il modello a generare output più pertinenti e coerenti per l'attività target.
b) Modellazione delle ricompense: Un modello di ricompensa separato viene addestrato per prevedere le preferenze umane. Ciò comporta:
- Generazione di coppie di risposte per determinati prompt
- Chiedere agli esseri umani di valutare quale risposta preferiscono
- Addestramento di un modello per prevedere queste preferenze
c) Insegnamento rafforzativo: L'LLM ottimizzato viene quindi ulteriormente ottimizzato utilizzando l'apprendimento per rinforzo. Il modello di ricompensa fornisce feedback, guidando il LLM a generare risposte in linea con le preferenze umane.
Ecco uno pseudocodice Python semplificato per illustrare il processo RLHF:
Sebbene efficace, RLHF presenta diversi inconvenienti:
- Richiede formazione e mantenimento di più modelli (SFT, modello di ricompensa e modello ottimizzato per RL)
- Il processo RL può essere instabile e sensibile agli iperparametri
- È computazionalmente costoso e richiede molti passaggi avanti e indietro attraverso i modelli
Queste limitazioni hanno motivato la ricerca di alternative più semplici ed efficienti, portando allo sviluppo del DPO.
Ottimizzazione delle preferenze dirette: concetti fondamentali

Ottimizzazione delle preferenze dirette https://arxiv.org/abs/2305.18290
Questa immagine mette in contrasto due approcci distinti per allineare i risultati del LLM con le preferenze umane: apprendimento per rinforzo dal feedback umano (RLHF) e ottimizzazione delle preferenze dirette (DPO). RLHF si basa su un modello di ricompensa per guidare la politica del modello linguistico attraverso cicli di feedback iterativi, mentre DPO ottimizza direttamente gli output del modello per abbinare le risposte preferite dagli umani utilizzando i dati sulle preferenze. Questo confronto evidenzia i punti di forza e le potenziali applicazioni di ciascun metodo, fornendo informazioni su come i futuri LLM potrebbero essere formati per allinearsi meglio alle aspettative umane.
Idee chiave dietro il DPO:
a) Modellazione della ricompensa implicita: Il DPO elimina la necessità di un modello di ricompensa separato trattando il modello linguistico stesso come una funzione di ricompensa implicita.
b) Formulazione basata sulle politiche: invece di ottimizzare una funzione di ricompensa, il DPO ottimizza direttamente la politica (modello linguistico) per massimizzare la probabilità delle risposte preferite.
c) Soluzione in forma chiusa: DPO sfrutta una visione matematica che consente una soluzione in forma chiusa alla policy ottimale, evitando la necessità di aggiornamenti iterativi RL.
Implementazione del DPO: una guida pratica al codice
L'immagine seguente mostra uno snippet di codice che implementa la funzione di perdita DPO utilizzando PyTorch. Questa funzione svolge un ruolo cruciale nel perfezionare il modo in cui i modelli linguistici danno priorità ai risultati in base alle preferenze umane. Ecco una ripartizione dei componenti chiave:
- Firma di funzione: Il
dpo_lossla funzione accetta diversi parametri tra cui le probabilità del registro delle politiche (pi_logps), probabilità logaritmiche del modello di riferimento (ref_logps) e indici che rappresentano i completamenti preferiti e non preferiti (yw_idxs,yl_idxs). Inoltre, abetaIl parametro controlla la forza della penalità KL. - Estrazione della probabilità logaritmica: Il codice estrae le probabilità logaritmiche per i completamenti preferiti e non preferiti sia dalla policy che dai modelli di riferimento.
- Calcolo del rapporto logaritmico: la differenza tra le probabilità logaritmiche per i completamenti preferiti e non preferiti viene calcolata sia per il modello politico che per quello di riferimento. Questo rapporto è fondamentale per determinare la direzione e l'entità dell'ottimizzazione.
- Calcolo delle perdite e dei premi: La perdita viene calcolata utilizzando il
logsigmoidfunzione, mentre i premi sono determinati ridimensionando la differenza tra le probabilità della politica e del registro di riferimentobeta.

Funzione di perdita DPO utilizzando PyTorch
Immergiamoci nella matematica alla base del DPO per capire come raggiunge questi obiettivi.
La matematica del DPO
Il DPO è una riformulazione intelligente del problema dell’apprendimento delle preferenze. Ecco una ripartizione passo passo:
a) Punto di partenza: massimizzazione della ricompensa vincolata al KL
L’obiettivo originale del RLHF può essere espresso come:
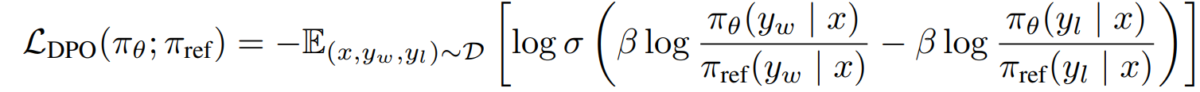
- πθ è la politica (modello linguistico) che stiamo ottimizzando
- r(x,y) è la funzione di ricompensa
- πref è una politica di riferimento (solitamente il modello SFT iniziale)
- β controlla la forza del vincolo di divergenza KL
b) Modulo di politica ottimale: Si può dimostrare che la politica ottimale per questo obiettivo assume la forma:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Dove Z(x) è una costante di normalizzazione.
c) Dualità politica di ricompensa: L'intuizione chiave del DPO è esprimere la funzione di ricompensa in termini di politica ottimale:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Modello di preferenza Assumendo che le preferenze seguano il modello Bradley-Terry, possiamo esprimere la probabilità di preferire y1 rispetto a y2 come:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Dove σ è la funzione logistica.
e) Obiettivo del DPO Sostituendo la nostra dualità politica di ricompensa nel modello di preferenza, arriviamo all'obiettivo del DPO:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Questo obiettivo può essere ottimizzato utilizzando tecniche di discesa del gradiente standard, senza la necessità di algoritmi RL.
Implementazione del DPO
Ora che abbiamo compreso la teoria alla base del DPO, vediamo come implementarlo nella pratica. Useremo Python e PyTorch per questo esempio:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Sfide e direzioni future
Sebbene il DPO offra vantaggi significativi rispetto agli approcci RLHF tradizionali, ci sono ancora sfide e aree per ulteriori ricerche:
a) Scalabilità a modelli più grandi:
Poiché i modelli linguistici continuano a crescere di dimensioni, applicare in modo efficiente il DPO a modelli con centinaia di miliardi di parametri rimane una sfida aperta. I ricercatori stanno esplorando tecniche come:
- Metodi di ottimizzazione efficienti (ad esempio, LoRA, ottimizzazione del prefisso)
- Ottimizzazioni della formazione distribuita
- Checkpoint del gradiente e training a precisione mista
Esempio di utilizzo di LoRA con DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Adattamento multi-task e pochi scatti:
Lo sviluppo di tecniche DPO in grado di adattarsi in modo efficiente a nuovi compiti o domini con dati sulle preferenze limitati è un’area di ricerca attiva. Gli approcci esplorati includono:
- Strutture di meta-apprendimento per un rapido adattamento
- Ottimizzazione basata su prompt per DPO
- Trasferire l'apprendimento dai modelli di preferenza generale a domini specifici
c) Gestione delle preferenze ambigue o contrastanti:
I dati sulle preferenze del mondo reale spesso contengono ambiguità o conflitti. Migliorare la robustezza del DPO rispetto a tali dati è fondamentale. Le potenziali soluzioni includono:
- Modellizzazione delle preferenze probabilistiche
- Apprendimento attivo per risolvere ambiguità
- Aggregazione delle preferenze multi-agente
Esempio di modellazione delle preferenze probabilistiche:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Combinazione del DPO con altre tecniche di allineamento:
L’integrazione del DPO con altri approcci di allineamento potrebbe portare a sistemi più robusti e capaci:
- Principi costituzionali dell'intelligenza artificiale per la soddisfazione esplicita dei vincoli
- Modellizzazione del dibattito e della ricompensa ricorsiva per l'elicitazione di preferenze complesse
- Apprendimento per rinforzo inverso per dedurre le funzioni di ricompensa sottostanti
Esempio di combinazione del DPO con l’IA costituzionale:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Considerazioni pratiche e migliori pratiche
Quando implementi DPO per applicazioni reali, considera i seguenti suggerimenti:
a) Qualità dei dati: La qualità dei tuoi dati sulle preferenze è fondamentale. Assicurati che il tuo set di dati:
- Copre una vasta gamma di input e comportamenti desiderati
- Presenta annotazioni sulle preferenze coerenti e affidabili
- Bilancia diversi tipi di preferenze (ad esempio, fattualità, sicurezza, stile)
b) Sintonia iperparametro: Sebbene DPO abbia meno iperparametri di RLHF, l'ottimizzazione è comunque importante:
- β (beta): controlla il compromesso tra soddisfazione delle preferenze e divergenza dal modello di riferimento. Inizia con i valori in giro 0.1-0.5.
- Tasso di apprendimento: utilizzare un tasso di apprendimento inferiore rispetto alla regolazione fine standard, in genere nell'intervallo di Da 1e-6 a 1e-5.
- Dimensione del lotto: dimensioni del lotto più grandi (32-128) spesso funzionano bene per l'apprendimento delle preferenze.
c) Perfezionamento iterativo: DPO può essere applicato in modo iterativo:
- Addestrare un modello iniziale utilizzando DPO
- Genera nuove risposte utilizzando il modello addestrato
- Raccogli nuovi dati sulle preferenze su queste risposte
- Riqualificare utilizzando il set di dati espanso

Prestazioni di ottimizzazione delle preferenze dirette
Questa immagine mostra le prestazioni di LLM come GPT-4 rispetto ai giudizi umani in varie tecniche di formazione, tra cui Direct Preference Optimization (DPO), Supervised Fine-Tuning (SFT) e Proximal Policy Optimization (PPO). La tabella rivela che gli output di GPT-4 sono sempre più allineati con le preferenze umane, specialmente nelle attività di riepilogo. Il livello di accordo tra GPT-4 e i revisori umani dimostra la capacità del modello di generare contenuti che risuonano con i valutatori umani, quasi quanto i contenuti generati dagli umani.
Casi di studio e applicazioni
Per illustrare l'efficacia del DPO, diamo un'occhiata ad alcune applicazioni del mondo reale e ad alcune delle sue varianti:
- DPO iterativo: sviluppata da Snorkel (2023), questa variante combina il campionamento del rifiuto con DPO, consentendo un processo di selezione più raffinato per i dati di addestramento. Iterando su più cicli di campionamento delle preferenze, il modello è in grado di generalizzare meglio ed evitare un adattamento eccessivo a preferenze rumorose o distorte.
- IPO (Ottimizzazione iterativa delle preferenze): Introdotto da Azar et al. (2023), l’IPO aggiunge un termine di regolarizzazione per prevenire l’overfitting, che è un problema comune nell’ottimizzazione basata sulle preferenze. Questa estensione consente ai modelli di mantenere un equilibrio tra l’adesione alle preferenze e il mantenimento delle capacità di generalizzazione.
- KTO (Ottimizzazione del trasferimento della conoscenza): Una variante più recente di Ethayarajh et al. (2023), KTO rinuncia del tutto alle preferenze binarie. Si concentra invece sul trasferimento della conoscenza da un modello di riferimento al modello politico, ottimizzando un allineamento più fluido e coerente con i valori umani.
- DPO multimodale per l'apprendimento interdominio di Xu et al. (2024): un approccio in cui il DPO viene applicato in diverse modalità (testo, immagine e audio) dimostrando la sua versatilità nell'allineare i modelli alle preferenze umane attraverso diversi tipi di dati. Questa ricerca evidenzia il potenziale del DPO nella creazione di sistemi di intelligenza artificiale più completi in grado di gestire compiti complessi e multimodali.











