Intelligenza artificiale
L’AI aiuta gli oratori nervosi a ‘leggere la stanza’ durante le videoconferenze

Nel 2013, un sondaggio sulle fobie comuni ha determinato che la prospettiva di parlare in pubblico era peggiore della prospettiva della morte per la maggior parte dei rispondenti. La sindrome è conosciuta come glossofobia.
La migrazione verso le riunioni online su piattaforme come Zoom e Google Spaces, a causa del COVID, non ha migliorato la situazione. Quando la riunione contiene un grande numero di partecipanti, le nostre naturali capacità di valutazione delle minacce sono compromesse dalle righe e dagli iconi dei partecipanti a bassa risoluzione e dalla difficoltà di leggere i segnali visivi sottili delle espressioni facciali e del linguaggio del corpo. Ad esempio, Skype si è rivelato essere una piattaforma scarsa per la trasmissione di segnali non verbali.
Gli effetti sulla performance di pubblico speaking della percezione dell’interesse e della risposta sono ben documentati e intuitivamente ovvi per la maggior parte di noi. Una risposta opaca del pubblico può causare agli oratori di esitare e ricorrere a discorsi di riempitivo, all’oscuro di是否 i loro argomenti stanno incontrando l’accordo, il disprezzo o l’indifferenza, spesso creando un’esperienza scomoda sia per l’oratore che per gli ascoltatori.
Sotto la pressione dell’imprevista svolta verso le videoconferenze online ispirata dalle restrizioni e dalle precauzioni del COVID, il problema è argomentabile peggiorato, e sono stati suggeriti diversi schemi di feedback del pubblico nelle comunità di ricerca sulla visione computerizzata e sull’affect negli ultimi due anni.
Soluzioni orientate all’hardware
La maggior parte di questi, tuttavia, coinvolge attrezzature aggiuntive o software complesso che possono sollevare problemi di privacy o logistici – approcci relativamente costosi o altrimenti vincolati dalle risorse che precedono la pandemia. Nel 2001, il MIT ha proposto il Galvactivator, un dispositivo indossabile sulla mano che inferisce lo stato emotivo del partecipante del pubblico, testato durante un simposio di un giorno.

Nel 2001, il Galvactivator del MIT, che misurava la risposta della conduttività della pelle nel tentativo di comprendere il sentimento e l’engagement del pubblico. Source: https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
Molta energia accademica è stata anche dedicata alla possibile distribuzione di ‘clicker’ come Sistema di Risposta del Pubblico (ARS), una misura per aumentare la partecipazione attiva del pubblico (che aumenta automaticamente l’engagement, poiché costringe l’utente a ricoprire il ruolo di un nodo di feedback attivo), ma che è stato anche immaginato come un mezzo di incoraggiamento per gli oratori.
Altri tentativi di ‘connettere’ l’oratore e il pubblico hanno incluso monitoraggio della frequenza cardiaca, l’uso di attrezzature complesse indossabili per sfruttare l’elettroencefalografia, ‘misuratori di applauso’, riconoscimento delle emozioni basato sulla visione computerizzata per lavoratori da scrivania e l’uso di emoticon inviati dal pubblico durante l’orazione dell’oratore.

Nel 2017, l’EngageMeter, un progetto di ricerca accademico congiunto tra LMU Munich e l’Università di Stoccarda. Source: http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
Come sub-pursuit dell’area lucrativa dell’analisi del pubblico, il settore privato ha preso un particolare interesse nella stima e nel tracciamento dello sguardo – sistemi in cui ogni membro del pubblico (che potrebbe a sua volta dover parlare), è soggetto a tracciamento oculare come indice di engagement e approvazione.
Tutti questi metodi sono abbastanza ad alta frizione. Molti di loro richiedono attrezzature aggiuntive o software complesso che possono sollevare problemi di privacy o logistici – approcci relativamente costosi o altrimenti vincolati dalle risorse che precedono la pandemia.
Pertanto, lo sviluppo di sistemi minimalisti basati su poco più che strumenti comuni per le videoconferenze è diventato di interesse negli ultimi 18 mesi.
Segnalazione della approvazione del pubblico in modo discreto
A questo scopo, una nuova collaborazione di ricerca tra l’Università di Tokyo e l’Università di Carnegie Mellon offre un sistema innovativo che può essere utilizzato con strumenti standard di videoconferenza (come Zoom) utilizzando solo un sito web abilitato per la webcam su cui è in esecuzione software di stima della posizione e dello sguardo leggero. In questo modo, anche la necessità di plugin del browser locale è evitata.
I cenni del capo e la stima dell’attenzione dell’utente vengono tradotti in dati rappresentativi che vengono visualizzati all’oratore, consentendo un test ‘live’ della misura in cui il contenuto sta coinvolgendo il pubblico – e anche almeno un indicatore vago dei periodi di discorso in cui l’oratore potrebbe perdere l’interesse del pubblico.
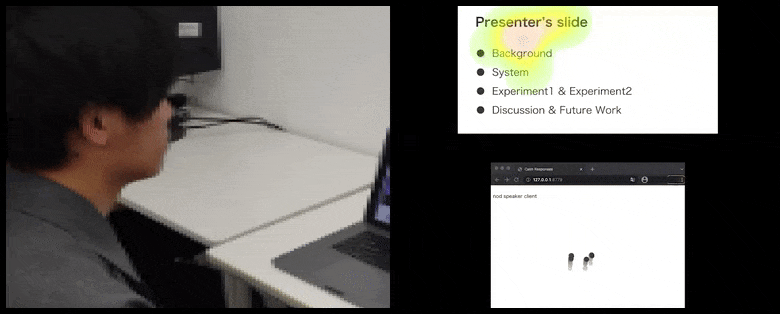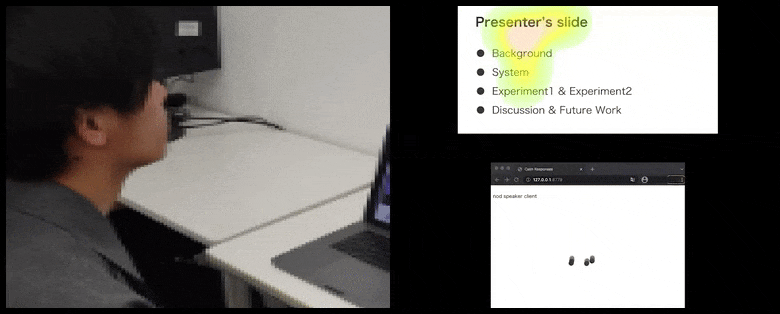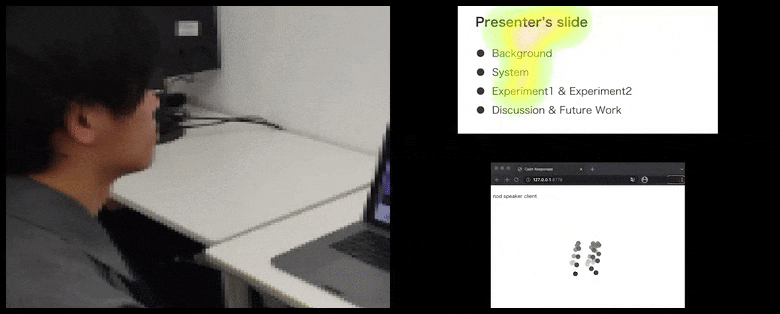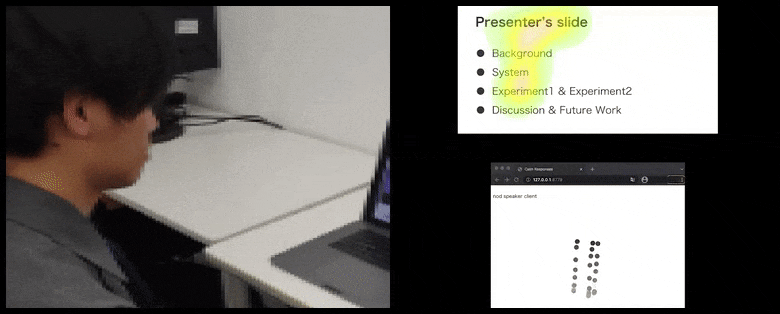
Con CalmResponses, l’attenzione e il cenni del capo dell’utente vengono aggiunti a un pool di feedback del pubblico e tradotti in una rappresentazione visiva che può beneficiare l’oratore. Vedi il video incorporato alla fine dell’articolo per maggiori dettagli ed esempi. Source: https://www.youtube.com/watch?v=J_PhB4FCzk0
In molte situazioni accademiche, come le lezioni online, gli studenti possono essere completamente invisibili all’oratore, poiché non hanno attivato le loro telecamere a causa della consapevolezza della loro sfondo o aspetto attuale. CalmResponses può affrontare questo ostacolo altrimenti spinoso per il feedback dell’oratore segnalando ciò che sa su come l’oratore sta guardando il contenuto e se stanno cennando, senza alcun bisogno che il visualizzatore attivi la sua telecamera.
Il documento è intitolato CalmResponses: visualizzazione delle reazioni collettive del pubblico nella comunicazione remota e è un lavoro congiunto tra due ricercatori dell’UoT e uno di Carnegie Mellon.
Gli autori offrono una demo web-based live e hanno rilasciato il codice sorgente su GitHub.
La struttura di CalmResponses
L’interesse di CalmResponses per il cenni del capo, rispetto ad altre possibili disposizioni del capo, si basa sulla ricerca (alcuna delle quali risale all’era di Darwin) che indica che più dell’80% di tutti i movimenti del capo degli ascoltatori sono composti da cenni del capo (anche quando stanno esprimendo disaccordo). Allo stesso tempo, i movimenti dello sguardo sono stati dimostrati su numerosi studi per essere un indice affidabile di interesse o engagement.
CalmResponses è implementato con HTML, CSS e JavaScript e comprende tre sottosistemi: un client del pubblico, un client dell’oratore e un server. Il client del pubblico passa i dati di sguardo o di movimento del capo dell’utente dalla telecamera dell’utente tramite WebSockets sulla piattaforma di applicazioni cloud Heroku.

Il cenni del capo del pubblico visualizzato a destra in un movimento animato con CalmResponses. In questo caso, la visualizzazione del movimento è disponibile non solo per l’oratore, ma per l’intero pubblico. Source: https://arxiv.org/pdf/2204.02308.pdf
Per la sezione di tracciamento dello sguardo del progetto, i ricercatori hanno utilizzato WebGazer, un framework di tracciamento dello sguardo basato su JavaScript leggero e basato sul browser che può essere eseguito con bassa latenza direttamente da un sito web (vedi link sopra per l’implementazione web-based dei ricercatori).
Poiché il bisogno di una semplice implementazione e di un riconoscimento di risposta aggregata grezza supera il bisogno di alta precisione nella stima della posizione e dello sguardo, i dati di input della posizione vengono lisciati in base ai valori medi prima di essere considerati per la stima della risposta complessiva.
L’azione del cenni del capo viene valutata tramite la libreria JavaScript clmtrackr, che adatta modelli facciali a facce rilevate in immagini o video tramite spostamento dei punti di riferimento regolarizzato. Per scopi di economia e bassa latenza, solo il punto di riferimento rilevato per il naso viene attivamente monitorato nell’implementazione degli autori, poiché ciò è sufficiente per tracciare le azioni del cenni del capo.
Il movimento della punta del naso dell’utente crea una traccia che contribuisce al pool di risposta del pubblico relativo al cenni del capo, visualizzato in modo aggregato a tutti i partecipanti.
Mappa di calore
Mentre l’attività del cenni del capo è rappresentata da punti dinamici in movimento (vedi immagini sopra e video alla fine), l’attenzione visiva viene segnalata in termini di una mappa di calore che mostra all’oratore e al pubblico dove si trova il locus generale dell’attenzione sullo schermo condiviso della presentazione o dell’ambiente della videoconferenza.

Tutti i partecipanti possono vedere dove si trova l’attenzione generale dell’utente. Il documento non menziona se questa funzionalità è disponibile quando l’utente può vedere una ‘galleria’ di altri partecipanti, che potrebbe rivelare un focus specioso su un particolare partecipante, per vari motivi.
Test
Due ambienti di test sono stati formulati per CalmResponses sotto forma di uno studio di ablazione tacito, utilizzando tre set di circostanze variate: nel ‘Condizione B’ (base), gli autori hanno replicato una lezione studentesca online tipica, in cui la maggior parte degli studenti tiene spenta la telecamera, e l’oratore non ha la possibilità di vedere i volti del pubblico; nella ‘Condizione CR-E’, l’oratore poteva vedere il feedback dello sguardo (mappe di calore); nella ‘Condizione CR-N’, l’oratore poteva vedere sia l’attività del cenni del capo che dell’attenzione del pubblico.
Il primo scenario sperimentale ha compreso la condizione B e la condizione CR-E; il secondo ha compreso la condizione B e la condizione CR-N. Il feedback è stato ottenuto sia dagli oratori che dal pubblico.
In ogni esperimento, tre fattori sono stati valutati: valutazione oggettiva e soggettiva della presentazione (incluso un questionario di autovalutazione dell’oratore riguardo a come è andata la presentazione); il numero di eventi di ‘discorso di riempitivo’, indicativo di insicurezza e prevaricazione momentanea; e commenti qualitativi. Questi criteri sono comuni stimatori della qualità del discorso e dell’ansia dell’oratore.
Il pool di test era composto da 38 persone di età compresa tra 19 e 44 anni, composte da 29 maschi e nove femmine con un’età media di 24,7, tutti giapponesi o cinesi e tutti fluenti in giapponese. Sono stati divisi casualmente in cinque gruppi di 6-7 partecipanti e nessuno dei soggetti conosceva gli altri personalmente.
I test sono stati condotti su Zoom, con cinque oratori che hanno tenuto presentazioni nel primo esperimento e sei nel secondo.

Condizioni di riempitivo segnalate come caselle arancioni. In generale, il contenuto di riempitivo è diminuito in proporzione al feedback del pubblico aumentato dal sistema.
Gli ricercatori notano che uno degli oratori ha ridotto notevolmente i riempitivi e che nella ‘Condizione CR-N’, l’oratore ha raramente pronunciato frasi di riempitivo. Vedi il documento per i risultati molto dettagliati e granulari riportati; tuttavia, i risultati più marcati sono stati nella valutazione soggettiva degli oratori e dei partecipanti del pubblico.
Commenti del pubblico hanno incluso:
‘Mi sono sentito coinvolto nelle presentazioni” [AN2], “Non ero sicuro che i discorsi degli oratori fossero migliorati, ma ho sentito un senso di unità dalle visualizzazioni dei movimenti del capo degli altri.’ [AN6]
‘Non ero sicuro che i discorsi degli oratori fossero migliorati, ma ho sentito un senso di unità dalle visualizzazioni dei movimenti del capo degli altri.’
I ricercatori notano che il sistema introduce un nuovo tipo di pausa artificiale nella presentazione dell’oratore, poiché l’oratore è incline a fare riferimento al sistema visivo per valutare il feedback del pubblico prima di procedere ulteriormente.
Notano anche un tipo di ‘effetto del camice bianco’, difficile da evitare in circostanze sperimentali, in cui alcuni partecipanti si sono sentiti vincolati dalle possibili implicazioni di sicurezza dell’essere monitorati per dati biometrici.
Conclusione
Un notevole vantaggio in un sistema come questo è che tutte le tecnologie aggiuntive non standard necessarie per questo approccio scompaiono completamente dopo il loro utilizzo. Non ci sono plugin del browser residui da disinstallare, o che possano sollevare dubbi nella mente dei partecipanti su是否 dovrebbero rimanere nei loro rispettivi sistemi; e non c’è bisogno di guidare gli utenti attraverso il processo di installazione (sebbene il framework web-based richieda un minuto o due di calibrazione iniziale dell’utente), o di navigare la possibilità che gli utenti non abbiano i permessi adeguati per installare software locale, inclusi add-on e estensioni del browser.
Sebbene le movimenti facciali e oculari valutati non siano così precisi come potrebbero essere in circostanze in cui si utilizzano framework di apprendimento automatico dedicati (come la serie YOLO), questo approccio quasi senza attrito per la valutazione del pubblico fornisce un’adeguata accuratezza per l’analisi dell’umore e della posizione in scenari di videoconferenza tipici. Soprattutto, è molto economico.
Guarda il video del progetto associato qui sotto per ulteriori dettagli ed esempi.
Pubblicato per la prima volta l’11 aprile 2022.












