Kemampuan untuk menghasilkan aset digital 3D dari prompt teks mewakili salah satu perkembangan paling menarik baru-baru ini dalam AI dan grafis komputer. Karena pasar aset digital 3D diperkirakan tumbuh dari $28,3 miliar pada 2024 menjadi $51,8 miliar pada 2029, model AI text-to-3D diposisikan untuk memainkan peran besar dalam merevolusi pembuatan konten di berbagai industri seperti gaming, film, e-commerce, dan lainnya. Tapi bagaimana tepatnya sistem AI ini bekerja? Dalam artikel ini, kita akan mempelajari detail teknis di balik generasi text-to-3D.
Tantangan Generasi 3D
Menghasilkan aset 3D dari teks adalah tugas yang jauh lebih kompleks daripada generasi gambar 2D. Sementara gambar 2D pada dasarnya adalah grid piksel, aset 3D memerlukan representasi geometri, tekstur, material, dan sering animasi dalam ruang tiga dimensi. Dimensi tambahan dan kompleksitas ini membuat tugas generasi jauh lebih menantang.
Beberapa tantangan kunci dalam generasi text-to-3D termasuk:
Menghasilkan geometri dan struktur 3D
Menghasilkan tekstur dan material yang konsisten di seluruh permukaan 3D
Memastikan kemungkinan fisik dan konsistensi dari berbagai sudut pandang
Mengabadikan detail halus dan struktur global secara bersamaan
Menghasilkan aset yang dapat dengan mudah dirender atau dicetak 3D
Untuk mengatasi tantangan ini, model text-to-3D menggunakan beberapa teknologi dan teknik kunci.
Komponen Kunci Sistem Text-to-3D
Sebagian besar sistem generasi text-to-3D berbagi beberapa komponen inti:
Pengkodean teks: Mengubah prompt teks input menjadi representasi numerik
Representasi 3D: Metode untuk merepresentasikan geometri dan penampilan 3D
Model generatif: Model AI inti untuk menghasilkan aset 3D
Rendering: Mengubah representasi 3D menjadi gambar 2D untuk visualisasi
Mari kita jelajahi masing-masing ini lebih detail.
Pengkodean Teks
Langkah pertama adalah mengubah prompt teks input menjadi representasi numerik yang dapat bekerja dengan model AI. Ini biasanya dilakukan menggunakan model bahasa besar seperti BERT atau GPT.
Representasi 3D
Ada beberapa cara umum untuk merepresentasikan geometri 3D dalam model AI:
Grid voxel: Array 3D nilai yang merepresentasikan okupansi atau fitur
Awan titik: Set titik 3D
Mesh: Verteks dan wajah yang mendefinisikan permukaan
Fungsi implisit: Fungsi kontinu yang mendefinisikan permukaan (misalnya fungsi jarak bertanda)
Medan radiasi neural (NeRFs): Jaringan neural yang merepresentasikan kepadatan dan warna dalam ruang 3D
Masing-masing memiliki trade-off dalam hal resolusi, penggunaan memori, dan kemudahan generasi. Banyak model baru menggunakan fungsi implisit atau NeRFs karena memungkinkan hasil berkualitas tinggi dengan persyaratan komputasi yang wajar.
Misalnya, kita dapat merepresentasikan bola sederhana sebagai fungsi jarak bertanda:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Evaluasi SDF pada titik 3D
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Jarak ke permukaan bola: {distance}")
Model Generatif
Inti dari sistem text-to-3D adalah model generatif yang menghasilkan representasi 3D dari pengkodean teks. Sebagian besar model canggih menggunakan variasi model difusi, mirip dengan yang digunakan dalam generasi gambar 2D.
Model difusi bekerja dengan secara bertahap menambahkan noise ke data, lalu belajar untuk membalik proses ini. Untuk generasi 3D, proses ini terjadi dalam ruang representasi 3D yang dipilih.
Pseudocode sederhana untuk langkah pelatihan model difusi mungkin terlihat seperti:
def diffusion_training_step(model, x_0, text_embedding):
# Sampel waktu acak
t = torch.randint(0, num_timesteps, (1,))
# Tambahkan noise ke input
noise = torch.randn_like(x_0)
x_t = add_noise(x_0, noise, t)
# Prediksi noise
predicted_noise = model(x_t, t, text_embedding)
# Hitung loss
loss = F.mse_loss(noise, predicted_noise)
return loss
# Loop pelatihan
for batch in dataloader:
x_0, text = batch
text_embedding = encode_text(text)
loss = diffusion_training_step(model, x_0, text_embedding)
loss.backward()
optimizer.step()
Selama generasi, kita memulai dari noise murni dan secara bertahap mengurangi noise, yang dikondisikan pada pengkodean teks.
Rendering
Untuk visualisasi hasil dan menghitung loss selama pelatihan, kita perlu merender representasi 3D kita menjadi gambar 2D. Ini biasanya dilakukan menggunakan teknik rendering yang dapat dibedakan yang memungkinkan gradien mengalir kembali melalui proses rendering.
Untuk representasi berbasis mesh, kita mungkin menggunakan renderer berbasis rasterisasi:
import torch
import torch.nn.functional as F
import pytorch3d.renderer as pr
def render_mesh(vertices, faces, image_size=256):
# Buat renderer
renderer = pr.MeshRenderer(
rasterizer=pr.MeshRasterizer(),
shader=pr.SoftPhongShader()
)
# Atur kamera
cameras = pr.FoVPerspectiveCameras()
# Render
images = renderer(vertices, faces, cameras=cameras)
return images
# Contoh penggunaan
vertices = torch.rand(1, 100, 3) # Verteks acak
faces = torch.randint(0, 100, (1, 200, 3)) # Wajah acak
rendered_images = render_mesh(vertices, faces)
Untuk representasi implisit seperti NeRFs, kita biasanya menggunakan teknik ray marching untuk merender tampilan.
Menggabungkan Semua: Pipa Text-to-3D
Sekarang bahwa kita telah mencakup komponen kunci, mari kita jalani bagaimana mereka bergabung dalam pipa generasi text-to-3D yang khas:
Pengkodean teks: Prompt input dikodekan menjadi representasi vektor yang padat menggunakan model bahasa.
Generasi awal: Model difusi, yang dikondisikan pada pengkodean teks, menghasilkan representasi 3D awal (misalnya NeRF atau fungsi implisit).
Konsistensi multi-tampilan: Model merender beberapa tampilan aset 3D yang dihasilkan dan memastikan konsistensi di seluruh sudut pandang.
Penghalusan: Jaringan tambahan mungkin menghaluskan geometri, menambahkan tekstur, atau meningkatkan detail.
Output akhir: Representasi 3D dikonversi ke format yang diinginkan (misalnya mesh bertekstur) untuk digunakan dalam aplikasi hilir.
Berikut adalah contoh sederhana tentang bagaimana ini mungkin terlihat dalam kode:
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# Kode teks
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# Hasilkan representasi 3D awal
initial_3d = self.diffusion_model(text_embedding)
# Render beberapa tampilan
views = self.renderer(initial_3d, num_views=4)
# Haluskan berdasarkan konsistensi multi-tampilan
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# Penggunaan
model = TextTo3D()
text_prompt = "Mobil olahraga merah"
generated_3d = model(text_prompt)
Model Aset 3D Text-to-Top yang Tersedia
3DGen – Meta
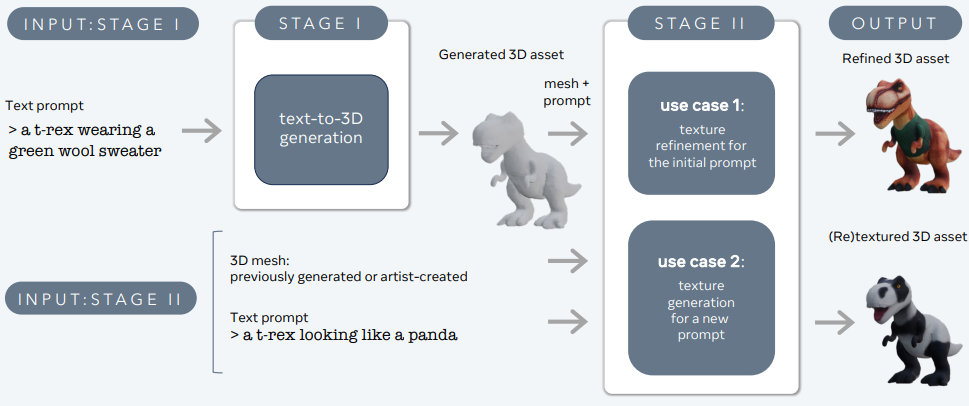
3DGen dirancang untuk menangani masalah generasi konten 3D—seperti karakter, prop, dan adegan—dari deskripsi teks.
3DGen mendukung rendering berbasis fisik (PBR), yang penting untuk relighting aset 3D yang realistis dalam aplikasi dunia nyata. Ini juga memungkinkan generasi ulang tekstur dari bentuk 3D yang dihasilkan sebelumnya atau dibuat oleh seniman menggunakan input teks baru. Pipa ini mengintegrasikan dua komponen inti: Meta 3D AssetGen dan Meta 3D TextureGen, yang menangani generasi text-to-3D dan text-to-texture, masing-masing.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) bertanggung jawab untuk generasi awal aset 3D dari prompt teks. Komponen ini menghasilkan mesh 3D dengan tekstur dan peta material PBR dalam sekitar 30 detik.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) menghaluskan tekstur yang dihasilkan oleh AssetGen. Ini juga dapat digunakan untuk menghasilkan tekstur baru untuk mesh 3D yang ada berdasarkan deskripsi teks tambahan. Tahap ini memakan waktu sekitar 20 detik.
Point-E (OpenAI)
Point-E, dikembangkan oleh OpenAI, adalah model generasi text-to-3D lain yang patut diperhatikan. Tidak seperti DreamFusion, yang menghasilkan representasi NeRF, Point-E menghasilkan awan titik 3D.
Fitur kunci dari Point-E:
a) Pipa dua tahap: Point-E pertama-tama menghasilkan tampilan sintetis 2D menggunakan model difusi text-to-image, lalu menggunakan gambar ini untuk mengkondisikan model difusi kedua yang menghasilkan awan titik 3D.
b) Efisiensi: Point-E dirancang untuk efisiensi komputasi, mampu menghasilkan awan titik 3D dalam hitungan detik pada satu GPU.
c) Informasi warna: Model ini dapat menghasilkan awan titik berwarna, mempertahankan baik geometri dan informasi penampilan.
Batasan:
Kualitas yang lebih rendah dibandingkan dengan pendekatan berbasis mesh atau NeRF
Awan titik memerlukan pemrosesan tambahan untuk banyak aplikasi hilir
Shap-E (OpenAI):
Membangun atas Point-E, OpenAI memperkenalkan Shap-E, yang menghasilkan mesh 3D bukan awan titik. Ini menangani beberapa batasan Point-E sambil mempertahankan efisiensi komputasi.
Fitur kunci dari Shap-E:
a) Representasi implisit: Shap-E belajar untuk menghasilkan representasi implisit (fungsi jarak bertanda) dari objek 3D.
b) Pengambilan mesh: Model menggunakan implementasi diferensial dari algoritma marching cubes untuk mengubah representasi implisit menjadi mesh poligonal.
c) Generasi tekstur: Shap-E juga dapat menghasilkan tekstur untuk mesh 3D, menghasilkan output yang lebih menarik secara visual.
Kelebihan:
Waktu generasi yang cepat (detik hingga menit)
Output mesh langsung yang sesuai untuk rendering dan aplikasi hilir
Kemampuan untuk menghasilkan baik geometri dan tekstur
GET3D (NVIDIA):
GET3D, dikembangkan oleh peneliti NVIDIA, adalah model generasi text-to-3D lain yang kuat yang fokus pada menghasilkan mesh 3D bertekstur berkualitas tinggi.
Fitur kunci dari GET3D:
a) Representasi permukaan eksplisit: Tidak seperti DreamFusion atau Shap-E, GET3D langsung menghasilkan representasi permukaan eksplisit (mesh) tanpa representasi implisit intermediate.
b) Generasi tekstur: Model ini termasuk teknik rendering diferensial untuk belajar dan menghasilkan tekstur berkualitas tinggi untuk mesh 3D.
c) Arsitektur GAN: GET3D menggunakan pendekatan jaringan generatif adversarial (GAN), yang memungkinkan generasi cepat sekali model dilatih.
Kelebihan:
Geometri dan tekstur berkualitas tinggi
Waktu inferensi yang cepat
Integrasi langsung dengan mesin rendering 3D
Batasan:
Memerlukan data pelatihan 3D, yang dapat langka untuk beberapa kategori objek
Kesimpulan
Generasi AI text-to-3D mewakili pergeseran mendasar dalam cara kita membuat dan berinteraksi dengan konten 3D. Dengan menggunakan teknik pembelajaran dalam yang canggih, model ini dapat menghasilkan aset 3D yang kompleks dan berkualitas tinggi dari deskripsi teks sederhana. Ketika teknologi ini terus berkembang, kita dapat mengharapkan melihat sistem text-to-3D yang semakin canggih dan mampu yang akan merevolusi industri dari gaming dan film hingga desain produk dan arsitektur.
Saya telah menghabiskan lima tahun terakhir dengan membenamkan diri dalam dunia Machine Learning dan Deep Learning yang menarik. Minat dan keahlian saya telah membawa saya untuk berkontribusi pada lebih dari 50 proyek rekayasa perangkat lunak yang beragam, dengan fokus khusus pada AI/ML. Rasa ingin tahu saya yang terus-menerus juga telah menarik saya ke arah Natural Language Processing, sebuah bidang yang saya ingin jelajahi lebih lanjut.