Kecerdasan buatan
Pengkodean Kode: Panduan Lengkap

Pengkodean kode adalah cara transformatif untuk merepresentasikan potongan kode sebagai vektor padat dalam ruang kontinu. Pengkodean ini menangkap hubungan semantik dan fungsional antara potongan kode, memungkinkan aplikasi yang kuat dalam pemrograman AI-asist. Serupa dengan pengkodean kata dalam pemrosesan bahasa alami (NLP), pengkodean kode memposisikan potongan kode serupa dekat satu sama lain dalam ruang vektor, memungkinkan mesin untuk memahami dan memanipulasi kode lebih efektif.
Apa itu Pengkodean Kode?
Pengkodean kode mengubah struktur kode kompleks menjadi vektor numerik yang menangkap makna dan fungsionalitas kode. Tidak seperti metode tradisional yang memperlakukan kode sebagai urutan karakter, pengkodean menangkap hubungan semantik antara bagian kode. Ini sangat penting untuk berbagai tugas rekayasa perangkat lunak yang didorong AI, seperti pencarian kode, penyelesaian kode, deteksi bug, dan lainnya.
Sebagai contoh, pertimbangkan dua fungsi Python berikut:
def add_numbers(a, b): return a + b
<p>def sum_two_values(x, y): result = x + y return result</p>
Walaupun fungsi-fungsi ini terlihat berbeda secara sintaksis, mereka melakukan operasi yang sama. Pengkodean kode yang baik akan merepresentasikan dua fungsi ini dengan vektor serupa, menangkap kesamaan fungsional mereka meskipun perbedaan tekstual.

Pengkodean Vektor
Bagaimana Pengkodean Kode Dibuat?
Terdapat berbagai teknik untuk membuat pengkodean kode. Salah satu pendekatan umum melibatkan penggunaan jaringan saraf untuk mempelajari representasi ini dari dataset kode besar. Jaringan menganalisis struktur kode, termasuk token (kata kunci, pengidentifikasi), sintaksis (bagaimana kode disusun), dan potensi komentar untuk mempelajari hubungan antara potongan kode yang berbeda.
Mari kita uraikan prosesnya:
- Kode sebagai Urutan: Pertama, potongan kode dianggap sebagai urutan token (variabel, kata kunci, operator).
- Pelatihan Jaringan Saraf: Jaringan saraf memproses urutan ini dan mempelajari untuk memetakan mereka ke representasi vektor dengan ukuran tetap. Jaringan mempertimbangkan faktor seperti sintaksis, semantik, dan hubungan antara elemen kode.
- Menangkap Kesamaan: Pelatihan bertujuan untuk memposisikan potongan kode serupa (dengan fungsionalitas serupa) dekat satu sama lain dalam ruang vektor. Ini memungkinkan tugas seperti menemukan kode serupa atau membandingkan fungsionalitas.
Berikut adalah contoh sederhana dalam Python tentang bagaimana Anda mungkin melakukan praproses kode untuk pengkodean:
import ast
<p>def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = []
for node in ast.walk(tree):
if isinstance(node, ast.Name):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# Tambahkan jenis node lainnya sesuai kebutuhan
return tokens</p>
<p># Contoh penggunaan
code = """
def greet(name):
print("Halo, " + name + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# Output: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']</p>
Representasi token ini kemudian dapat diumpankan ke jaringan saraf untuk pengkodean.
Pendekatan yang Ada untuk Pengkodean Kode
Metode yang ada untuk pengkodean kode dapat diklasifikasikan menjadi tiga kategori utama:
Metode Berbasis Token
Metode berbasis token memperlakukan kode sebagai urutan token leksikal. Teknik seperti Term Frequency-Inverse Document Frequency (TF-IDF) dan model pembelajaran dalam seperti CodeBERT termasuk dalam kategori ini.
Metode Berbasis Pohon
Metode berbasis pohon memparse kode menjadi pohon abstrak sintaksis (AST) atau struktur pohon lainnya, menangkap aturan sintaksis dan semantik kode. Contoh termasuk jaringan saraf berbasis pohon dan model seperti code2vec dan ASTNN.
Metode Berbasis Grafik
Metode berbasis grafik membangun grafik dari kode, seperti grafik aliran kontrol (CFG) dan grafik aliran data (DFG), untuk merepresentasikan perilaku dinamis dan ketergantungan kode. GraphCodeBERT adalah contoh yang terkenal.
TransformCode: Kerangka Kerja untuk Pengkodean Kode
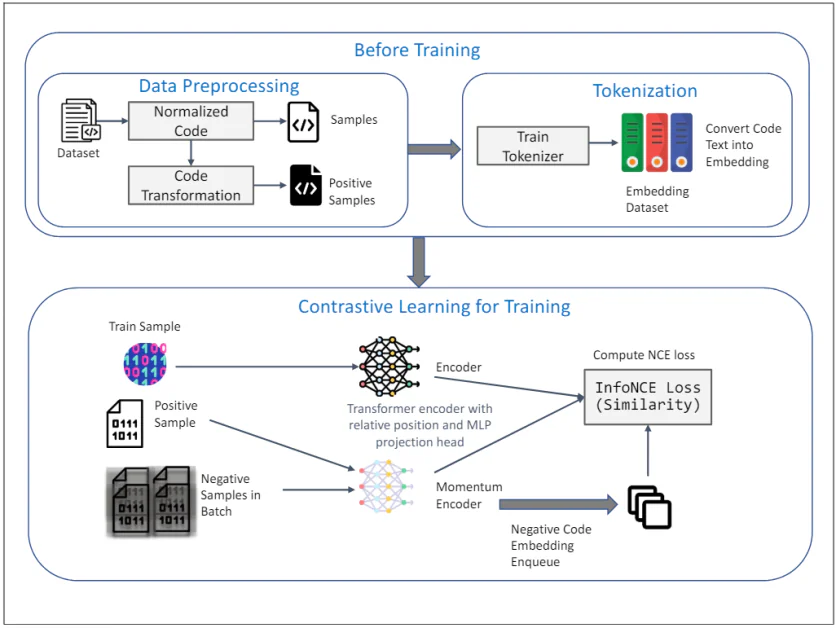
TransformCode: Pembelajaran tak terawasi dari pengkodean kode
TransformCode adalah kerangka kerja yang mengatasi keterbatasan metode yang ada dengan mempelajari pengkodean kode dalam cara pembelajaran kontras. Ini adalah encoder-agnostik dan bahasa-agnostik, yang berarti dapat menggunakan model encoder apa pun dan menangani bahasa pemrograman apa pun.
Diagram di atas menggambarkan kerangka kerja TransformCode untuk pembelajaran tak terawasi dari pengkodean kode menggunakan pembelajaran kontras. Ini terdiri dari dua fase utama: Sebelum Pelatihan dan Pembelajaran Kontras untuk Pelatihan. Berikut adalah penjelasan rinci tentang setiap komponen:
Sebelum Pelatihan
1. Praproses Data:
- Dataset: Input awal adalah dataset yang berisi potongan kode.
- Kode Normal: Potongan kode menjalani normalisasi untuk menghapus komentar dan mengganti nama variabel ke format standar. Ini membantu dalam mengurangi pengaruh penamaan variabel pada proses pembelajaran dan meningkatkan kemampuan generalisasi model.
- Transformasi Kode: Kode yang dinormalisasi kemudian diubah menggunakan berbagai transformasi sintaksis dan semantik untuk menghasilkan sampel positif. Transformasi ini memastikan bahwa makna semantik kode tetap tidak berubah, menyediakan sampel yang beragam dan kuat untuk pembelajaran kontras.
2. Tokenisasi:
- Tokenisasi Pelatihan: Tokenizer dilatih pada dataset kode untuk mengubah teks kode menjadi pengkodean. Ini melibatkan memecah kode menjadi unit yang lebih kecil, seperti token, yang dapat diproses oleh model.
- Dataset Pengkodean: Tokenizer yang dilatih digunakan untuk mengubah seluruh dataset kode menjadi pengkodean, yang berfungsi sebagai input untuk fase pembelajaran kontras.
Pembelajaran Kontras untuk Pelatihan
3. Proses Pelatihan:
- Sampel Pelatihan: Sampel dari dataset pelatihan dipilih sebagai representasi kode pertanyaan.
- Sampel Positif: Sampel positif yang sesuai adalah versi transformasi dari kode pertanyaan, diperoleh selama fase praproses data.
- Sampel Negatif dalam Batch: Sampel negatif adalah semua sampel kode lain dalam batch saat ini yang berbeda dari sampel positif.
4. Encoder dan Encoder Momentum:
- Encoder Transformer dengan Relatif Posisi dan Kepala Proyeksi MLP: Baik sampel pertanyaan dan sampel positif diumpankan ke Encoder Transformer. Encoder ini mencakup pengkodean posisi relatif untuk menangkap struktur sintaksis dan hubungan antara token dalam kode. Kepala proyeksi MLP digunakan untuk memetakan representasi yang dikodekan ke ruang dimensi yang lebih rendah di mana objek pembelajaran kontras diterapkan.
- Encoder Momentum: Encoder momentum juga digunakan, yang diperbarui oleh rata-rata bergerak dari parameter encoder pertanyaan. Ini membantu mempertahankan konsistensi dan keragaman representasi, mencegah keruntuhan kerugian kontras. Sampel negatif dikodekan menggunakan encoder momentum ini dan diantrekan untuk proses pembelajaran kontras.
5. Objek Pembelajaran Kontras:
- Menghitung Kerugian InfoNCE (Kesamaan): Kerugian InfoNCE (Estimasi Kontras Noise) dihitung untuk memaksimalkan kesamaan antara sampel pertanyaan dan sampel positif, sambil meminimalkan kesamaan antara sampel pertanyaan dan sampel negatif. Objek ini memastikan bahwa pengkodean yang dipelajari adalah diskriminatif dan kuat, menangkap kesamaan semantik dari potongan kode.
Kerangka kerja ini sepenuhnya memanfaatkan kekuatan pembelajaran kontras untuk mempelajari pengkodean kode yang bermakna dan kuat dari data yang tidak berlabel. Penggunaan transformasi AST dan encoder momentum lebih lanjut meningkatkan kualitas dan efisiensi representasi yang dipelajari, membuat TransformCode menjadi alat yang kuat untuk berbagai tugas rekayasa perangkat lunak.
Fitur Kunci dari TransformCode
- Fleksibilitas dan Adaptabilitas: Dapat diperluas ke berbagai tugas hilir yang memerlukan representasi kode.
- Efisiensi dan Skalabilitas: Tidak memerlukan model besar atau data pelatihan yang luas, mendukung bahasa pemrograman apa pun.
- Pembelajaran Tak Terawasi dan Terawasi: Dapat diterapkan pada skenario pembelajaran yang berbeda dengan mengintegrasikan label atau objek tugas khusus.
- Parameter yang Dapat Disesuaikan: Jumlah parameter encoder dapat disesuaikan berdasarkan sumber daya komputasi yang tersedia.
TransformCode memperkenalkan teknik augmentasi data yang disebut transformasi AST, menerapkan transformasi sintaksis dan semantik ke potongan kode asli. Ini menghasilkan sampel yang beragam dan kuat untuk pembelajaran kontras.
Aplikasi dari Pengkodean Kode
Pengkodean kode telah merevolusi berbagai aspek rekayasa perangkat lunak dengan mengubah kode dari format teks menjadi representasi numerik yang dapat digunakan oleh model pembelajaran mesin. Berikut adalah beberapa aplikasi kunci:
Pencarian Kode yang Ditingkatkan
Secara tradisional, pencarian kode bergantung pada pencocokan kata kunci, yang sering menghasilkan hasil yang tidak relevan. Pengkodean kode memungkinkan pencarian semantik, di mana potongan kode diperingkat berdasarkan kesamaan fungsionalitas, bahkan jika mereka menggunakan kata kunci yang berbeda. Ini secara signifikan meningkatkan akurasi dan efisiensi menemukan kode relevan dalam basis kode besar.
Penyelesaian Kode yang Lebih Pintar
Alat penyelesaian kode menyarankan potongan kode relevan berdasarkan konteks saat ini. Dengan memanfaatkan pengkodean kode, alat-alat ini dapat menyediakan saran yang lebih akurat dan membantu dengan memahami makna semantik dari kode yang sedang ditulis. Ini diterjemahkan ke pengalaman pengkodean yang lebih cepat dan lebih produktif.
Koreksi Kode Otomatis dan Deteksi Bug
Pengkodean kode dapat digunakan untuk mengidentifikasi pola yang sering menunjukkan bug atau ketidakefisienan dalam kode. Dengan menganalisis kesamaan antara potongan kode dan pola bug yang diketahui, sistem ini dapat secara otomatis menyarankan perbaikan atau menyoroti area yang mungkin memerlukan pemeriksaan lebih lanjut.
Ringkasan Kode yang Ditingkatkan dan Generasi Dokumentasi
Basis kode besar sering kekurangan dokumentasi yang memadai, membuatnya sulit bagi pengembang baru untuk memahami cara kerjanya. Pengkodean kode dapat membuat ringkasan yang ringkas yang menangkap esensi fungsionalitas kode. Ini tidak hanya meningkatkan kemampuan pemeliharaan kode tetapi juga memfasilitasi transfer pengetahuan dalam tim pengembangan.
Ulasan Kode yang Ditingkatkan
Ulasan kode sangat penting untuk mempertahankan kualitas kode. Pengkodean kode dapat membantu reviewer dengan menyoroti masalah potensial dan menyarankan perbaikan. Selain itu, mereka dapat memfasilitasi perbandingan antara versi kode yang berbeda, membuat proses ulasan lebih efisien.
Pengolahan Kode Bahasa Lintas
Dunia pengembangan perangkat lunak tidak terbatas pada satu bahasa pemrograman. Pengkodean kode memiliki potensi untuk memfasilitasi tugas pengolahan kode lintas bahasa. Dengan menangkap hubungan semantik antara kode yang ditulis dalam bahasa yang berbeda, teknik ini dapat memungkinkan tugas seperti pencarian kode dan analisis di seluruh bahasa pemrograman.












