Kecerdasan buatan
AI Membantu Pembicara Gugup untuk ‘Membaca Ruangan’ Selama Konferensi Video

Pada tahun 2013, sebuah survei tentang fobia umum menentukan bahwa prospek berbicara di depan umum adalah lebih buruk daripada prospek kematian bagi sebagian besar responden. Sindrom ini dikenal sebagai glossophobia.
Migrasi yang dipicu COVID dari pertemuan ‘tatap muka’ ke konferensi online di platform seperti Zoom dan Google Spaces telah, secara mengejutkan, tidak memperbaiki situasi. Di mana pertemuan tersebut melibatkan sejumlah besar peserta, kemampuan penilaian ancaman alami kita terganggu oleh baris dan ikon peserta dengan resolusi rendah, serta kesulitan dalam membaca sinyal visual halus dari ekspresi wajah dan bahasa tubuh. Skype, misalnya, telah terbukti sebagai platform yang buruk untuk mengirimkan petunjuk non-verbal.
Dampak pada kinerja berbicara di depan umum dari minat dan respon yang dirasakan telah didokumentasikan dengan baik sekarang, dan secara intuitif jelas bagi sebagian besar dari kita. Respon audiens yang tidak jelas dapat menyebabkan pembicara ragu-ragu dan kembali ke ucapan pengisi, tidak menyadari apakah argumen mereka bertemu dengan persetujuan, kebencian atau ketidakpedulian, sering membuat pengalaman yang tidak nyaman bagi pembicara dan pendengar.
Di bawah tekanan dari pergeseran yang tidak terduga menuju konferensi video online yang dipicu oleh pembatasan dan tindakan pencegahan COVID, masalah ini secara argumentatif semakin buruk, dan sejumlah skema umpan balik audiens yang memperbaiki telah diajukan dalam komunitas visi komputer dan penelitian afek selama beberapa tahun terakhir.
Solusi Berfokus pada Perangkat Keras
Sebagian besar dari ini, bagaimanapun, melibatkan peralatan tambahan atau perangkat lunak yang kompleks yang dapat menimbulkan masalah privasi atau logistik – gaya pendekatan yang relatif mahal atau terbatas sumber daya yang mendahului pandemi. Pada tahun 2001, MIT mengusulkan Galvactivator, sebuah perangkat yang dikenakan di tangan yang menyimpulkan keadaan emosi peserta audiens, diuji selama simposium sehari penuh.

Dari 2001, MIT’s Galvactivator, yang mengukur respon konduktivitas kulit dalam upaya memahami sentimen dan keterlibatan audiens. Sumber: https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
Banyak energi akademis juga telah dikhususkan untuk kemungkinan penerapan ‘pengklik’ sebagai Sistem Respon Audiens (ARS), sebuah langkah untuk meningkatkan partisipasi aktif audiens (yang secara otomatis meningkatkan keterlibatan, karena memaksa pemirsa ke dalam peran node umpan balik aktif), tetapi yang juga telah dianggap sebagai sarana untuk mendorong pembicara.
Upaya lain untuk ‘menghubungkan’ pembicara dan audiens telah termasuk pemantauan denyut jantung, penggunaan peralatan yang kompleks yang dikenakan di tubuh untuk memanfaatkan elektroensefalografi, ‘pengukur sorak’, pengenalan emosi berbasis komputer-vision untuk pekerja meja, dan penggunaan emotikon yang dikirim oleh audiens selama orasi pembicara.

Dari 2017, EngageMeter, sebuah proyek penelitian akademis bersama dari LMU Munich dan Universitas Stuttgart. Sumber: http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
Sebagai sub-penelitian dari bidang analitik audiens yang menguntungkan, sektor swasta telah mengambil minat khusus dalam estimasi dan pelacakan pandangan – sistem di mana setiap anggota audiens (yang mungkin pada gilirannya harus berbicara), tunduk pada pelacakan okular sebagai indeks keterlibatan dan persetujuan.
Semua metode ini cukup memiliki gesekan. Banyak dari mereka memerlukan peralatan tambahan atau perangkat lunak yang kompleks yang dapat menimbulkan masalah privasi atau logistik – pendekatan yang relatif mahal atau terbatas sumber daya yang mendahului pandemi. Oleh karena itu, pengembangan sistem minimalis yang berbasis pada alat umum untuk konferensi video telah menjadi perhatian selama 18 bulan terakhir.
Melaporkan Persetujuan Audiens Secara Tidak Langsung
Untuk tujuan ini, sebuah kolaborasi penelitian baru antara Universitas Tokyo dan Universitas Carnegie Mellon menawarkan sebuah sistem yang dapat memanfaatkan alat konferensi video standar (seperti Zoom) menggunakan hanya situs web yang diaktifkan kamera web dengan perangkat lunak estimasi pose dan pandangan yang ringan. Dengan cara ini, bahkan kebutuhan untuk plugin browser lokal dihindari.
Gerakan anggukan dan perhatian mata pengguna diterjemahkan menjadi data yang diwakili yang divisualisasikan kembali ke pembicara, memungkinkan ‘uji litmus langsung’ seberapa besar konten yang menarik perhatian audiens – dan juga setidaknya sebuah indikator samar dari periode wacana di mana pembicara mungkin kehilangan minat audiens.
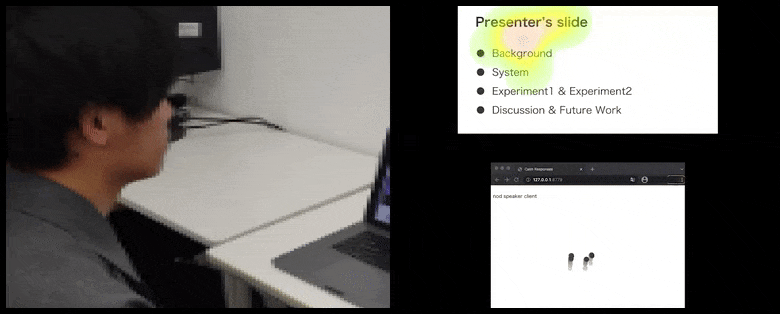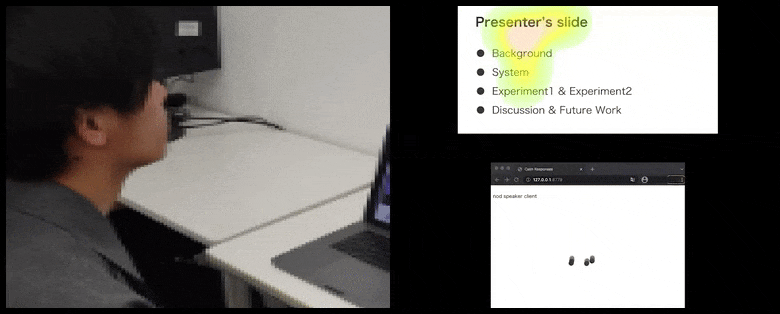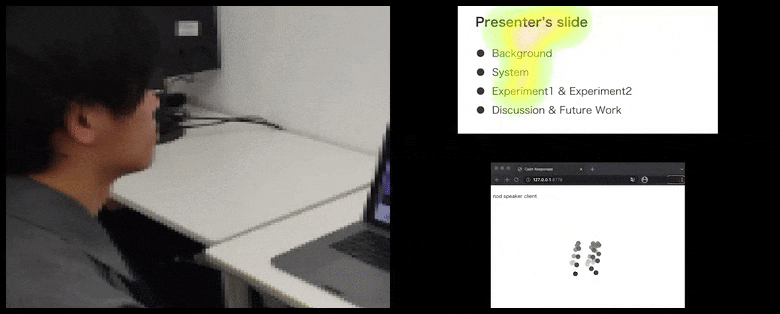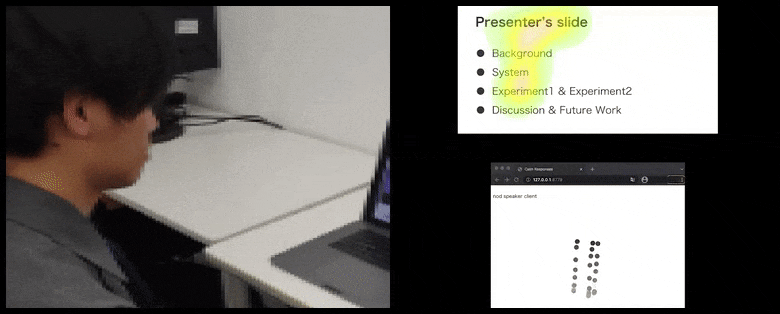
Dengan CalmResponses, perhatian pengguna dan anggukan ditambahkan ke dalam kolam umpan balik audiens dan diterjemahkan menjadi representasi visual yang dapat menguntungkan pembicara. Lihat video tertanam di akhir artikel untuk lebih detail dan contoh. Sumber: https://www.youtube.com/watch?v=J_PhB4FCzk0
Dalam banyak situasi akademis, seperti kuliah online, mahasiswa mungkin tidak terlihat oleh pembicara, karena mereka tidak mengaktifkan kamera web mereka karena kesadaran diri tentang latar belakang atau penampilan mereka saat ini. CalmResponses dapat mengatasi hambatan ini dengan melaporkan apa yang diketahui tentang bagaimana pembicara melihat konten, dan jika mereka mengangguk, tanpa kebutuhan bagi pemirsa untuk mengaktifkan kamera mereka.
Makalah ini berjudul CalmResponses: Menampilkan Reaksi Audiens Kollektif dalam Komunikasi Jarak Jauh, dan merupakan karya bersama antara dua peneliti dari UoT dan satu dari Carnegie Mellon.
Penulis menawarkan demo web langsung, dan telah merilis kode sumber di GitHub.
Kerangka CalmResponses
Minat CalmResponses dalam anggukan, sebagai lawan dari disposisi kepala lainnya, didasarkan pada penelitian (sebagian dari itu berasal dari era Darwin) yang menunjukkan bahwa lebih dari 80% dari semua gerakan kepala pendengar terdiri dari anggukan (bahkan ketika mereka mengekspresikan ketidaksetujuan). Pada saat yang sama, gerakan mata telah terbukti melalui berbagai studi menjadi indeks yang dapat diandalkan dari minat atau keterlibatan.
CalmResponses diimplementasikan dengan HTML, CSS, dan JavaScript, dan terdiri dari tiga subsistem: klien audiens, klien pembicara, dan server. Klien audiens melewati data gerakan mata atau kepala pengguna dari kamera web mereka melalui WebSockets ke platform aplikasi cloud Heroku.

Anggukan audiens divisualisasikan di sebelah kanan dalam gerakan animasi di bawah CalmResponses. Dalam hal ini, visualisasi gerakan tersedia tidak hanya untuk pembicara, tetapi juga untuk seluruh audiens. Sumber: https://arxiv.org/pdf/2204.02308.pdf
Untuk bagian pelacakan mata proyek, peneliti menggunakan WebGazer, sebuah kerangka kerja pelacakan mata berbasis JavaScript yang ringan dan berbasis browser yang dapat berjalan dengan latensi rendah langsung dari sebuah situs web (lihat tautan di atas untuk implementasi web berbasis peneliti sendiri).
Karena kebutuhan implementasi sederhana dan pengenalan respons agregat kasar lebih besar daripada kebutuhan akurasi tinggi dalam estimasi pose dan pandangan, data pose input dihaluskan menurut nilai rata-rata sebelum dipertimbangkan untuk estimasi respons keseluruhan.
Tindakan anggukan dievaluasi melalui perpustakaan JavaScript clmtrackr, yang memasang model wajah ke wajah yang terdeteksi dalam gambar atau video melalui pergeseran rata-rata landmark yang diatur. Untuk tujuan ekonomi dan latensi rendah, hanya landmark yang terdeteksi untuk hidung yang secara aktif dipantau dalam implementasi penulis, karena ini cukup untuk melacak tindakan anggukan.
Gerakan ujung hidung pengguna menciptakan jejak yang berkontribusi pada kolam respons audiens terkait anggukan, divisualisasikan dengan cara agregat kepada semua peserta.
Peta Panas
Sementara aktivitas anggukan direpresentasikan oleh titik bergerak dinamis (lihat gambar di atas dan video di akhir), perhatian visual dilaporkan dalam bentuk peta panas yang menunjukkan kepada pembicara dan audiens di mana fokus perhatian umum terletak pada layar presentasi atau lingkungan konferensi video yang dibagikan.

Semua peserta dapat melihat di mana perhatian pengguna umum terfokus. Makalah ini tidak menyebutkan apakah fungsionalitas ini tersedia ketika pengguna dapat melihat ‘galeri’ peserta lain, yang dapat mengungkap fokus palsu pada peserta tertentu, karena berbagai alasan.
Uji Coba
Dua lingkungan uji dibentuk untuk CalmResponses dalam bentuk studi ablasio implisit, menggunakan tiga set keadaan yang berbeda: dalam ‘Kondisi B’ (baseline), penulis mereplikasi kuliah online biasa, di mana sebagian besar mahasiswa mematikan kamera web mereka, dan pembicara tidak memiliki kemampuan untuk melihat wajah audiens; dalam ‘Kondisi CR-E’, pembicara dapat melihat umpan balik pandangan (peta panas); dalam ‘Kondisi CR-N’, pembicara dapat melihat baik aktivitas anggukan maupun pandangan dari audiens.
Skenario eksperimental pertama terdiri dari kondisi B dan kondisi CR-E; skenario kedua terdiri dari kondisi B dan kondisi CR-N. Umpan balik diperoleh dari kedua pembicara dan audiens.
Dalam setiap eksperimen, tiga faktor dievaluasi: evaluasi objektif dan subjektif presentasi (termasuk kuesioner yang dilaporkan sendiri oleh pembicara tentang perasaan mereka tentang bagaimana presentasi berjalan); jumlah kejadian ‘ucapan pengisi’, yang menunjukkan ketidakpastian dan keraguan sesaat; dan komentar kualitatif. Kriteria ini adalah umum estimator kualitas ucapan dan kecemasan pembicara.
Kolam uji terdiri dari 38 orang berusia 19-44, yang terdiri dari 29 laki-laki dan sembilan perempuan dengan usia rata-rata 24,7, semua orang Jepang atau Tionghoa, dan semua fasih dalam bahasa Jepang. Mereka dibagi secara acak menjadi lima kelompok 6-7 peserta, dan tidak ada subjek yang mengenal satu sama lain secara pribadi.
Uji coba dilakukan di Zoom, dengan lima pembicara memberikan presentasi dalam eksperimen pertama dan enam dalam eksperimen kedua.

Kondisi pengisi ditandai sebagai kotak oranye. Secara umum, konten pengisi jatuh dalam proporsi yang wajar terhadap umpan balik audiens yang meningkat dari sistem.
Peneliti mencatat bahwa pengisi salah satu pembicara berkurang secara signifikan, dan bahwa dalam ‘Kondisi CR-N’, pembicara jarang mengucapkan frasa pengisi. Lihat makalah untuk hasil yang sangat terperinci dan granular yang dilaporkan; namun, hasil yang paling mencolok adalah dalam evaluasi subjektif dari pembicara dan peserta audiens.
Komentar dari audiens termasuk:
‘Saya merasa saya terlibat dalam presentasi” [AN2], “Saya tidak yakin pidato pembicara diperbaiki, tetapi saya merasa kesatuan dari visualisasi gerakan kepala orang lain.’ [AN6]
‘Saya tidak yakin pidato pembicara diperbaiki, tetapi saya merasa kesatuan dari visualisasi gerakan kepala orang lain.’
Peneliti mencatat bahwa sistem ini memperkenalkan jenis jeda buatan baru ke dalam presentasi pembicara, karena pembicara cenderung merujuk pada sistem visual untuk menilai umpan balik audiens sebelum melanjutkan lebih jauh.
Mereka juga mencatat efek ‘jas labcoat’, sulit dihindari dalam keadaan eksperimental, di mana beberapa peserta merasa terbatas oleh kemungkinan implikasi keamanan dari dipantau untuk data biometrik.
Kesimpulan
Salah satu kelebihan yang cukup mencolok dalam sistem seperti ini adalah semua teknologi tambahan non-standar yang diperlukan untuk pendekatan ini sepenuhnya menghilang setelah penggunaannya selesai. Tidak ada plugin browser residual yang perlu dicopot, atau untuk memunculkan keraguan dalam pikiran peserta tentang apakah mereka harus tetap berada di sistem mereka masing-masing; dan tidak ada kebutuhan untuk memandu pengguna melalui proses instalasi (meskipun kerangka kerja berbasis web memerlukan satu atau dua menit kalibrasi awal oleh pengguna), atau untuk menavigasi kemungkinan pengguna tidak memiliki izin yang memadai untuk menginstal perangkat lunak lokal, termasuk add-on dan ekstensi berbasis browser.
Meskipun gerakan wajah dan mata yang dievaluasi tidak seakurat yang mungkin dalam keadaan di mana kerangka kerja mesin pembelajaran lokal yang didedikasikan (seperti seri YOLO) mungkin digunakan, pendekatan hampir tanpa gesekan ini untuk evaluasi audiens menyediakan akurasi yang cukup untuk analisis sentimen dan sikap agregat dalam skenario konferensi video yang khas. Di atas semua, ini sangat murah.
Lihat video proyek yang terkait di bawah untuk detail dan contoh lebih lanjut.
Dipublikasikan pertama kali pada 11 April 2022.












