
Mesterséges Intelligencia
Befolyásos adathalmazok kartellje uralja a gépi tanulási kutatást – derül ki az új tanulmányból
A Kaliforniai Egyetem és a Google Research új tanulmánya megállapította, hogy kis számú „benchmark” gépi tanulási adatkészlet, amelyek nagyrészt befolyásos nyugati intézményektől és gyakran kormányzati szervezetektől származnak, egyre inkább uralják az AI-kutatási szektort.
A kutatók arra a következtetésre jutottak, hogy ez a tendencia „alapértelmezett” a rendkívül népszerű nyílt forráskódú adatkészletekhez, mint pl ImageNet, számos gyakorlati, etikai, sőt politikai aggodalomra ad okot.
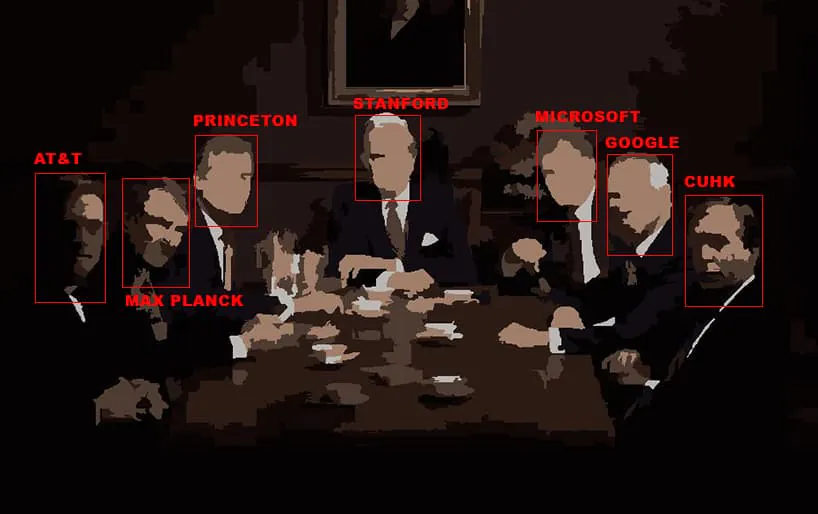
Megállapításaik között – a Facebook által vezetett közösségi projekt alapadatai alapján Papírok kóddal (PWC) – állítják a szerzők „A széles körben használt adatkészleteket csak néhány elit intézmény vezeti be”, és ez a „konszolidáció” az elmúlt években 80%-ra nőtt.
"[Azt találjuk], hogy világszerte egyre nagyobb az egyenlőtlenség az adatkészlet-használatban, és a 50 43,140 fős mintánkban szereplő összes adatkészlet-használat több mint XNUMX%-a tizenkét elit, elsősorban nyugati intézmény által bevezetett adatkészleteknek felelt meg."

Az elmúlt tíz év nem feladatspecifikus adatkészlet-használatainak térképe. A felvétel kritériuma, ha az intézmény vagy vállalat az ismert felhasználások több mint 50%-át képviseli. Jobbra látható a Gini-együttható az adatkészletek időbeli koncentrációjához mind az intézmények, mind az adatkészletek esetében. Forrás: https://arxiv.org/pdf/2112.01716.pdf
A domináns intézmények közé tartozik a Stanford Egyetem, a Microsoft, a Princeton, a Facebook, a Google, a Max Planck Institute és az AT&T. A tíz legfontosabb adatkészlet-forrásból négy vállalati intézmény.
A cikk ezen elit adatkészletek növekvő használatát is jellemzi, mint „az egyenlőtlenség eszköze a tudományban”. Ennek az az oka, hogy a közösségi jóváhagyást kereső kutatócsoportok motiváltabbak a legkorszerűbb (SOTA) eredmények elérésére konzisztens adatkészlettel szemben, mint az eredeti adatkészletek létrehozása, amelyek nem rendelkeznek ilyen minősítéssel, és amelyekhez alkalmazkodniuk kellene az újdonságokhoz. mérőszámok szabványos indexek helyett.
Mindenesetre, amint azt a lap elismeri, a saját adatkészlet létrehozása megfizethetetlenül költséges tevékenység a kevésbé jó forrásokkal rendelkező intézmények és csapatok számára.
"A első frakció A SOTA benchmarking által biztosított tudományos érvényességet általában összekeverik azzal a társadalmi hitelességgel, amelyet a kutatók azáltal szereznek, hogy megmutatják, képesek versenyezni egy széles körben elismert adathalmazon, még akkor is, ha egy kontextus-specifikus benchmark technikailag megfelelőbb lenne.
„Úgy véljük, hogy ez a dinamika „Máté-effektust” hoz létre (azaz „a gazdagok gazdagodnak, a szegények szegényebbek”), ahol a sikeres benchmarkok és az azokat bevezető elit intézmények túlméretezettek a területen.
A papír címet viseli Csökkentett, újrafelhasznált és újrahasznosított: Egy adatkészlet élete a gépi tanulási kutatásban, Bernard Koch és Jacob G. Foster a UCLA-n, valamint Emily Denton és Alex Hanna a Google Researchtől.
A munka számos problémát vet fel a konszolidáció növekvő tendenciájával kapcsolatban, amelyet dokumentál, és ezzel találkoztak is általános helyeslés az Open Review-nál. A NeurIPS 2021 egyik bírálója megjegyezte, hogy a munka az „rendkívül fontos mindenki számára, aki részt vesz a gépi tanulási kutatásban.” és előre látta, hogy az egyetemi kurzusokon hozzárendelt olvasmányként szerepel.
A szükségszerűségtől a korrupcióig
A szerzők megjegyzik, hogy a „beat-the-benchmark” jelenlegi kultúrája orvosságként jelent meg az objektív értékelési eszközök hiányára, ami miatt a mesterséges intelligencia iránti érdeklődés és befektetés másodszor is összeomlott. több mint harminc évvel ezelőtt, miután csökkent az üzleti lelkesedés az „Expert Systems” új kutatások iránt:
„A benchmarkok általában egy adott feladatot formalizálnak egy adatkészleten és egy hozzá tartozó mennyiségi értékelési mérőszámon keresztül. Ezt a gyakorlatot eredetileg az 1980-as évek „AI tél” után vezették be a [gépi tanulási kutatásba] állami finanszírozók, akik igyekeztek pontosabban felmérni a támogatások értékét.
A cikk azzal érvel, hogy a szabványosítás informális kultúrájának kezdeti előnyeit (a részvételi korlátok csökkentése, következetes mérőszámok és agilisabb fejlesztési lehetőségek) kezdik felülmúlni azok a hátrányok, amelyek természetesen akkor jelentkeznek, amikor egy adathalmaz elég erős ahhoz, hogy hatékonyan meghatározza „használati feltételek” és befolyási kör.
A szerzők azt javasolják – összhangban az üggyel kapcsolatos közelmúltbeli iparági és akadémiai gondolatokkal –, hogy a kutatói közösség már nem jelent újszerű problémákat ha ezek nem kezelhetők a meglévő benchmark adatkészleteken keresztül.
Ezenkívül megjegyzik, hogy a kis számú „arany” adatkészlet vak ragaszkodása arra ösztönzi a kutatókat, hogy olyan eredményeket érjenek el. túl felszerelt (azaz adatkészlet-specifikusak, és nem valószínű, hogy a való világ adatain, új tudományos vagy eredeti adatkészleteken, vagy akár szükségszerűen az „arany standard” különböző adatkészletein nem teljesítenek olyan jól).
"Tekintettel arra, hogy a kutatások kevés számú benchmark adatkészletre koncentrálódnak, úgy gondoljuk, hogy az értékelési formák diverzifikálása különösen fontos, hogy elkerüljük a meglévő adatkészletekhez való túlillesztést és a területen elért előrehaladás félrevezetését."
Kormányzati befolyás a számítógépes látáskutatásban
A cikk szerint a Computer Vision kutatást lényegesen jobban érinti az általa felvázolt szindróma, mint más ágazatokat, és a szerzők megjegyzik, hogy a Natural Language Processing (NLP) kutatás sokkal kevésbé érintett. A szerzők szerint ennek az az oka, hogy az NLP közösségek ilyenek "koherensebb" és nagyobb méretben, valamint azért, mert az NLP-adatkészletek elérhetőbbek és könnyebben kezelhetők, valamint kisebbek és kevésbé erőforrásigényesek az adatgyűjtés szempontjából.
A Computer Vision területén, és különösen az arcfelismerés (FR) adatkészleteivel kapcsolatban a szerzők azt állítják, hogy a vállalati, állami és magánérdekek gyakran ütköznek:
„A vállalati és kormányzati intézményeknek vannak olyan céljaik, amelyek összeütközésbe kerülhetnek a magánélet védelmével (pl. megfigyelés), és ezeknek a prioritásoknak a súlyozása valószínűleg eltér az akadémikusok vagy a mesterséges intelligencia tágabb társadalmi érdekelt feleiétől.
Az arcfelismerési feladatoknál a kutatók azt találták, hogy a tisztán tudományos adatkészletek előfordulása drámaian csökken az átlaghoz képest:
„A nyolc adatkészletből [négyet] (az összes felhasználás 33.69%-a) kizárólag vállalatok, az amerikai hadsereg vagy a kínai kormány finanszírozott (MS-Celeb-1M, CASIA-Webface, IJB-A, VggFace2). Az MS-Celeb-1M-et végül visszavonták, mert vita alakult ki a különböző érdekelt felek magánéletének értékével kapcsolatban.

A képgenerálási és arcfelismerési kutatóközösségekben használt legnépszerűbb adatkészletek.
A fenti grafikonon, amint azt a szerzők megjegyzik, azt is látjuk, hogy a képgenerálás (vagy képszintézis) viszonylag új keletű területe erősen támaszkodik a meglévő, jóval régebbi adatkészletekre, amelyeket nem erre a célra szántak.
Valójában a tanulmány azt a növekvő tendenciát figyeli meg, hogy az adatkészletek „elvándorolnak” a céljuktól, megkérdőjelezve az új vagy távoli kutatási ágazatok igényeire való alkalmasságukat, valamint azt, hogy a költségvetési korlátok milyen mértékben „általánosíthatják” az adathalmazokat. A kutatók ambícióinak hatókörét a rendelkezésre álló anyagok és az évről évre mért benchmark értékelések annyira megszállottja által biztosított szűkebb keretek közé helyezik, hogy az új adatkészletek nehezen nyernek teret.
„Eredményeink azt is jelzik, hogy az adatkészletek rendszeresen cserélődnek a különböző feladatközösségek között. A legszélsőségesebb esetben az egyes feladatközösségekhez forgalomban lévő benchmark adatkészletek többségét más feladatokhoz hozták létre.
Ami a gépi tanulási világítótesteket illeti (köztük Andrew Ng), akik az utóbbi években egyre inkább az adathalmazok diverzifikációját és gondozását szorgalmazták, a szerzők támogatják ezt az érzést, de úgy vélik, hogy ezt a fajta erőfeszítést, még ha sikeres is, potenciálisan alááshatja a jelenlegi kultúra SOTA-eredményektől és megalapozott adatkészletektől való függése. :
„Kutatásunk azt sugallja, hogy pusztán felkérni az ML-kutatókat több adatkészlet fejlesztésére, valamint az ösztönző struktúrák megváltoztatása, hogy az adatkészletek fejlesztését értékeljék és jutalmazzák, nem biztos, hogy elegendő az adatkészlet-használat diverzifikálásához és az MLR-kutatási menetrendeket végső soron alakító és meghatározó perspektívákhoz.
„Amellett, hogy ösztönözzük az adatkészletek fejlesztését, olyan méltányosság-orientált politikai beavatkozásokat szorgalmazunk, amelyek a kevésbé erőforrásokkal rendelkező intézményekben dolgozók jelentős finanszírozását helyezik előtérbe a jó minőségű adatkészletek létrehozása érdekében. Ez – társadalmi és kulturális szempontból – diverzifikálná a modern ML módszerek értékelésére használt benchmark adatkészleteket.
6. december 2021., 4:49 GMT+2 – Javított birtokos a címsorban. – MA













