AI 101
ओवरफिटिंग क्या है?
ओवरफिटिंग क्या है?
जब आप एक न्यूरल नेटवर्क को प्रशिक्षित करते हैं, तो आपको ओवरफिटिंग से बचना होता है। ओवरफिटिंग मशीन लर्निंग और सांख्यिकी में एक समस्या है जहां एक मॉडल प्रशिक्षण डेटासेट के पैटर्न को बहुत अच्छी तरह से सीखता है, प्रशिक्षण डेटा सेट को पूरी तरह से समझाता है लेकिन अन्य डेटा सेट पर अपनी भविष्यवाणी शक्ति को सामान्य बनाने में विफल रहता है।
इसे दूसरे तरीके से कहें, तो ओवरफिटिंग मॉडल के मामले में, यह अक्सर प्रशिक्षण डेटासेट पर बहुत उच्च सटीकता दिखाएगा, लेकिन भविष्य में मॉडल के माध्यम से चलाए जाने वाले डेटा पर कम सटीकता। यह ओवरफिटिंग की एक त्वरित परिभाषा है, लेकिन आइए ओवरफिटिंग की अवधारणा को विस्तार से देखें। आइए देखें कि ओवरफिटिंग कैसे होती है और इसे कैसे避ित किया जा सकता है।
“फिट” और अंडरफिटिंग को समझना
ओवरफिटिंग पर चर्चा करते समय अंडरफिटिंग और “फिट” की अवधारणा को देखना मददगार है। जब हम एक मॉडल को प्रशिक्षित करते हैं, तो हम एक फ्रेमवर्क विकसित करने का प्रयास करते हैं जो डेटासेट में आइटम की प्रकृति या वर्ग की भविष्यवाणी करने में सक्षम हो, जो आइटम को वर्णित करने वाली विशेषताओं के आधार पर। एक मॉडल को डेटासेट में एक पैटर्न की व्याख्या करने और इस पैटर्न के आधार पर भविष्य के डेटा बिंदुओं की कक्षाओं की भविष्यवाणी करने में सक्षम होना चाहिए। प्रशिक्षण सेट की विशेषताओं के बीच संबंध की व्याख्या करने में मॉडल जितना बेहतर होगा, हमारा मॉडल उतना ही अधिक “फिट” होगा।

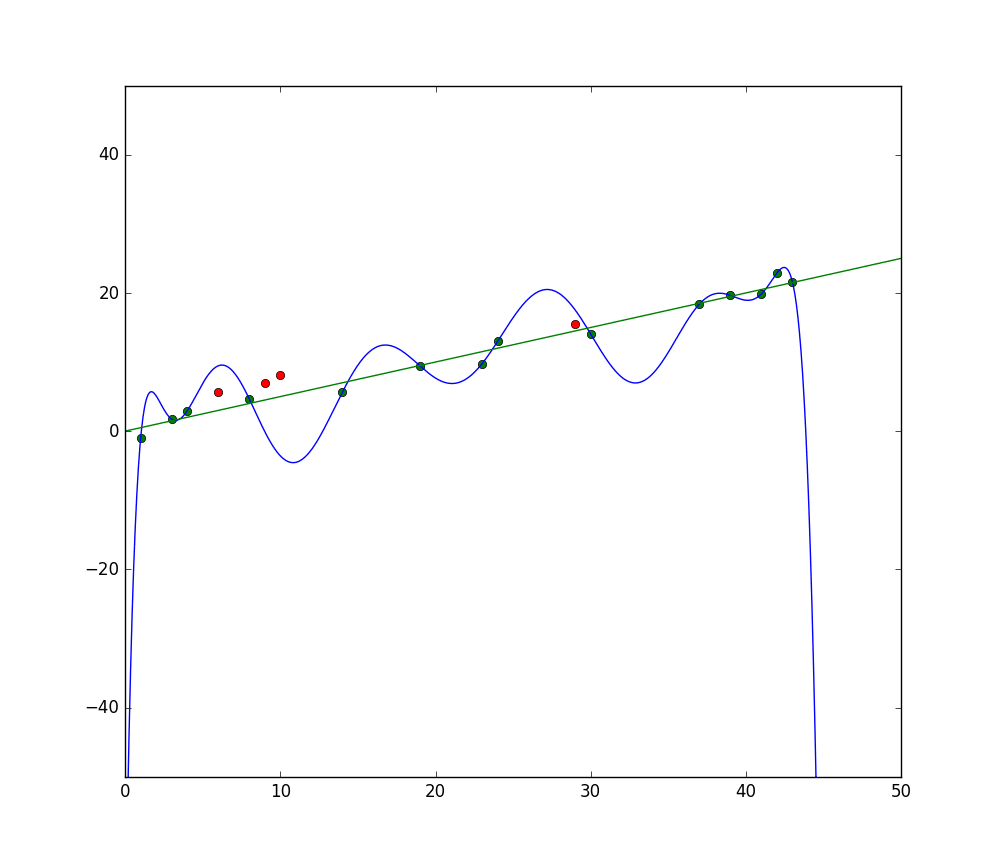
नीली रेखा एक मॉडल की भविष्यवाणियों को दर्शाती है जो अंडरफिटिंग कर रहा है, जबकि हरी रेखा एक बेहतर फिट मॉडल को दर्शाती है। फोटो: पेप रोका विकिमीडिया कॉमन्स के माध्यम से, सीसी बाय एसए 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvilínia.svg)
एक मॉडल जो प्रशिक्षण डेटा और इसकी विशेषताओं के बीच संबंध की व्याख्या करने में असफल रहता है और इसलिए भविष्य के डेटा उदाहरणों को सटीक रूप से वर्गीकृत करने में विफल रहता है, वह अंडरफिटिंग कर रहा है। यदि आप एक मॉडल की भविष्यवाणी की गई संबंध को वास्तविक मूल्यों के खिलाफ ग्राफ कर रहे थे, तो भविष्यवाणियां चिह्न से भटक जाएंगी। यदि हमारे पास एक ग्राफ था जिसमें प्रशिक्षण सेट के वास्तविक मान लेबल किए गए थे, तो एक गंभीर रूप से अंडरफिटिंग मॉडल अधिकांश डेटा बिंदुओं को बहुत अधिक याद करेगा। एक बेहतर फिट वाला मॉडल डेटा बिंदुओं के माध्यम से एक पथ काट सकता है, जिसमें प्रत्येक डेटा बिंदु भविष्यवाणी किए गए मूल्यों से केवल थोड़ा भिन्न होता है।
अंडरफिटिंग अक्सर तब होती है जब सटीक मॉडल बनाने के लिए पर्याप्त डेटा नहीं होता है, या जब गैर-रेखीय डेटा के साथ एक रेखीय मॉडल डिज़ाइन करने का प्रयास किया जाता है। अधिक प्रशिक्षण डेटा या अधिक विशेषताएं अक्सर अंडरफिटिंग को कम करने में मदद कर सकती हैं।
तो क्यों नहीं हम एक मॉडल बनाते हैं जो प्रशिक्षण डेटा के हर बिंदु को पूरी तरह से समझा सकता है? निश्चित रूप से पूर्ण सटीकता वांछनीय है? एक मॉडल बनाना जो प्रशिक्षण डेटा के पैटर्न को बहुत अच्छी तरह से सीखता है, वही ओवरफिटिंग का कारण बनता है। प्रशिक्षण डेटा सेट और भविष्य में मॉडल के माध्यम से चलाए जाने वाले डेटा सेट एक जैसे नहीं होंगे। वे कई मामलों में बहुत समान हो सकते हैं, लेकिन वे कुछ महत्वपूर्ण तरीकों से भिन्न होंगे। इसलिए, एक मॉडल डिज़ाइन करना जो प्रशिक्षण डेटासेट को पूरी तरह से समझाता है, इसका मतलब है कि आप एक सिद्धांत के साथ समाप्त होते हैं जो विशेषताओं के बीच संबंध के बारे में है जो अन्य डेटासेट पर सामान्य नहीं होता है।
ओवरफिटिंग को समझना
ओवरफिटिंग तब होती है जब एक मॉडल प्रशिक्षण डेटासेट के विवरण को बहुत अच्छी तरह से सीखता है, जिससे मॉडल बाहरी डेटा पर भविष्यवाणियां करने में असफल हो जाता है। यह तब हो सकता है जब मॉडल न केवल डेटासेट की विशेषताओं को सीखता है, बल्कि डेटासेट में यादृच्छिक उतार-चढ़ाव या शोर को भी सीखता है, और इन यादृच्छिक/गैर-महत्वपूर्ण घटनाओं पर महत्व रखता है।
ओवरफिटिंग गैर-रेखीय मॉडल का उपयोग करते समय अधिक होने की संभावना है, क्योंकि वे डेटा विशेषताओं को सीखने में अधिक लचीले होते हैं। गैर-पैरामीट्रिक मशीन लर्निंग एल्गोरिदम में अक्सर विभिन्न पैरामीटर और तकनीकें होती हैं जिन्हें मॉडल की संवेदनशीलता को डेटा के प्रति सीमित करने और इस प्रकार ओवरफिटिंग को कम करने के लिए लागू किया जा सकता है। उदाहरण के लिए, निर्णय पेड़ मॉडल ओवरफिटिंग के प्रति बहुत संवेदनशील होते हैं, लेकिन एक तकनीक जिसे प्रूनिंग कहा जाता है, का उपयोग मॉडल द्वारा सीखे गए विवरण के कुछ हिस्से को यादृच्छिक रूप से हटाने के लिए किया जा सकता है।
यदि आप मॉडल की भविष्यवाणियों को एक्स और वाई अक्षों पर ग्राफ कर रहे थे, तो आपके पास एक भविष्यवाणी रेखा होगी जो आगे और पीछे ज zurती है, जो यह दर्शाती है कि मॉडल ने सभी बिंदुओं को अपनी व्याख्या में फिट करने की कोशिश की है।
ओवरफिटिंग को नियंत्रित करना
जब हम एक मॉडल को प्रशिक्षित करते हैं, तो हम आदर्श रूप से चाहते हैं कि मॉडल कोई त्रुटि न करे। जब मॉडल का प्रदर्शन प्रशिक्षण डेटासेट में सभी डेटा बिंदुओं पर सही भविष्यवाणियां करने की ओर अभिसरण करता है, तो फिट बेहतर हो रहा है। एक अच्छा फिट वाला मॉडल प्रशिक्षण डेटासेट को ओवरफिटिंग किए बिना लगभग सभी को समझाने में सक्षम है।
एक मॉडल के प्रशिक्षण के दौरान इसका प्रदर्शन समय के साथ सुधरता है। मॉडल की त्रुटि दर प्रशिक्षण समय के साथ घटती है, लेकिन यह केवल एक निश्चित बिंदु तक ही घटती है। वह बिंदु जहां मॉडल का प्रदर्शन परीक्षण सेट पर फिर से बढ़ना शुरू हो जाता है, आमतौर पर वह बिंदु होता है जहां ओवरफिटिंग होने लगती है। मॉडल के लिए सबसे अच्छा फिट प्राप्त करने के लिए, हम मॉडल को प्रशिक्षण सेट पर न्यूनतम नुकसान पर रोकना चाहते हैं, त्रुटि बढ़ने से पहले। प्रशिक्षण समय के दौरान मॉडल के प्रदर्शन को ग्राफ करके और नुकसान न्यूनतम होने पर प्रशिक्षण को रोककर ऑप्टिमल स्टॉपिंग पॉइंट का निर्धारण किया जा सकता है। हालांकि, इस ओवरफिटिंग को नियंत्रित करने के तरीके के साथ एक जोखिम यह है कि परीक्षण प्रदर्शन के आधार पर प्रशिक्षण के अंत बिंदु को निर्दिष्ट करने का अर्थ है कि परीक्षण डेटा प्रशिक्षण प्रक्रिया में शामिल हो जाता है और यह पूरी तरह से “अनजान” डेटा की अपनी स्थिति खो देता है।
ओवरफिटिंग से निपटने के कुछ अलग तरीके हैं। ओवरफिटिंग को कम करने का एक तरीका है रीसैंपलिंग टैक्टिक का उपयोग करना, जो मॉडल की सटीकता का अनुमान लगाने का काम करता है। आप एक वैधीकरण डेटासेट का भी उपयोग कर सकते हैं और परीक्षण डेटासेट के बजाय प्रशिक्षण सटीकता के खिलाफ वैधीकरण सेट की तुलना कर सकते हैं। यह आपके परीक्षण डेटासेट को अनदेखा रखता है। एक लोकप्रिय रीसैंपलिंग विधि के-फोल्ड क्रॉस-वैलिडेशन है। यह तकनीक आपको अपने डेटा को उप-सेट में विभाजित करने की अनुमति देती है जिस पर मॉडल को प्रशिक्षित किया जाता है, और फिर मॉडल के प्रदर्शन का विश्लेषण बाहरी डेटा पर इसके प्रदर्शन का अनुमान लगाने के लिए किया जाता है।
क्रॉस-वैलिडेशन का उपयोग करना मॉडल की सटीकता का अनुमान लगाने के सर्वोत्तम तरीकों में से एक है, और जब इसे एक वैधीकरण डेटासेट के साथ जोड़ा जाता है, तो ओवरफिटिंग को अक्सर न्यूनतम किया जा सकता है।








