
एआई 101
आयामी कमी क्या है?
आयामी कमी क्या है?
आयाम में कमी यह एक ऐसी प्रक्रिया है जिसका उपयोग डेटासेट की आयामीता को कम करने, कई विशेषताओं को लेने और उन्हें कम सुविधाओं के रूप में प्रस्तुत करने के लिए किया जाता है। उदाहरण के लिए, आयामीता में कमी का उपयोग बीस सुविधाओं के डेटासेट को केवल कुछ सुविधाओं तक कम करने के लिए किया जा सकता है। आयामीता में कमी का प्रयोग आमतौर पर किया जाता है अप्रकाशित शिक्षा कई सुविधाओं में से स्वचालित रूप से कक्षाएं बनाने का कार्य। बेहतर ढंग से समझने के लिए आयामीता में कमी का उपयोग क्यों और कैसे किया जाता है, हम उच्च आयामी डेटा से जुड़ी समस्याओं और आयामीता को कम करने के सबसे लोकप्रिय तरीकों पर एक नज़र डालेंगे।
अधिक आयाम ओवरफिटिंग की ओर ले जाते हैं
आयामीता एक डेटासेट के भीतर सुविधाओं/स्तंभों की संख्या को संदर्भित करती है।
अक्सर यह माना जाता है कि मशीन लर्निंग में अधिक सुविधाएँ बेहतर होती हैं, क्योंकि यह अधिक सटीक मॉडल बनाती है। हालाँकि, अधिक सुविधाएँ आवश्यक रूप से बेहतर मॉडल में तब्दील नहीं होती हैं।
डेटासेट की विशेषताएं मॉडल के लिए कितनी उपयोगी हैं, इसके संदर्भ में व्यापक रूप से भिन्न हो सकती हैं, कई विशेषताएं कम महत्व की होती हैं। इसके अलावा, डेटासेट में जितनी अधिक सुविधाएँ होंगी, यह सुनिश्चित करने के लिए उतने ही अधिक नमूनों की आवश्यकता होगी कि सुविधाओं के विभिन्न संयोजन डेटा के भीतर अच्छी तरह से दर्शाए गए हों। इसलिए, नमूनों की संख्या सुविधाओं की संख्या के अनुपात में बढ़ जाती है। अधिक नमूने और अधिक सुविधाओं का मतलब है कि मॉडल को अधिक जटिल होने की आवश्यकता है, और जैसे-जैसे मॉडल अधिक जटिल होते जाते हैं वे ओवरफिटिंग के प्रति अधिक संवेदनशील होते जाते हैं। मॉडल प्रशिक्षण डेटा में पैटर्न को बहुत अच्छी तरह से सीखता है और यह नमूना डेटा से बाहर सामान्यीकरण करने में विफल रहता है।
किसी डेटासेट की आयामीता को कम करने के कई लाभ हैं। जैसा कि उल्लेख किया गया है, सरल मॉडल में ओवरफिटिंग की संभावना कम होती है, क्योंकि मॉडल को इस बारे में कम धारणाएँ बनानी पड़ती हैं कि सुविधाएँ एक-दूसरे से कैसे संबंधित हैं। इसके अलावा, कम आयामों का मतलब है कि एल्गोरिदम को प्रशिक्षित करने के लिए कम कंप्यूटिंग शक्ति की आवश्यकता होती है। इसी प्रकार, छोटे आयाम वाले डेटासेट के लिए कम संग्रहण स्थान की आवश्यकता होती है। डेटासेट की आयामीता को कम करने से आप ऐसे एल्गोरिदम का उपयोग भी कर सकते हैं जो कई सुविधाओं वाले डेटासेट के लिए अनुपयुक्त हैं।
सामान्य आयाम न्यूनीकरण विधियाँ
आयामीता में कमी फीचर चयन या फीचर इंजीनियरिंग द्वारा हो सकती है। फीचर चयन वह जगह है जहां इंजीनियर डेटासेट की सबसे प्रासंगिक सुविधाओं की पहचान करता है इंजीनियरिंग की सुविधा अन्य विशेषताओं को संयोजित या परिवर्तित करके नई सुविधाएँ बनाने की प्रक्रिया है।
फ़ीचर चयन और इंजीनियरिंग प्रोग्रामेटिक रूप से या मैन्युअल रूप से किया जा सकता है। मैन्युअल रूप से सुविधाओं का चयन और इंजीनियरिंग करते समय, सुविधाओं और वर्गों के बीच सहसंबंध खोजने के लिए डेटा को विज़ुअलाइज़ करना सामान्य है। इस तरह से आयामीता में कमी लाने में काफी समय लग सकता है और इसलिए आयामीता को कम करने के कुछ सबसे सामान्य तरीकों में पाइथॉन के लिए स्किकिट-लर्न जैसे पुस्तकालयों में उपलब्ध एल्गोरिदम का उपयोग शामिल है। इन सामान्य आयामीता कटौती एल्गोरिदम में शामिल हैं: प्रिंसिपल कंपोनेंट एनालिसिस (पीसीए), सिंगुलर वैल्यू डीकंपोजिशन (एसवीडी), और लीनियर डिस्क्रिमिनेंट एनालिसिस (एलडीए)।
बिना पर्यवेक्षित शिक्षण कार्यों के लिए आयामीता में कमी में उपयोग किए जाने वाले एल्गोरिदम आमतौर पर पीसीए और एसवीडी होते हैं, जबकि पर्यवेक्षित शिक्षण आयामीता में कमी के लिए उपयोग किए जाने वाले एल्गोरिदम आमतौर पर एलडीए और पीसीए होते हैं। पर्यवेक्षित शिक्षण मॉडल के मामले में, नव निर्मित सुविधाओं को केवल मशीन लर्निंग क्लासिफायरियर में फीड किया जाता है। ध्यान रखें कि यहां वर्णित उपयोग केवल सामान्य उपयोग के मामले हैं और न केवल ऐसी स्थितियाँ जिनमें इन तकनीकों का उपयोग किया जा सकता है। ऊपर वर्णित आयामी कमी एल्गोरिदम केवल सांख्यिकीय तरीके हैं और उनका उपयोग मशीन लर्निंग मॉडल के बाहर किया जाता है।
प्रमुख कंपोनेंट विश्लेषण

फोटो: प्रमुख घटकों के साथ मैट्रिक्स की पहचान की गई
प्रधान घटक विश्लेषण (पीसीए) एक सांख्यिकीय पद्धति है जो डेटासेट की विशेषताओं/विशेषताओं का विश्लेषण करती है और उन विशेषताओं का सारांश प्रस्तुत करती है जो सबसे प्रभावशाली हैं। डेटासेट की विशेषताओं को एक साथ अभ्यावेदन में संयोजित किया जाता है जो डेटा की अधिकांश विशेषताओं को बनाए रखता है लेकिन कम आयामों में फैला होता है। आप इसे डेटा को उच्च आयाम प्रतिनिधित्व से केवल कुछ आयामों वाले प्रतिनिधित्व में "कुचलने" के रूप में सोच सकते हैं।
ऐसी स्थिति के उदाहरण के रूप में जहां पीसीए उपयोगी हो सकता है, शराब का वर्णन करने के विभिन्न तरीकों के बारे में सोचें। हालाँकि CO2 स्तर, वातन स्तर इत्यादि जैसी कई अत्यधिक विशिष्ट विशेषताओं का उपयोग करके वाइन का वर्णन करना संभव है, किसी विशिष्ट प्रकार की वाइन की पहचान करने का प्रयास करते समय ऐसी विशिष्ट सुविधाएँ अपेक्षाकृत बेकार हो सकती हैं। इसके बजाय, स्वाद, रंग और उम्र जैसी अधिक सामान्य विशेषताओं के आधार पर प्रकार की पहचान करना अधिक विवेकपूर्ण होगा। पीसीए का उपयोग अधिक विशिष्ट सुविधाओं को संयोजित करने और ऐसी विशेषताएं बनाने के लिए किया जा सकता है जो अधिक सामान्य, उपयोगी हों और ओवरफिटिंग की संभावना कम हो।
पीसीए यह निर्धारित करके किया जाता है कि इनपुट सुविधाएँ एक-दूसरे के संबंध में माध्य से कैसे भिन्न होती हैं, यह निर्धारित करके कि सुविधाओं के बीच कोई संबंध मौजूद है या नहीं। ऐसा करने के लिए, एक सहसंयोजक मैट्रिक्स बनाया जाता है, जो डेटासेट सुविधाओं के संभावित जोड़े के संबंध में सहप्रसरणों से बना एक मैट्रिक्स स्थापित करता है। इसका उपयोग चरों के बीच सहसंबंध निर्धारित करने के लिए किया जाता है, जिसमें एक नकारात्मक सहप्रसरण एक व्युत्क्रम सहसंबंध दर्शाता है और एक सकारात्मक सहसंबंध एक सकारात्मक सहसंबंध दर्शाता है।
डेटासेट के प्रमुख (सबसे प्रभावशाली) घटक प्रारंभिक चर के रैखिक संयोजन बनाकर बनाए जाते हैं, जो रैखिक बीजगणित अवधारणाओं की सहायता से किया जाता है जिसे कहा जाता है आइगेनवैल्यूज़ एवं आइगेनवेक्टर्स. संयोजन इसलिए बनाए जाते हैं ताकि प्रमुख घटक एक-दूसरे से असंबद्ध हों। प्रारंभिक चर में निहित अधिकांश जानकारी पहले कुछ प्रमुख घटकों में संपीड़ित होती है, जिसका अर्थ है कि नई सुविधाएँ (प्रमुख घटक) बनाई गई हैं जिनमें मूल डेटासेट से जानकारी को छोटे आयामी स्थान में शामिल किया गया है।
विलक्षण मान अपघटन
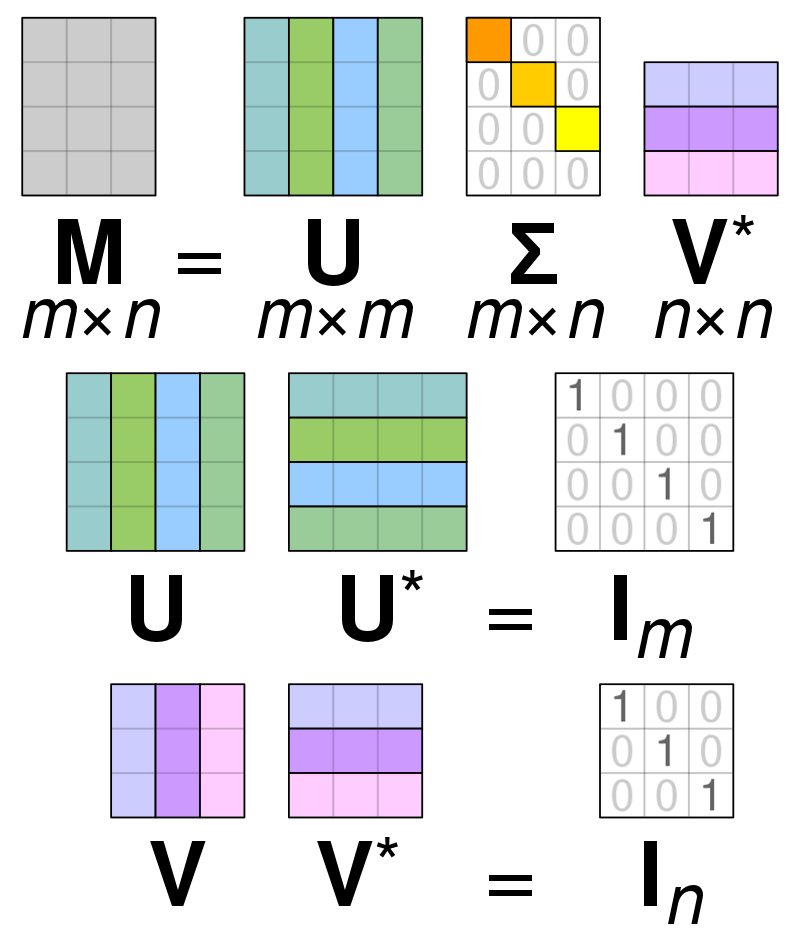
फोटो: Cmglee द्वारा - स्वयं का कार्य, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
एकवचन मूल्य अपघटन (एसवीडी) is मैट्रिक्स के भीतर मानों को सरल बनाने के लिए उपयोग किया जाता है, मैट्रिक्स को उसके घटक भागों तक कम करना और उस मैट्रिक्स के साथ गणना करना आसान बनाना। एसवीडी का उपयोग वास्तविक-मूल्य और जटिल मैट्रिक्स दोनों के लिए किया जा सकता है, लेकिन इस स्पष्टीकरण के प्रयोजनों के लिए, वास्तविक मूल्यों के मैट्रिक्स को कैसे विघटित किया जाए, इसकी जांच की जाएगी।
मान लें कि हमारे पास वास्तविक-मूल्य डेटा से बना एक मैट्रिक्स है और हमारा लक्ष्य पीसीए के लक्ष्य के समान, मैट्रिक्स के भीतर कॉलम/सुविधाओं की संख्या को कम करना है। पीसीए की तरह, एसवीडी मैट्रिक्स की परिवर्तनशीलता को यथासंभव संरक्षित करते हुए मैट्रिक्स की आयामीता को संपीड़ित करेगा। यदि हम मैट्रिक्स ए पर काम करना चाहते हैं, तो हम मैट्रिक्स ए को यू, डी, और वी नामक तीन अन्य मैट्रिक्स के रूप में प्रस्तुत कर सकते हैं। मैट्रिक्स ए मूल x * y तत्वों से बना है जबकि मैट्रिक्स यू तत्वों एक्स * एक्स से बना है (यह है) एक ऑर्थोगोनल मैट्रिक्स)। मैट्रिक्स V एक अलग ऑर्थोगोनल मैट्रिक्स है जिसमें y * y तत्व होते हैं। मैट्रिक्स D में तत्व x * y हैं और यह एक विकर्ण मैट्रिक्स है।
मैट्रिक्स ए के मानों को विघटित करने के लिए, हमें मूल एकवचन मैट्रिक्स मानों को एक नए मैट्रिक्स के भीतर पाए जाने वाले विकर्ण मानों में परिवर्तित करने की आवश्यकता है। ऑर्थोगोनल मैट्रिक्स के साथ काम करते समय, यदि उन्हें अन्य संख्याओं से गुणा किया जाता है, तो उनके गुण नहीं बदलते हैं। इसलिए, हम इस संपत्ति का लाभ उठाकर मैट्रिक्स ए का अनुमान लगा सकते हैं। जब हम ऑर्थोगोनल मैट्रिक्स को मैट्रिक्स V के स्थानान्तरण के साथ गुणा करते हैं, तो परिणाम हमारे मूल A के समतुल्य मैट्रिक्स होता है।
जब मैट्रिक्स ए को मैट्रिक्स यू, डी और वी में विघटित किया जाता है, तो उनमें मैट्रिक्स ए के भीतर पाया गया डेटा होता है। हालांकि, मैट्रिक्स के सबसे बाएं कॉलम में अधिकांश डेटा होगा। हम केवल इन पहले कुछ कॉलमों को ले सकते हैं और मैट्रिक्स ए का प्रतिनिधित्व कर सकते हैं जिसमें बहुत कम आयाम हैं और अधिकांश डेटा ए के भीतर है।
रेखीय विभेदक विश्लेषण

बाएं: एलडीए से पहले मैट्रिक्स, दाएं: एलडीए के बाद एक्सिस, अब अलग किया जा सकता है
रेखीय विभेदक विश्लेषण (LDA) एक ऐसी प्रक्रिया है जो बहुआयामी ग्राफ़ से डेटा लेती है और इसे एक रेखीय ग्राफ़ पर पुनः प्रक्षेपित करता है. आप दो अलग-अलग वर्गों से संबंधित डेटा बिंदुओं से भरे दो-आयामी ग्राफ़ के बारे में सोचकर इसकी कल्पना कर सकते हैं। मान लें कि बिंदु चारों ओर बिखरे हुए हैं ताकि कोई रेखा न खींची जा सके जो दो अलग-अलग वर्गों को स्पष्ट रूप से अलग कर दे। इस स्थिति को संभालने के लिए, 2डी ग्राफ़ में पाए गए बिंदुओं को 1डी ग्राफ़ (एक रेखा) में घटाया जा सकता है। इस लाइन में सभी डेटा बिंदु वितरित होंगे और उम्मीद है कि इसे दो खंडों में विभाजित किया जा सकता है जो डेटा के सर्वोत्तम संभव पृथक्करण का प्रतिनिधित्व करते हैं।
एलडीए क्रियान्वित करते समय दो प्राथमिक लक्ष्य होते हैं। पहला लक्ष्य वर्गों के लिए अंतर को कम करना है, जबकि दूसरा लक्ष्य दो वर्गों के साधनों के बीच की दूरी को अधिकतम करना है। इन लक्ष्यों को एक नई धुरी बनाकर पूरा किया जाता है जो 2डी ग्राफ़ में मौजूद होगी। नव निर्मित अक्ष पहले वर्णित लक्ष्यों के आधार पर दो वर्गों को अलग करने का कार्य करता है। अक्ष बनने के बाद, 2डी ग्राफ़ में पाए गए बिंदुओं को अक्ष के अनुदिश रखा जाता है।
मूल बिंदुओं को नई धुरी के साथ एक नई स्थिति में ले जाने के लिए तीन चरणों की आवश्यकता होती है। पहले चरण में, अलग-अलग वर्गों के बीच की दूरी का मतलब (वर्गों के बीच भिन्नता) का उपयोग वर्गों की पृथक्करणीयता की गणना करने के लिए किया जाता है। दूसरे चरण में, विभिन्न वर्गों के भीतर विचरण की गणना की जाती है, जो प्रश्न में वर्ग के लिए नमूने और माध्य के बीच की दूरी निर्धारित करके किया जाता है। अंतिम चरण में, निम्न-आयामी स्थान बनाया जाता है जो वर्गों के बीच भिन्नता को अधिकतम करता है।
एलडीए तकनीक सर्वोत्तम परिणाम प्राप्त करती है जब लक्ष्य वर्गों के साधन एक दूसरे से बहुत दूर होते हैं। यदि वितरण के साधन ओवरलैप होते हैं तो एलडीए एक रैखिक अक्ष के साथ कक्षाओं को प्रभावी ढंग से अलग नहीं कर सकता है।










