कृत्रिम बुद्धिमत्ता
एनएलजी सामग्री को प्रमाणित करने के लिए उद्धरणों का उपयोग करने के खतरे

राय प्राकृतिक भाषा पीढ़ी मॉडल जैसे जीपीटी -3 सामग्री को ‘हॉलुसिनेट’ करने के लिए प्रवण होते हैं जो वे तथ्यात्मक जानकारी के संदर्भ में प्रस्तुत करते हैं। एक युग में जो असाधारण रूप से पाठ-आधारित नकली समाचार के विकास के बारे में चिंतित है, ये ‘खुश करने के लिए उत्सुक’ कल्पनाएं स्वचालित लेखन और सारांश प्रणालियों के विकास और एआई-संचालित पत्रकारिता के भविष्य के लिए, साथ ही साथ प्राकृतिक भाषा प्रसंस्करण (एनएलपी) के विभिन्न अन्य उप-क्षेत्रों के लिए एक अस्तित्वगत बाधा का प्रतिनिधित्व करती हैं।
मुख्य समस्या यह है कि जीपीटी शैली के भाषा मॉडल प्रशिक्षण पाठ के बहुत बड़े संग्रह से प्रमुख विशेषताएं और वर्गों का व्युत्पन्न करते हैं, और इन विशेषताओं का उपयोग भाषा के रूप में कुशलता से और स्वाभाविक रूप से करते हैं, जेनरेट की गई सामग्री की सटीकता की परवाह किए बिना, या यहां तक कि इसकी स्वीकार्यता की।
एनएलजी प्रणालियों पर इसलिए वर्तमान में मानव द्वारा तथ्यों की पुष्टि पर निर्भर करता है या तो दो दृष्टिकोणों में से एक में: कि मॉडल या तो बीज पाठ-जेनरेटर के रूप में उपयोग किए जाते हैं जो तुरंत मानव उपयोगकर्ताओं को प्रस्तुत किए जाते हैं, या तो पुष्टि के लिए या संपादन या अनुकूलन के किसी अन्य रूप के लिए; या कि मानव को महंगे फिल्टर के रूप में उपयोग किया जाता है ताकि कम अमूर्त और ‘रचनात्मक’ मॉडलों को सूचित करने वाले डेटासेट की गुणवत्ता में सुधार किया जा सके (जो खुद में तथ्यात्मक सटीकता के संदर्भ में अभी भी विश्वास करना मुश्किल है, और जिन्हें आगे मानव पर्यवेक्षण की अतिरिक्त परतों की आवश्यकता होगी)।
पुरानी खबर और नकली तथ्य
प्राकृतिक भाषा पीढ़ी (एनएलजी) मॉडल इसलिए उत्पादक और संभावित आउटपुट का उत्पादन करने में सक्षम हैं क्योंकि उन्होंने सेमेंटिक वास्तुकला सीखी है, बल्कि वास्तविक इतिहास, विज्ञान, अर्थशास्त्र, या किसी अन्य विषय पर जिस पर उन्हें टिप्पणी करने की आवश्यकता हो सकती है, जो प्रभावी रूप से स्रोत डेटा में ‘यात्रियों’ के रूप में जुड़े हुए हैं।
जेनरेट की गई जानकारी की तथ्यात्मक सटीकता यह मानती है कि मॉडल पर प्रशिक्षित इनपुट स्वयं विश्वसनीय और अद्यतन है, जो पूर्व-प्रसंस्करण और आगे मानव-आधारित पुष्टि के संदर्भ में एक असाधारण बोझ प्रस्तुत करता है – एक महंगी बाधा जिसे एनएलपी अनुसंधान क्षेत्र वर्तमान में कई मोर्चों पर संबोधित कर रहा है।
जीपीटी -3 स्केल सिस्टम को प्रशिक्षित करने में बहुत समय और पैसा लगता है, और एक बार प्रशिक्षित होने के बाद, उन्हें ‘कERNEL स्तर’ पर अपडेट करना मुश्किल होता है। हालांकि सत्र-आधारित और उपयोगकर्ता-आधारित स्थानीय संशोधनों से लागू मॉडल की उपयोगिता और सटीकता में वृद्धि हो सकती है, ये उपयोगी लाभ अक्सर मूल मॉडल में वापस पास करना मुश्किल होता है, बिना पूर्ण या आंशिक पुन: प्रशिक्षण की आवश्यकता के।
इसलिए, नवीनतम जानकारी का उपयोग करने में सक्षम प्रशिक्षित भाषा मॉडल बनाना मुश्किल है।

कोविड -19 से पहले प्रशिक्षित, टेक्स्ट-डाविंसी-002 – जीपीटी -3 का संस्करण जिसे इसके निर्माता ओपनएआई द्वारा ‘सबसे सक्षम’ माना जाता है – 4000 टोकन प्रति अनुरोध संसाधित कर सकता है, लेकिन कोविड -19 या 2022 यूक्रेनी आक्रमण (इन प्रॉम्प्ट और प्रतिक्रियाएं 5 अप्रैल 2022 से हैं) के बारे में कुछ नहीं जानता है। दिलचस्प बात यह है कि ‘अज्ञात’ वास्तव में दोनों विफलता मामलों में एक स्वीकार्य उत्तर है, लेकिन आगे के प्रॉम्प्ट आसानी से यह स्थापित करते हैं कि जीपीटी -3 को इन घटनाओं के बारे में कुछ नहीं पता है। स्रोत: https://beta.openai.com/playground
एक प्रशिक्षित मॉडल केवल प्रशिक्षण समय में आंतरिक ‘सत्य’ तक पहुंच सकता है, और यह मुश्किल है कि जब मॉडल को अपने दावों की पुष्टि करने का प्रयास किया जाता है, तो डिफ़ॉल्ट रूप से सटीक और प्रासंगिक उद्धरण प्राप्त करना मुश्किल होता है। डिफ़ॉल्ट जीपीटी -3 (उदाहरण के लिए) से उद्धरण प्राप्त करने का वास्तविक खतरा यह है कि यह कभी-कभी सही उद्धरण उत्पन्न करता है, जिससे इसकी क्षमताओं के इस पहलू में एक झूठा विश्वास होता है:

शीर्ष, 2021-युग के दाविंसी-निर्देश-टेक्स्ट जीपीटी -3 द्वारा प्राप्त तीन सटीक उद्धरण। केंद्र, जीपीटी -3 एक प्रॉम्प्ट के बावजूद आइंस्टीन के सबसे प्रसिद्ध उद्धरणों में से एक ("गॉड डोज नॉट प्ले डाइस विद द यूनिवर्स") का हवाला देने में विफल रहता है। नीचे, जीपीटी -3 अल्बर्ट आइंस्टीन को एक घिनौना और काल्पनिक उद्धरण सौंपता है, जो स्पष्ट रूप से उसी सत्र में विंस्टन चर्चिल के बारे में पहले के प्रश्नों से ओवरस्पिल है। स्रोत: लेखक का 2021 का लेख https://www.width.ai/post/business-applications-for-gpt-3
गोफरसाइट
एनएलजी मॉडल में इस सामान्य कमी को संबोधित करने के लिए, गूगल के डीपमाइंड ने हाल ही में गोफरसाइट का प्रस्ताव किया है, जो 280- अरब पैरामीटर मॉडल है जो विशिष्ट और सटीक साक्ष्य का हवाला देने में सक्षम है जो अपने उत्पन्न प्रतिक्रियाओं के समर्थन में प्रॉम्प्ट के लिए।



गोफरसाइट अपने दावों का समर्थन करने वाले वास्तविक उद्धरणों के साथ। स्रोत: https://arxiv.org/pdf/2203.11147.pdf
गोफरसाइट मानव प्राथमिकताओं से प्रशिक्षण (आरएलएचपी) का लाभ उठाता है ताकि प्रश्न मॉडल को प्रशिक्षित किया जा सके जो वास्तविक उद्धरणों का हवाला देने में सक्षम हों जो समर्थन साक्ष्य के रूप में कार्य करते हैं। उद्धरण कई दस्तावेज़ स्रोतों से लाइव खींचे जाते हैं जो खोज इंजनों से प्राप्त होते हैं, या एक विशिष्ट दस्तावेज़ से जो उपयोगकर्ता द्वारा प्रदान किया जाता है।
गोफरसाइट के प्रदर्शन का मूल्यांकन मॉडल की प्रतिक्रियाओं के मानव मूल्यांकन के माध्यम से किया गया था, जो गूगल के नेचरलक्वेश्चन डेटासेट पर 80% समय में ‘उच्च गुणवत्ता’ पाया गया, और एलआई5 डेटासेट पर 67% समय में।
नकली उद्धरण
हालांकि, जब इसे ऑक्सफोर्ड विश्वविद्यालय के सत्यनिष्ठक्यूए बेंचमार्क के खिलाफ परीक्षण किया गया, तो गोफरसाइट की प्रतिक्रियाएं शायद ही कभी सत्यनिष्ठक्यूए के साथ स्कोर की गईं, मानव-निर्देशित ‘सही’ उत्तरों की तुलना में।
लेखकों का सुझाव है कि यह इसलिए है क्योंकि ‘समर्थित उत्तरों’ की अवधारणा स्वयं में किसी भी वस्तुनिष्ठ तरीके से सत्य को परिभाषित नहीं करती है, क्योंकि स्रोत उद्धरणों की उपयोगिता अन्य कारकों से समझौता की जा सकती है, जैसे कि संभावना है कि उद्धरण के लेखक स्वयं ‘हॉलुसिनेटिंग’ (अर्थात कल्पनाशील दुनिया के बारे में लिख रहे हैं, विज्ञापन सामग्री का उत्पादन कर रहे हैं, या अन्य तरीकों से अस्वाभाविक सामग्री का प्रतिनिधित्व कर रहे हैं)।



गोफरसाइट मामले जहां संभावना आवश्यक रूप से ‘सत्य’ के बराबर नहीं है।
प्रभावी रूप से, यह आवश्यक हो जाता है कि ‘समर्थित’ और ‘सच’ के बीच अंतर करना होगा। मानव संस्कृति वर्तमान में मशीन लर्निंग की तुलना में सत्य के उद्देश्य परिभाषाओं को प्राप्त करने के लिए विधियों और ढांचों के उपयोग में आगे है; और यहां तक कि वहां, ‘महत्वपूर्ण’ सत्य की मूल स्थिति प्रतीत होती है विवाद और हाशिए पर इनकार।
समस्या एनएलजी आर्किटेक्चर में पुनरावृत्ति है जो निर्णायक ‘प्रमाणीकरण’ तंत्र का आविष्कार करना चाहती है: मानव-नेतृत्व वाली सर्वसम्मति को सत्य के एक बेंचमार्क के रूप में सेवा में दबाया जाता है, आउटसोर्स्ड, एएमटी-शैली के मॉडल में जहां मानव मूल्यांकनकर्ता (और अन्य मानव जो उनके बीच विवादों को मध्यस्थता करते हैं) स्वयं में आंशिक और पूर्वाग्रहपूर्ण होते हैं।
उदाहरण के लिए, गोफरसाइट के प्रारंभिक प्रयोग एक ‘सुपर रेटर’ मॉडल का उपयोग करते हैं ताकि मॉडल के आउटपुट का मूल्यांकन करने के लिए सर्वोत्तम मानव विषयों का चयन किया जा सके, केवल उन रेटर्स का चयन किया जाता है जो गुणवत्ता आश्वासन सेट की तुलना में कम से कम 85% स्कोर करते हैं। अंत में, 113 सुपर-रेटर्स को कार्य के लिए चुना गया था।
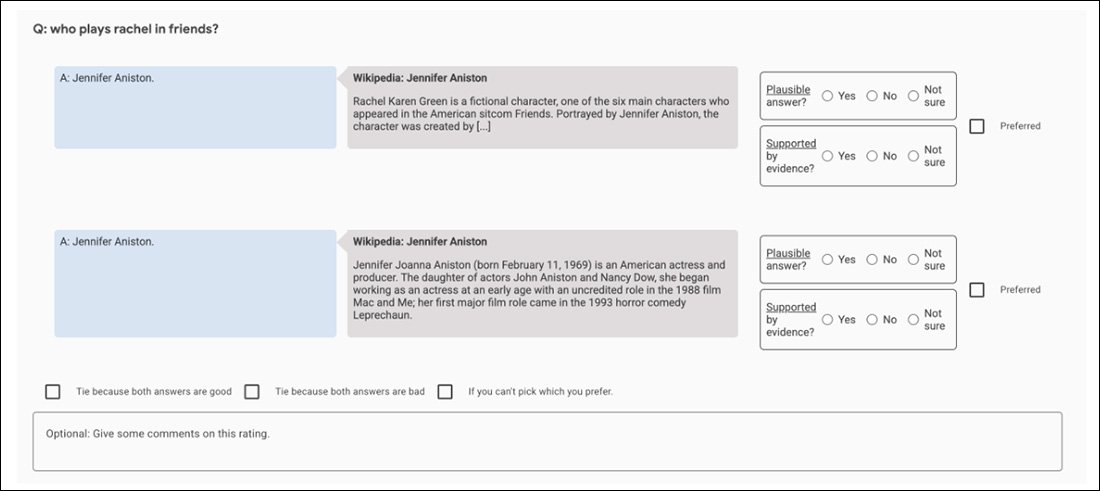
गोफरसाइट के आउटपुट का मूल्यांकन करने में मदद करने के लिए तुलना ऐप का स्क्रीनशॉट।
यह तर्क दिया जा सकता है कि यह एक जीतने योग्य फ्रैक्टल पीछा का एक आदर्श चित्र है: रेटर्स को रेट करने के लिए उपयोग किया जाने वाला गुणवत्ता आश्वासन सेट स्वयं एक और ‘मानव-परिभाषित’ मेट्रिक है सत्य की, जैसा कि ऑक्सफोर्ड ट्रुथफुलक्यूए सेट है जिसके खिलाफ गोफरसाइट को कमी पाई गई है।
समर्थित और ‘प्रमाणित’ सामग्री के संदर्भ में, एनएलजी प्रणालियों को मानव डेटा पर प्रशिक्षित करने से सभी जो संश्लेषित किया जा सकता है वह मानव असमानता और विविधता है, जो स्वयं एक दुर्भाग्यपूर्ण और असुलझा समस्या है। हमारे पास अपने दृष्टिकोण का समर्थन करने वाले स्रोतों का हवाला देने और हमारी स्रोत जानकारी के बारे में गलत या भ्रामक होने पर भी अधिकार और आश्वस्त तरीके से बोलने की एक अंतर्निहित प्रवृत्ति है; और एक प्रवृत्ति जो इन दृष्टिकोणों को सीधे जंगल में डालती है, मानव इतिहास में कभी भी अनुपात और प्रभावशीलता के पैमाने पर।
इसलिए, साइटेशन-समर्थित एनएलजी प्रणालियों के विकास में शामिल खतरा स्रोत सामग्री की अप्रत्याशित प्रकृति के साथ जुड़ा हुआ प्रतीत होता है। जीपीटी -3 जैसे मॉडल के आउटपुट में उपयोगकर्ता का विश्वास बढ़ाने वाली कोई भी तंत्र (जैसे कि सीधे उद्धरण और उद्धरण), वर्तमान राज्य में, आउटपुट की वास्तविकता की तुलना में इसकी प्रामाणिकता में खतरनाक रूप से जोड़ रहा है।
ऐसी तकनीकें तब उपयोगी होंगी जब एनएलपी अंततः ऑरवेल के नाइनटीन एटी -फोर के कल्पनात्मक ‘केलिडोस्कोप’ को पुन: बनाता है; लेकिन वे उद्देश्य पत्रिका विश्लेषण, एआई-केंद्रित पत्रकारिता और मशीन सारांश और स्वचालित या निर्देशित पाठ पीढ़ी के अन्य संभावित ‘गैर-काल्पनिक’ अनुप्रयोगों के लिए एक खतरनाक पीछा का प्रतिनिधित्व करते हैं।
5 अप्रैल 2022 को पहली बार प्रकाशित। 3:29pm ईईटी को शब्द को सही करने के लिए अपडेट किया गया।












