कृत्रिम बुद्धिमत्ता
एडोब रिसर्च ने डिसेंटैंग्ल्ड जीएएन फेस एडिटिंग का विस्तार किया

यह समझना मुश्किल नहीं है कि entanglement इमेज सिंथेसिस में एक समस्या क्यों है, क्योंकि यह अक्सर जीवन के अन्य क्षेत्रों में एक समस्या है; उदाहरण के लिए, करी से हल्दी को हटाना एक बर्गर में अचार को हटाने से ज्यादा मुश्किल है, और एक कप कॉफी को डी-स्वीट करना लगभग असंभव है। कुछ चीजें बस बंडल में आती हैं।
इसी तरह, entanglement एक रुकावट है छवि सिंथेसिस आर्किटेक्चर के लिए जो आदर्श रूप से मशीन लर्निंग का उपयोग करके चेहरों (या कुत्तों, नावों, या किसी अन्य डोमेन) को बनाने या संपादित करने के लिए विभिन्न विशेषताओं और अवधारणाओं को अलग करना चाहेगा।
यदि आप आयु, लिंग, बालों का रंग, त्वचा का रंग, भावना, और इस तरह की धाराओं को अलग कर सकते हैं, तो आपके पास वास्तविक साधनता और लचीलेपन की शुरुआत होगी एक फ्रेमवर्क में जो वास्तव में ग्रैन्युलर स्तर पर चेहरे की छवियों को बना और संपादित कर सकता है, बिना अनचाहे ‘यात्रियों’ को इन रूपांतरणों में खींचे।

अधिकतम entanglement (ऊपर बाएं) पर, आप केवल एक सीखे हुए जीएएन नेटवर्क की छवि को दूसरे व्यक्ति की छवि में बदल सकते हैं।
यह प्रभावी रूप से नवीनतम एआई कंप्यूटर विजन प्रौद्योगिकी का उपयोग करके कुछ हासिल करने के लिए है जो तीस साल से अधिक समय से अन्य माध्यमों से हल किया गया है।
कुछ डिग्री के पृथक्करण (‘मध्यम पृथक्करण’ ऊपर की छवि में), यह संभव है शैली-आधारित परिवर्तन करने के लिए जैसे कि बालों का रंग, अभिव्यक्ति, सौंदर्य उत्पादों का अनुप्रयोग, और सीमित सिर घुमाव, अन्य लोगों के बीच में।

स्रोत: फेस एडिटिंग विद अटेंशन, फरवरी 2022, https://arxiv.org/pdf/2202.02713.pdf
पिछले दो वर्षों में, इंटरैक्टिव फेस-एडिटिंग वातावरण बनाने के कई प्रयास किए गए हैं जो एक उपयोगकर्ता को स्लाइडर और अन्य पारंपरिक यूआई इंटरैक्शन के साथ चेहरे की विशेषताओं को बदलने की अनुमति देते हैं, जबकि लक्ष्य चेहरे की मूल विशेषताओं को संरक्षित करते हुए जोड़ या परिवर्तन करते हैं। हालांकि, यह जीएएन के लेटेंट स्पेस में अंतर्निहित विशेषता/शैली entanglement के कारण एक चुनौती साबित हुई है।
उदाहरण के लिए, चश्मा विशेषता अक्सर बूढ़ा विशेषता के साथ जुड़ी हुई है, जिसका अर्थ है कि चश्मा जोड़ने से चेहरे को ‘बूढ़ा’ बना सकता है, जबकि चेहरे को बूढ़ा बनाने से चश्मा जोड़ सकता है, लागू की गई उच्च-स्तरीय विशेषताओं के पृथक्करण की डिग्री के आधार पर (नीचे ‘परीक्षण’ देखें)।
बालों का रंग और अन्य बाल सुविधाओं को बदलना लगभग असंभव है बिना बालों के धागे और वितरण को पुनः गणना किए, जो एक ‘सिज़लिंग’, संक्रमणकालीन प्रभाव देता है।

स्रोत: इंटरफेसजीएन डेमो (सीवीपीआर 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
लेटेंट-टू-लेटेंट जीएएन ट्रैवर्सल
एक नए एडोब-नेतृत्व वाले पत्र entered के लिए डब्ल्यूएसीवी 2022 में इन अंतर्निहित मुद्दों के लिए एक नए दृष्टिकोण की पेशकश की है एक paper में जिसका शीर्षक लेटेंट टू लेटेंट: एक सीखा हुआ मैपर पहचान संरक्षण संपादन के लिए कई चेहरे विशेषताओं में स्टाइलजीएन-जेनरेटेड छवियों है।

स्रोत: लेटेंट टू लेटेंट: एक सीखा हुआ मैपर पहचान संरक्षण संपादन के लिए कई चेहरे विशेषताओं में स्टाइलजीएन-जेनरेटेड छवियों. यहाँ हम देखते हैं कि सीखे हुए चेहरे में आधार विशेषताएं असंबंधित परिवर्तनों में खींची नहीं जाती हैं। वीडियो एम्बेड के लिए लेख के अंत में बेहतर विवरण और रिज़ॉल्यूशन के लिए देखें। स्रोत: https://www.youtube.com/watch?v=rf_61llRH0Q
इस पत्र का नेतृत्व एडोब एप्लाइड साइंटिस्ट सियावश खोदादादेह द्वारा किया जाता है, जिसमें चार अन्य एडोब शोधकर्ता और फ्लोरिडा विश्वविद्यालय के कंप्यूटर विज्ञान विभाग के एक शोधकर्ता शामिल हैं।
यह टुकड़ा दिलचस्प है क्योंकि एडोब इस स्थान में कुछ समय से काम कर रहा है, और यह कल्पना करना लुभावना है कि यह कार्यक्षमता अगले कुछ वर्षों में एक क्रिएटिव सूट परियोजना में प्रवेश कर सकती है; लेकिन मुख्य रूप से क्योंकि परियोजना के लिए बनाई गई आर्किटेक्चर एक जीएएन चेहरे संपादक में दृश्य अखंडता को बनाए रखने के लिए एक अलग दृष्टिकोण लेती है जबकि परिवर्तन लागू किए जा रहे हैं।
लेखक घोषित करते हैं:
‘[हम] एक न्यूरल नेटवर्क को प्रशिक्षित करते हैं जो एक लेटेंट-टू-लेटेंट परिवर्तन करता है जो परिवर्तित विशेषता के साथ छवि के लिए संबंधित लेटेंट एन्कोडिंग खोजता है। जैसा कि तकनीक एक-शॉट है, यह एक रैखिक या गैर-रैखिक ट्रेजेक्टरी पर परिवर्तन के धीरे-धीरे परिवर्तन पर निर्भर नहीं करता है।
‘पूरे जेनरेशन पाइपलाइन पर अंत से अंत तक नेटवर्क को प्रशिक्षित करके, सिस्टम ऑफ-द-शेल्फ जेनरेटर आर्किटेक्चर के लेटेंट स्पेस को अनुकूलित कर सकता है। संरक्षण गुण, जैसे कि व्यक्ति की पहचान को बनाए रखना, प्रशिक्षण हानियों के रूप में एन्कोड किया जा सकता है।
‘एक बार लेटेंट-टू-लेटेंट नेटवर्क प्रशिक्षित हो जाने के बाद, इसे बिना पुनः प्रशिक्षण के मनमानी छवियों के लिए पुनः उपयोग किया जा सकता है।’
यह अंतिम भाग का अर्थ है कि प्रस्तावित आर्किटेक्चर अंतिम उपयोगकर्ता के साथ एक समाप्त अवस्था में आता है। यह अभी भी स्थानीय संसाधनों पर एक न्यूरल नेटवर्क चलाने की आवश्यकता है, लेकिन नई छवियों को ‘ड्रॉप इन’ किया जा सकता है और लगभग तुरंत बदलने के लिए तैयार है, क्योंकि फ्रेमवर्क पर्याप्त रूप से डिकपल है ताकि आगे की छवि-विशिष्ट प्रशिक्षण की आवश्यकता न हो।
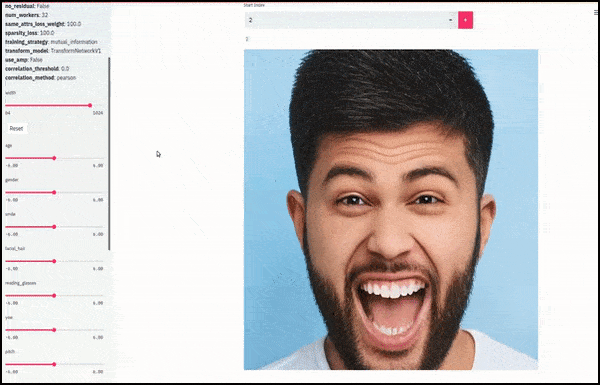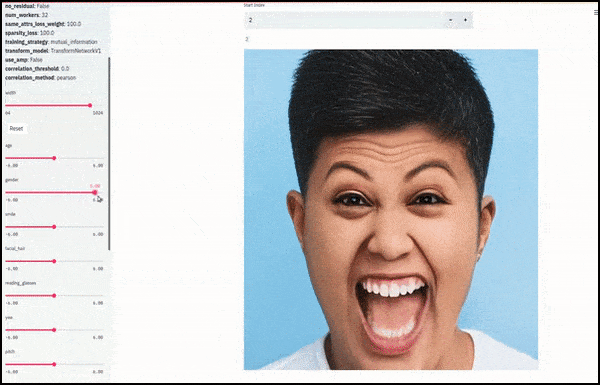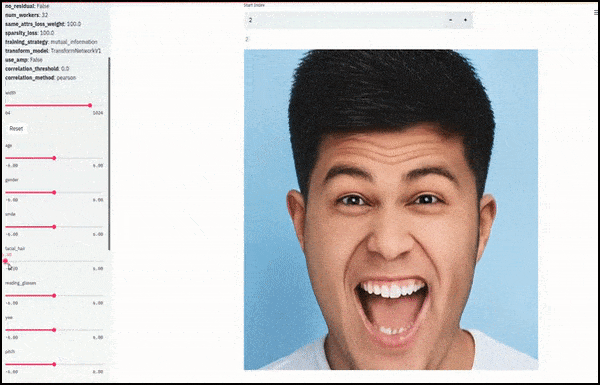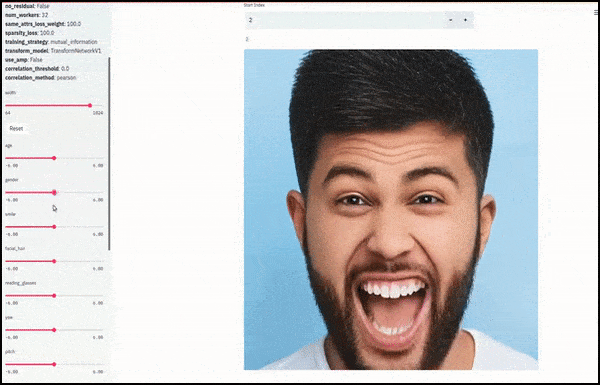
लिंग और चेहरे के बाल बदले जाते हैं क्योंकि स्लाइडर लेटेंट स्पेस में यादृच्छिक और मनमाने तरीके से पथ का अनुसरण करते हैं, न कि केवल ‘एंडपॉइंट्स के बीच स्क्रबिंग’। वीडियो एम्बेड के लिए लेख के अंत में अधिक परिवर्तनों के लिए देखें।
काम में मुख्य उपलब्धियों में से एक नेटवर्क की क्षमता है ‘फ्रीज’ लेटेंट स्पेस में पहचान करने के लिए केवल लक्ष्य वेक्टर में विशेषता को बदलकर, और ‘सुधार शर्तों’ प्रदान करने के लिए जो परिवर्तित हो रही पहचानों को संरक्षित करती हैं।
मूल रूप से, प्रस्तावित नेटवर्क एक व्यापक आर्किटेक्चर में निहित है जो सभी संसाधित तत्वों को समन्वयित करता है, जो जमे हुए वजन वाले पूर्व-प्रशिक्षित घटकों से गुजरते हैं जो परिवर्तनों पर अवांछित लेटरल प्रभाव नहीं पैदा करेंगे।
चूंकि प्रशिक्षण प्रक्रिया triplets पर निर्भर करती है जो एक बीज छवि (जीएएन इनवर्सन के तहत) या एक मौजूदा प्रारंभिक लेटेंट एन्कोडिंग द्वारा उत्पन्न की जा सकती है, पूरी प्रशिक्षण प्रक्रिया असुपरवाइज्ड है, जिसमें सामान्य श्रेणी के लेबलिंग और क्यूरेशन सिस्टम के सामान्य कार्यों को प्रभावी रूप से आर्किटेक्चर में बेक किया जाता है। वास्तव में, नया सिस्टम ऑफ-द-शेल्फ विशेषता रिग्रेसर का उपयोग करता है:
‘[हमारे] नेटवर्क द्वारा स्वतंत्र रूप से नियंत्रित की जा सकने वाली विशेषताओं की संख्या केवल मान्यता प्राप्त करने वालों की क्षमताओं से सीमित है – यदि आपके पास एक विशेषता के लिए मान्यता प्राप्त करने वाला है, तो हम इसे मनमानी चेहरों में जोड़ सकते हैं। हमारे प्रयोगों में, हमने लेटेंट-टू-लेटेंट नेटवर्क को 35 अलग-अलग चेहरे की विशेषताओं को समायोजित करने के लिए प्रशिक्षित किया, किसी भी पिछले दृष्टिकोण से अधिक।’
सिस्टम में एक अतिरिक्त सुरक्षा है जो अवांछित ‘साइड-इफेक्ट’ परिवर्तनों के खिलाफ है: अनुरोध की अनुपस्थिति में, लेटेंट-टू-लेटेंट नेटवर्क एक लेटेंट वेक्टर को खुद से मैप करेगा, स्थिरता को और भी बढ़ाते हुए लक्ष्य पहचान को।
चेहरे की पहचान
पिछले कुछ वर्षों में जीएएन और एन्कोडर/डीकोडर-आधारित चेहरे संपादकों के साथ एक आवर्ती समस्या यह रही है कि लागू परिवर्तन समानता को खराब करते हैं। इसे लड़ने के लिए, एडोब परियोजना में एक एम्बेडेड चेहरे की पहचान नेटवर्क का उपयोग किया जाता है जिसे फेसनेट कहा जाता है एक विभेदक के रूप में।

परियोजना आर्किटेक्चर, नीचे मध्य-बाएं के लिए फेसनेट के समावेश के लिए देखें। स्रोत: लेटेंट टू लेटेंट: एक सीखा हुआ मैपर पहचान संरक्षण संपादन के लिए कई चेहरे विशेषताओं में स्टाइलजीएन-जेनरेटेड छवियों, ओपनएक्सेस।
(एक व्यक्तिगत नोट पर, यह चेहरे की पहचान और यहां तक कि अभिव्यक्ति पहचान प्रणालियों के मानक एकीकरण की ओर एक प्रोत्साहित करने वाला कदम लगता है सृजनात्मक नेटवर्क में, संभावित रूप से गहरे नकली वास्तुकला की लागत पर अभिव्यक्ति विश्वासworthiness और चेहरे के निर्माण क्षेत्र में अन्य महत्वपूर्ण डोमेन को पार करने के लिए।)
एक्सेस ऑल एरियाज लेटेंट स्पेस में
फ्रेमवर्क की एक और प्रभावशाली विशेषता इसकी क्षमता है मनमाने ढंग से लेटेंट स्पेस में परिवर्तनों के बीच यात्रा करने की उपयोगकर्ता की मर्जी से। कई पूर्व सिस्टम जो अन्वेषण इंटरफेस प्रदान करते थे अक्सर उपयोगकर्ता को मूल रूप से ‘स्क्रबिंग’ के बीच तय सुविधा परिवर्तन टाइमलाइन्स छोड़ देते थे – प्रभावशाली, लेकिन अक्सर बहुत रैखिक या निर्धारित अनुभव।

इम्प्रूविंग जीएएन इक्विलिब्रियम द्वारा स्पेशियल अवेयरनेस को बढ़ाने से: यहाँ उपयोगकर्ता दो लेटेंट स्पेस स्थानों के बीच संभावित परिवर्तन बिंदुओं के माध्यम से स्क्रब करता है, लेकिन लेटेंट स्पेस में पूर्व-प्रशिक्षित स्थानों की सीमाओं के भीतर। इसी सामग्री पर आधारित अन्य प्रकार के परिवर्तन लागू करने के लिए, पुनर्संरचना और/या पुनः प्रशिक्षण आवश्यक है। स्रोत: https://genforce.github.io/eqgan/
इसके अलावा, उपयोगकर्ता मैन्युअल रूप से ‘फ्रीज’ कर सकते हैं जो उन्हें परिवर्तन प्रक्रिया के दौरान संरक्षित करना चाहते हैं। इस तरह उपयोगकर्ता सुनिश्चित कर सकते हैं कि (उदाहरण के लिए) पृष्ठभूमि नहीं बदलती है या आंखें खुली या बंद रहती हैं।
डेटा
विशेषता प्रतिगमन नेटवर्क को तीन नेटवर्क पर प्रशिक्षित किया गया था: एफएफएचक्यू, सेलेबएएमास्क-एचक्यू, और एक स्थानीय, जीएएन-जेनरेटेड नेटवर्क जो स्टाइलजीएन-V2 के जेड स्पेस से 400,000 वेक्टर का नमूना लेकर प्राप्त किया गया था।
बाहरी-वितरण (OOD) छवियों को दूर किया गया था, और विशेषताओं को माइक्रोसॉफ्ट के फेस एपीआई का उपयोग करके निकाला गया था, जिसके परिणामस्वरूप 721,218 प्रशिक्षण छवियों और 72,172 परीक्षण छवियों का एक सेट तैयार किया गया था जो तुलना करने के लिए थीं।
परीक्षण
हालांकि प्रायोगिक नेटवर्क को शुरू में 35 संभावित परिवर्तनों को समायोजित करने के लिए कॉन्फ़िगर किया गया था, उन्हें तुलनात्मक फ्रेमवर्क इंटरफेसजीएन, जीएनस्पेस, और स्टाइलफ्लो के खिलाफ परीक्षण करने के लिए आठ में कम कर दिया गया था।
चुने गए आठ विशेषताएं आयु, गंजापन, दाढ़ी, अभिव्यक्ति, लिंग, चश्मा, पिच, और याव थीं। प्रतिद्वंद्वी फ्रेमवर्क में से कुछ के लिए यह आवश्यक था कि उन्हें कुछ विशेषताओं जैसे गंजापन और दाढ़ी को जोड़ने के लिए पुनः उपकरण किया जाए जो मूल वितरण में नहीं थीं।
जैसा कि अपेक्षित था, प्रतिद्वंद्वी वास्तुकला में अधिक entanglement हुआ। उदाहरण के लिए, एक परीक्षण में, इंटरफेसजीएन और स्टाइलफ्लो दोनों ने विषय का लिंग बदल दिया जब उन्हें आयु लागू करने के लिए कहा गया:

दो प्रतिद्वंद्वी फ्रेमवर्क ने ‘आयु’ परिवर्तन में लिंग परिवर्तन को रोल किया, साथ ही साथ बिना उपयोगकर्ता की बोली के बालों का रंग बदल दिया।
इसके अलावा, दो प्रतिद्वंद्वियों ने पाया कि चश्मा और आयु अविभाज्य पहलू हैं:

चश्मा और बालों का रंग परिवर्तन मुफ्त में!
यह शोध के लिए एक समान जीत नहीं है: जैसा कि लेख के अंत में एम्बेडेड वीडियो में देखा जा सकता है, फ्रेमवर्क विविध कोणों (याव) को अनुमानित करने में सबसे कम प्रभावी है, जबकि जीएनस्पेस में आयु और चश्मा के लिए एक बेहतर सामान्य परिणाम है। लेटेंट-टू-लेटेंट फ्रेमवर्क ने स्टाइलफ्लो के साथ पिच (सिर का कोण) जोड़ने के संबंध में जीएनस्पेस के साथ बंधा है।

परिणाम एमटीसीएनएन चेहरे का पता लगाने वाले के एक कैलिब्रेशन पर आधारित हैं। निम्न परिणाम बेहतर हैं।
अधिक विवरण और उदाहरणों के लिए, लेख के अंत में एम्बेडेड वीडियो देखें।
पहली बार 16 फरवरी 2022 को प्रकाशित।












