IA 101
Qu’est-ce que la surajustement ?
Qu’est-ce que la surajustement ?
Lorsque vous formez un réseau neuronal, vous devez éviter la surajustement. La surajustement est un problème dans l’apprentissage automatique et les statistiques où un modèle apprend les modèles d’un jeu de données d’entraînement trop bien, expliquant parfaitement le jeu de données d’entraînement mais échouant à généraliser son pouvoir de prédiction à d’autres jeux de données.
Pour le dire autrement, dans le cas d’un modèle de surajustement, il montrera souvent une précision extrêmement élevée sur le jeu de données d’entraînement mais une faible précision sur les données collectées et exécutées dans le modèle à l’avenir. C’est une définition rapide de la surajustement, mais analysons le concept de surajustement en détail. Analysons comment la surajustement se produit et comment elle peut être évitée.
Comprendre le « ajustement » et la sous-ajustement
Il est utile de regarder le concept de sous-ajustement et de « ajustement » en général lorsqu’on discute de la surajustement. Lorsque nous formons un modèle, nous essayons de développer un cadre capable de prédire la nature ou la classe des éléments dans un jeu de données, en fonction des fonctionnalités qui décrivent ces éléments. Un modèle doit être capable d’expliquer un modèle dans un jeu de données et prédire les classes des points de données futurs en fonction de ce modèle. Plus le modèle explique bien la relation entre les fonctionnalités de l’ensemble d’entraînement, plus notre modèle est « ajusté ».

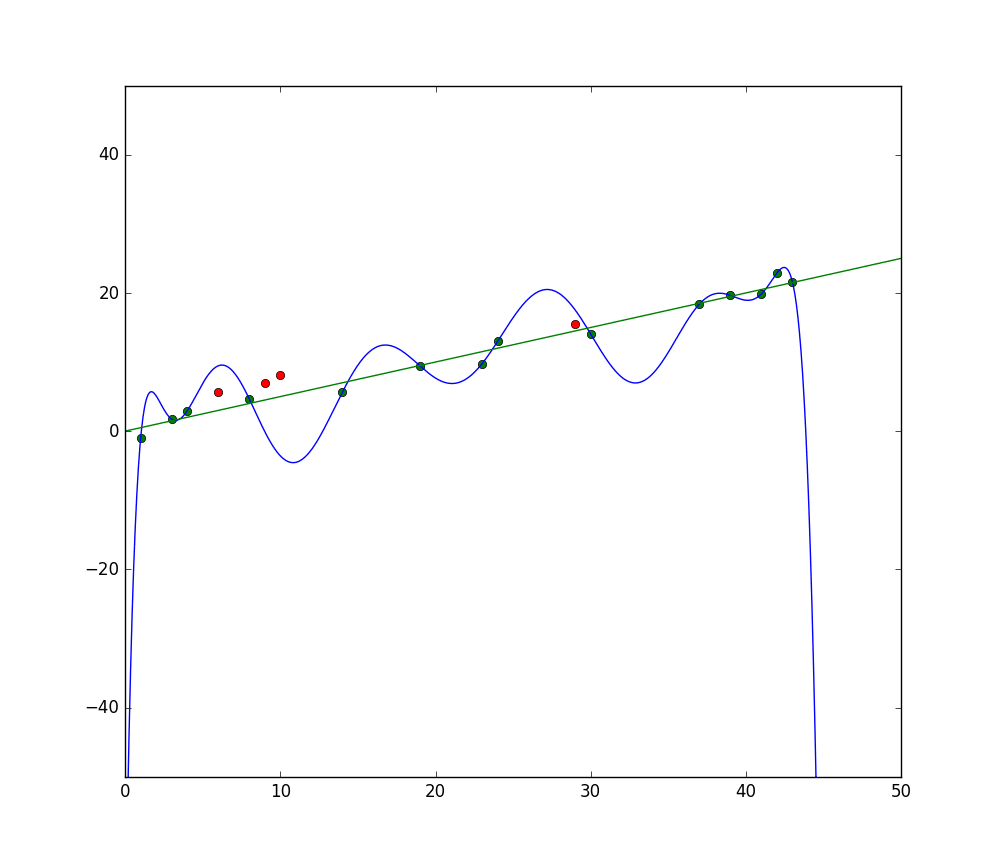
La ligne bleue représente les prédictions d’un modèle qui sous-ajuste, tandis que la ligne verte représente un modèle avec un meilleur ajustement. Photo: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Un modèle qui explique mal la relation entre les fonctionnalités des données d’entraînement et échoue ainsi à classer correctement les exemples de données futurs est en sous-ajustement. Si vous deviez tracer la relation prédite par un modèle qui sous-ajuste par rapport aux valeurs réelles, les prédictions s’écarteraient de la marque. Si nous avions un graphique avec les valeurs réelles d’un ensemble d’entraînement étiqueté, un modèle fortement sous-ajusté manquerait gravement la plupart des points de données. Un modèle avec un meilleur ajustement pourrait couper un chemin à travers les points de données, avec des points de données individuels s’écartant légèrement des valeurs prédites.
La sous-ajustement peut souvent se produire lorsqu’il n’y a pas suffisamment de données pour créer un modèle précis, ou lorsqu’on essaie de concevoir un modèle linéaire avec des données non linéaires. Plus de données d’entraînement ou plus de fonctionnalités réduiront souvent la sous-ajustement.
Pourquoi ne pas créer un modèle qui explique chaque point du jeu de données d’entraînement parfaitement ? La création d’un modèle qui a appris les modèles du jeu de données d’entraînement trop bien est ce qui provoque la surajustement. Le jeu de données d’entraînement et d’autres jeux de données que vous exécutez dans le modèle à l’avenir ne seront pas exactement les mêmes. Ils seront probablement très similaires à de nombreux égards, mais ils différeront également de manière significative. Par conséquent, concevoir un modèle qui explique parfaitement le jeu de données d’entraînement signifie que vous finissez par avoir une théorie sur la relation entre les fonctionnalités qui ne se généralise pas bien à d’autres jeux de données.
Comprendre la surajustement
La surajustement se produit lorsque un modèle apprend les détails dans le jeu de données d’entraînement trop bien, provoquant des problèmes pour le modèle lorsqu’il fait des prédictions sur des données externes. Cela peut se produire lorsque le modèle apprend non seulement les fonctionnalités du jeu de données, mais également les fluctuations aléatoires ou le bruit dans le jeu de données, en accordant de l’importance à ces occurrences aléatoires ou non importantes.
La surajustement est plus susceptible de se produire lorsque des modèles non linéaires sont utilisés, car ils sont plus flexibles lors de l’apprentissage des fonctionnalités des données. Les algorithmes d’apprentissage automatique non paramétriques ont souvent divers paramètres et techniques qui peuvent être appliqués pour contraindre la sensibilité du modèle aux données et réduire ainsi la surajustement. Par exemple, les modèles d’arbre de décision sont très sensibles à la surajustement, mais une technique appelée élagage peut être utilisée pour supprimer aléatoirement une partie des détails que le modèle a appris.
Si vous deviez tracer les prédictions du modèle sur les axes X et Y, vous auriez une ligne de prédiction qui zigzague d’avant en arrière, ce qui reflète le fait que le modèle a essayé trop fort de faire correspondre tous les points du jeu de données dans son explication.
Contrôler la surajustement
Lorsque nous formons un modèle, nous voulons idéalement que le modèle ne fasse aucune erreur. Lorsque les performances du modèle convergent vers des prédictions correctes sur tous les points de données du jeu d’entraînement, l’ajustement devient meilleur. Un modèle avec un bon ajustement est capable d’expliquer presque tout le jeu de données d’entraînement sans surajustement.
À mesure que le modèle s’entraîne, ses performances s’améliorent avec le temps. Le taux d’erreur du modèle diminuera à mesure que le temps d’entraînement passe, mais il ne diminuera qu’à un certain point. Le point auquel les performances du modèle sur l’ensemble de test commencent à augmenter à nouveau est généralement le point auquel la surajustement se produit. Pour obtenir le meilleur ajustement pour un modèle, nous voulons arrêter l’entraînement du modèle au point de perte la plus faible sur l’ensemble d’entraînement, avant que l’erreur ne commence à augmenter à nouveau. Le point d’arrêt optimal peut être déterminé en traçant les performances du modèle tout au long du temps d’entraînement et en arrêtant l’entraînement lorsque la perte est la plus faible. Cependant, un risque avec cette méthode de contrôle de la surajustement est que la spécification du point de fin de l’entraînement en fonction des performances de test signifie que les données de test sont incluses dans la procédure d’entraînement et perdent ainsi leur statut de données « non touchées ».
Il existe quelques méthodes pour lutter contre la surajustement. Une méthode pour réduire la surajustement consiste à utiliser une tactique de rééchantillonnage, qui fonctionne en estimant la précision du modèle. Vous pouvez également utiliser un ensemble de validation en plus de l’ensemble de test et tracer la précision d’entraînement par rapport à l’ensemble de validation au lieu de l’ensemble de test. Cela conserve votre ensemble de test non vu. Une méthode de rééchantillonnage populaire est la validation croisée K-folds. Cette technique vous permet de diviser vos données en sous-ensembles sur lesquels le modèle est formé, puis les performances du modèle sur les sous-ensembles sont analysées pour estimer comment le modèle se comportera sur des données externes.
L’utilisation de la validation croisée est l’un des meilleurs moyens d’estimer la précision d’un modèle sur des données non vues, et lorsqu’elle est combinée avec un ensemble de validation, la surajustement peut souvent être minimisée.








