IA 101
Qu’est-ce qu’un arbre de décision ?
Qu’est-ce qu’un arbre de décision ?
Un arbre de décision est un algorithme d’apprentissage automatique utile pour les tâches de régression et de classification. Le nom « arbre de décision » vient du fait que l’algorithme divise continuellement le jeu de données en portions de plus en plus petites jusqu’à ce que les données soient divisées en instances uniques, qui sont ensuite classées. Si vous visualisez les résultats de l’algorithme, la façon dont les catégories sont divisées ressemblerait à un arbre avec de nombreuses feuilles.
C’est une définition rapide d’un arbre de décision, mais plongeons plus profondément dans le fonctionnement des arbres de décision. Avoir une meilleure compréhension de la façon dont les arbres de décision fonctionnent, ainsi que leurs cas d’utilisation, vous aidera à savoir quand les utiliser dans vos projets d’apprentissage automatique.
Format d’un arbre de décision
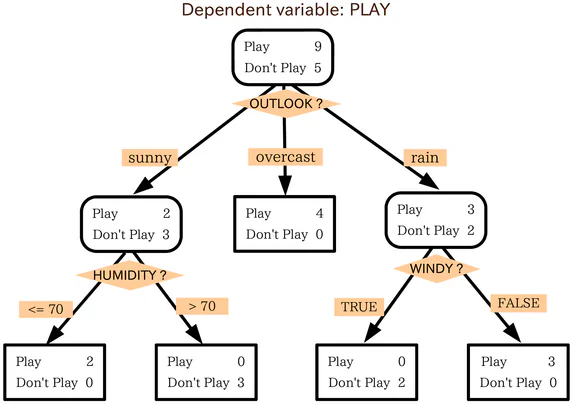
Un arbre de décision est très similaire à un diagramme de flux. Pour utiliser un diagramme de flux, vous commencez au point de départ, ou racine, du diagramme, puis, en fonction de la façon dont vous répondez aux critères de filtrage de ce nœud de départ, vous passez à l’un des nœuds possibles suivants. Ce processus est répété jusqu’à ce qu’une fin soit atteinte.
Les arbres de décision fonctionnent de manière essentiellement similaire, chaque nœud interne de l’arbre étant une sorte de test ou de critère de filtrage. Les nœuds à l’extérieur, les points de terminaison de l’arbre, sont les étiquettes pour le point de données en question et sont appelés « feuilles ». Les branches qui relient les nœuds internes aux nœuds suivants sont des fonctionnalités ou des conjonctions de fonctionnalités. Les règles utilisées pour classer les points de données sont les chemins qui vont de la racine aux feuilles.

Algorithmes pour les arbres de décision
Les arbres de décision fonctionnent sur une approche algorithmique qui divise le jeu de données en points de données individuels en fonction de différents critères. Ces divisions sont effectuées avec différentes variables, ou les différentes fonctionnalités du jeu de données. Par exemple, si l’objectif est de déterminer si un chien ou un chat est décrit par les fonctionnalités d’entrée, les variables sur lesquelles les données sont divisées pourraient être des choses comme « griffes » et « aboie ».
Quels algorithmes sont utilisés pour réellement diviser les données en branches et en feuilles ? Il existe diverses méthodes qui peuvent être utilisées pour diviser un arbre, mais la méthode la plus courante de division est probablement une technique appelée « division binaire récursive ». Lorsque cette méthode de division est effectuée, le processus commence à la racine et le nombre de fonctionnalités du jeu de données représente le nombre possible de divisions possibles. Une fonction est utilisée pour déterminer combien d’exactitude chaque division possible coûtera, et la division est effectuée en utilisant les critères qui sacrifient le moins d’exactitude. Ce processus est effectué de manière récursive et des sous-groupes sont formés en utilisant la même stratégie générale.
Afin de déterminer le coût de la division, une fonction de coût est utilisée. Une fonction de coût différente est utilisée pour les tâches de régression et les tâches de classification. L’objectif des deux fonctions de coût est de déterminer quels branches ont les valeurs de réponse les plus similaires, ou les branches les plus homogènes. Considérez que vous souhaitez que les données de test d’une certaine classe suivent certains chemins et cela a du sens intuitif.
En termes de fonction de coût de régression pour la division binaire récursive, l’algorithme utilisé pour calculer le coût est le suivant :
somme(y – prédiction)^2
La prédiction pour un groupe particulier de points de données est la moyenne des réponses des données d’entraînement pour ce groupe. Tous les points de données sont exécutés à travers la fonction de coût pour déterminer le coût de toutes les divisions possibles et la division avec le coût le plus bas est sélectionnée.
En ce qui concerne la fonction de coût pour la classification, la fonction est la suivante :
G = somme(pk * (1 – pk))
Ceci est le score Gini, et c’est une mesure de l’efficacité d’une division, basée sur le nombre d’instances de différentes classes dans les groupes résultant de la division. En d’autres termes, cela quantifie à quel point les groupes sont mélangés après la division. Une division optimale est lorsque tous les groupes résultant de la division ne contiennent que des entrées d’une seule classe. Si une division optimale a été créée, la valeur « pk » sera soit 0, soit 1 et G sera égal à zéro. Vous pourriez être capable de deviner que la pire division est celle où il y a une représentation 50-50 des classes dans la division, dans le cas de la classification binaire. Dans ce cas, la valeur « pk » serait 0,5 et G serait également 0,5.
Le processus de division est terminé lorsque tous les points de données ont été transformés en feuilles et classés. Cependant, vous pouvez vouloir arrêter la croissance de l’arbre plus tôt. Les arbres complexes et grands sont sujets à la surajustement, mais plusieurs méthodes différentes peuvent être utilisées pour lutter contre cela. Une méthode pour réduire la surajustement est de spécifier un nombre minimum de points de données qui seront utilisés pour créer une feuille. Une autre méthode pour contrôler la surajustement est de restreindre l’arbre à une certaine profondeur maximale, ce qui contrôle la longueur d’un chemin allant de la racine à une feuille.
Un autre processus impliqué dans la création d’arbres de décision est la taille. La taille peut aider à améliorer les performances d’un arbre de décision en supprimant les branches contenant des fonctionnalités qui ont peu de puissance prédictive / peu d’importance pour le modèle. De cette façon, la complexité de l’arbre est réduite, il est moins susceptible de surajuster et l’utilité prédictive du modèle est augmentée.
Lorsque vous effectuez une taille, le processus peut commencer soit au sommet de l’arbre, soit à la base de l’arbre. Cependant, la méthode la plus simple de taille est de commencer par les feuilles et d’essayer de supprimer le nœud qui contient la classe la plus commune dans cette feuille. Si l’exactitude du modèle ne se dégrade pas lorsque cela est fait, alors le changement est préservé. Il existe d’autres techniques utilisées pour effectuer une taille, mais la méthode décrite ci-dessus – la taille d’erreur réduite – est probablement la méthode la plus courante de taille d’arbre de décision.
Considérations pour l’utilisation des arbres de décision
Les arbres de décision sont souvent utiles lorsque la classification doit être effectuée mais que le temps de calcul est une contrainte majeure. Les arbres de décision peuvent montrer clairement quelles fonctionnalités dans les jeux de données choisis ont le plus de puissance prédictive. De plus, contrairement à de nombreux algorithmes d’apprentissage automatique où les règles utilisées pour classer les données peuvent être difficiles à interpréter, les arbres de décision peuvent rendre des règles interprétables. Les arbres de décision sont également capables d’utiliser à la fois des variables catégorielles et des variables continues, ce qui signifie que moins de prétraitement est nécessaire, par rapport aux algorithmes qui ne peuvent gérer qu’un seul type de variable.
Les arbres de décision ont tendance à ne pas performer très bien lorsqu’ils sont utilisés pour déterminer les valeurs d’attributs continus. Une autre limitation des arbres de décision est que, lors de la classification, s’il y a peu d’exemples d’entraînement mais de nombreuses classes, l’arbre de décision a tendance à être imprécis.








