Angle d’Anderson
Andrew Ng critique la culture de sur-ajustement dans l’apprentissage automatique
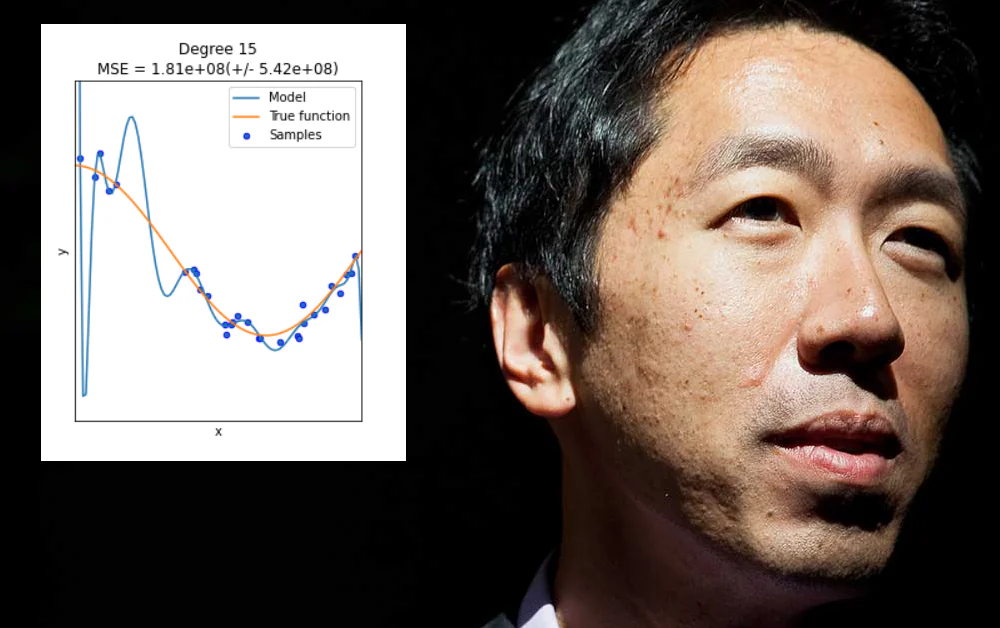
Andrew Ng, l’une des voix les plus influentes dans l’apprentissage automatique au cours de la dernière décennie, exprime actuellement des inquiétudes quant à l’importance accordée aux innovations dans l’architecture des modèles par rapport aux données – et plus précisément, à la mesure dans laquelle elle permet des résultats « sur-ajustés » à être présentés comme des solutions généralisées ou des progrès.
Ces critiques de la culture actuelle de l’apprentissage automatique, émanant de l’une de ses plus hautes autorités, ont des implications pour la confiance dans un secteur confronté à des craintes concernant un troisième effondrement de la confiance des entreprises dans le développement de l’IA au cours d’une période de soixante ans.
Ng, professeur à l’université de Stanford, est également l’un des fondateurs de deeplearning.ai, et en mars, il a publié un message sur le site de l’organisation qui a distillé un discours récent en deux recommandations essentielles :
Premièrement, que la communauté de recherche devrait cesser de se plaindre que le nettoyage des données représente 80 % des défis de l’apprentissage automatique, et se mettre au travail pour développer des méthodologies et des pratiques MLOps robustes.
Deuxièmement, qu’elle devrait s’éloigner des « victoires faciles » qui peuvent être obtenues en sur-ajustant les données à un modèle d’apprentissage automatique, de sorte qu’il fonctionne bien sur ce modèle mais échoue à généraliser ou à produire un modèle largement déployable.
Accepter le défi de l’architecture et de la curation des données
« Mon point de vue », a écrit Ng, « est que si 80 % de notre travail consiste à préparer les données, alors assurer la qualité des données est le travail important d’une équipe d’apprentissage automatique. »
Il a poursuivi :
« Plutôt que de compter sur les ingénieurs pour trouver par hasard la meilleure façon d’améliorer un ensemble de données, j’espère que nous pouvons développer des outils MLOps qui aident à rendre la construction de systèmes d’IA, y compris la construction de jeux de données de haute qualité, plus répétitive et systématique.
« MLOps est un domaine naissant, et les gens le définissent différemment. Mais je pense que le principe d’organisation le plus important des équipes et des outils MLOps devrait être d’assurer le flux constant et de haute qualité des données à toutes les étapes d’un projet. Cela aidera de nombreux projets à aller plus en douceur. »
Lors d’une session de questions-réponses en direct sur Zoom à la fin avril, Ng a abordé le déficit d’applicabilité des systèmes d’analyse d’apprentissage automatique en radiologie :
« Il s’avère que lorsque nous collectons des données de l’hôpital de Stanford, puis que nous formons et testons sur des données de l’hôpital, en effet, nous pouvons publier des articles montrant [les algorithmes] sont comparables aux radiologues humains pour détecter certaines conditions.
« … [Lorsque] vous prenez le même modèle, le même système d’IA, à un hôpital plus ancien dans la rue, avec une machine plus ancienne, et que le technicien utilise un protocole d’imagerie légèrement différent, les données dérivent pour causer la dégradation significative des performances du système d’IA. En revanche, tout radiologue humain peut se rendre à l’hôpital plus ancien et faire très bien. »
La sous-spécification n’est pas une solution
Le sur-ajustement se produit lorsqu’un modèle d’apprentissage automatique est spécifiquement conçu pour accommoder les excentricités d’un ensemble de données particulier (ou de la façon dont les données sont formatées). Cela peut impliquer, par exemple, la spécification de poids qui produiront de bons résultats à partir de cet ensemble de données, mais ne « généraliseront » pas sur d’autres données.
Dans de nombreux cas, de tels paramètres sont définis sur des aspects « non-données » de l’ensemble de formation, tels que la résolution spécifique des informations collectées, ou d’autres particularités qui ne sont pas garanties pour se reproduire dans d’autres ensembles de données ultérieurs.
Bien qu’il serait agréable, le sur-ajustement n’est pas un problème qui peut être résolu en élargissant aveuglément la portée ou la flexibilité de l’architecture des données ou de la conception du modèle, lorsque ce qui est réellement nécessaire, ce sont des fonctionnalités largement applicables et très pertinentes qui fonctionneront bien dans une gamme d’environnements de données – un défi plus épineux.
En général, ce type de « sous-spécification » ne conduit qu’aux problèmes que Ng a récemment décrits, où un modèle d’apprentissage automatique échoue sur des données non vues. La différence dans ce cas est que le modèle échoue non pas parce que les données ou le formatage des données sont différents de l’ensemble de formation original sur-ajusté, mais parce que le modèle est trop flexible plutôt que trop fragile.
À la fin de 2020, l’article Underspecification Presents Challenges for Credibility in Modern Machine Learning a critiqué vivement cette pratique, et portait les noms de pas moins de quarante chercheurs et scientifiques en apprentissage automatique de Google et du MIT, entre autres institutions.
L’article critique l’apprentissage par « raccourci », et observe la façon dont les modèles sous-spécifiés peuvent prendre des tangentes sauvages en fonction du point de départ aléatoire auquel la formation du modèle commence. Les contributeurs observent :
« Nous avons vu que la sous-spécification est ubiquitaire dans les pipelines d’apprentissage automatique pratiques dans de nombreux domaines. En effet, grâce à la sous-spécification, des aspects substantiellement importants des décisions sont déterminés par des choix arbitraires tels que la graine aléatoire utilisée pour l’initialisation des paramètres. »
Les ramifications économiques du changement de culture
Malgré ses références universitaires, Ng n’est pas un universitaire détaché, mais a une expérience industrielle approfondie en tant que co-fondateur de Google Brain et Coursera, ancien scientifique en chef pour les données et l’IA chez Baidu, et fondateur de Landing AI, qui administre 175 millions de dollars pour de nouvelles startups dans le secteur.
Lorsqu’il dit « Tout l’IA, et non seulement la santé, a un écart entre la preuve de concept et la production », il s’agit d’un appel à l’éveil pour un secteur dont le niveau actuel de hype et d’histoire tachetée l’a de plus en plus caractérisé comme un investissement commercial incertain à long terme, confronté à des problèmes de définition et de portée.
Cependant, les systèmes d’apprentissage automatique propriétaires qui fonctionnent bien in situ et échouent dans d’autres environnements représentent le type de capture de marché qui pourrait récompenser l’investissement industriel. La présentation du « problème de sur-ajustement » dans le contexte d’un danger professionnel offre une façon déloyale de monétiser l’investissement corporatif dans la recherche open source, et de produire (effectivement) des systèmes propriétaires où la réplication par les concurrents est possible, mais problématique.
Que cette approche fonctionnerait à long terme dépend de la mesure dans laquelle les véritables avancées en apprentissage automatique continueront à nécessiter des niveaux d’investissement de plus en plus élevés, et si toutes les initiatives productives migreront inévitablement vers FAANG à un certain degré, en raison des ressources colossales nécessaires pour l’hébergement et les opérations.












