IA 101
Qu’est-ce que le théorème de Bayes ?
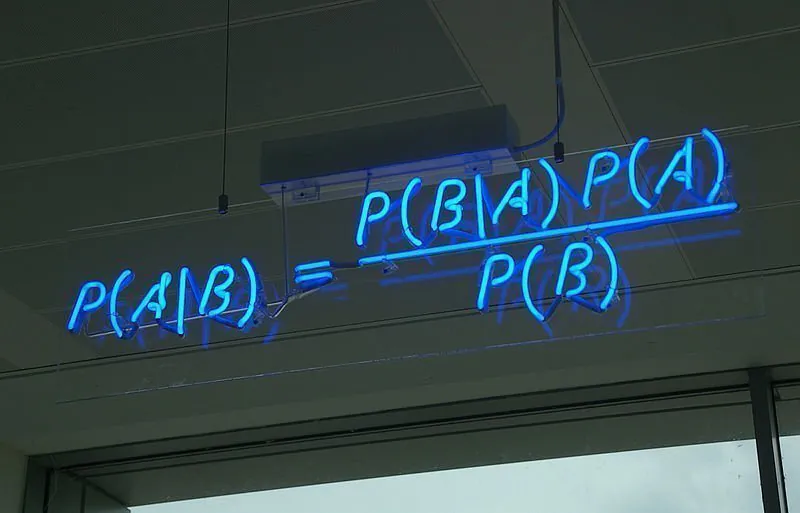
Si vous avez appris sur la science des données ou l’apprentissage automatique, il y a de fortes chances que vous ayez entendu le terme « théorème de Bayes » auparavant, ou un « classifieur Bayes ». Ces concepts peuvent être quelque peu déroutants, surtout si vous n’êtes pas habitué à penser à la probabilité d’un point de vue statistique traditionnel, fréquentiste. Cet article tentera d’expliquer les principes derrière le théorème de Bayes et comment il est utilisé dans l’apprentissage automatique.
Qu’est-ce que le théorème de Bayes ?
Le théorème de Bayes est une méthode de calcul de la probabilité conditionnelle. La méthode traditionnelle de calcul de la probabilité conditionnelle (la probabilité qu’un événement se produise étant donné la survenance d’un autre événement) consiste à utiliser la formule de probabilité conditionnelle, en calculant la probabilité conjointe de l’événement un et de l’événement deux se produisant en même temps, puis en divisant par la probabilité de l’événement deux se produisant. Cependant, la probabilité conditionnelle peut également être calculée d’une manière légèrement différente en utilisant le théorème de Bayes.
Lors du calcul de la probabilité conditionnelle avec le théorème de Bayes, vous utilisez les étapes suivantes :
- Déterminez la probabilité que la condition B soit vraie, en supposant que la condition A est vraie.
- Déterminez la probabilité que l’événement A soit vrai.
- Multiplication des deux probabilités ensemble.
- Divisez par la probabilité de l’événement B se produisant.
Cela signifie que la formule du théorème de Bayes pourrait être exprimée comme suit :
P(A|B) = P(B|A)*P(A) / P(B)
Le calcul de la probabilité conditionnelle de cette manière est particulièrement utile lorsque la probabilité conditionnelle inverse peut être facilement calculée, ou lorsque le calcul de la probabilité conjointe serait trop difficile.
Exemple du théorème de Bayes
Ceci pourrait être plus facile à interpréter si nous passions un peu de temps à regarder un exemple de la façon dont vous appliqueriez un raisonnement bayésien et le théorème de Bayes. Supposons que vous jouiez à un jeu simple où plusieurs participants vous racontent une histoire et que vous devez déterminer lequel des participants vous ment. Remplissons l’équation du théorème de Bayes avec les variables de ce scénario hypothétique.
Nous essayons de prédire si chaque individu du jeu ment ou dit la vérité, donc si il y a trois joueurs à part vous, les variables catégorielles peuvent être exprimées comme A1, A2 et A3. Les preuves de leurs mensonges ou de leur véracité sont leur comportement. Comme lors d’un jeu de poker, vous chercheriez certains « signes » qu’une personne ment et vous les utiliseriez comme informations pour éclairer votre supposition. Ou si vous étiez autorisé à les interroger, ce serait toute preuve que leur histoire ne tient pas debout. Nous pouvons représenter les preuves qu’une personne ment comme B.
Pour être clair, nous visons à prédire la probabilité (A ment/dit la vérité | étant donné les preuves de son comportement). Pour ce faire, nous voudrions déterminer la probabilité de B étant donné A, ou la probabilité que son comportement se produise étant donné que la personne ment vraiment ou dit la vérité. Vous essayez de déterminer dans quelles conditions le comportement que vous voyez aurait le plus de sens. Si vous êtes témoin de trois comportements, vous feriez le calcul pour chaque comportement. Par exemple, P(B1, B2, B3 * A). Vous feriez ensuite cela pour chaque occurrence de A/pour chaque personne du jeu en dehors de vous. C’est cette partie de l’équation ci-dessus :
P(B1, B2, B3,|A) * P|A
Enfin, nous divisons simplement cela par la probabilité de B.
Si nous recevions des preuves sur les probabilités réelles de cette équation, nous recréerions notre modèle de probabilité, en tenant compte des nouvelles preuves. Cela s’appelle la mise à jour de nos a priori, car nous mettons à jour nos hypothèses sur la probabilité a priori des événements observés.
Applications d’apprentissage automatique pour le théorème de Bayes
L’utilisation la plus courante du théorème de Bayes lorsqu’il s’agit d’apprentissage automatique est sous la forme de l’algorithme Naive Bayes.
Naive Bayes est utilisé pour la classification de jeux de données binaires et multiclasse, Naive Bayes tire son nom du fait que les valeurs attribuées aux preuves des témoins/attributs – Bs dans P(B1, B2, B3 * A) – sont supposées être indépendantes les unes des autres. On suppose que ces attributs n’ont pas d’impact les uns sur les autres afin de simplifier le modèle et de rendre les calculs possibles, au lieu d’essayer de calculer les relations entre chaque attribut. Malgré ce modèle simplifié, Naive Bayes a tendance à performer quite bien en tant qu’algorithme de classification, même lorsque cette hypothèse n’est probablement pas vraie (ce qui est le plus souvent).
Il existe également des variantes couramment utilisées du classifieur Naive Bayes, telles que Multinomial Naive Bayes, Bernoulli Naive Bayes et Gaussian Naive Bayes.
L’algorithme Multinomial Naive Bayes est souvent utilisé pour classer les documents, car il est efficace pour interpréter la fréquence des mots dans un document.
L’algorithme Bernoulli Naive Bayes fonctionne de manière similaire à Multinomial Naive Bayes, mais les prédictions rendues par l’algorithme sont des booléens. Cela signifie que lors de la prédiction d’une classe, les valeurs seront binaires, non ou oui. Dans le domaine de la classification de texte, un algorithme Bernoulli Naive Bayes attribuerait les paramètres un oui ou non en fonction de la présence ou de l’absence d’un mot dans le document.
Si la valeur des prédicteurs/caractéristiques n’est pas discrète mais continue, Gaussian Naive Bayes peut être utilisé. On suppose que les valeurs des caractéristiques continues ont été échantillonnées à partir d’une distribution gaussienne.












