
AI 101
Qu'est-ce qu'un réseau antagoniste génératif (GAN) ?
Réseaux Génératifs d'Adversariat (GAN) sont des types d'architectures de réseaux de neurones capable de générer de nouvelles données qui se conforme aux modèles appris. Les GAN peuvent être utilisés pour générer des images de visages humains ou d'autres objets, pour effectuer une traduction de texte en image, pour convertir un type d'image en un autre et pour améliorer la résolution des images (super résolution) entre autres applications. Parce que les GAN peuvent générer des données entièrement nouvelles, ils sont à la tête de nombreux systèmes, applications et recherches d'IA de pointe. Mais comment fonctionnent exactement les GAN ? Explorons le fonctionnement des GAN et examinons certaines de leurs principales utilisations.
Définition des modèles génératifs et des GAN
Un GAN est un exemple de modèle génératif. La plupart des modèles d'IA peuvent être divisés en deux catégories : modèles supervisés et non supervisés. Les modèles d'apprentissage supervisé sont généralement utilisés pour discriminer entre différentes catégories d'entrées, à classer. En revanche, les modèles non supervisés sont généralement utilisés pour résumer la distribution des données, apprenant souvent une distribution gaussienne des données. Parce qu'ils apprennent la distribution d'un ensemble de données, ils peuvent extraire des échantillons de cette distribution apprise et générer de nouvelles données.
Différents modèles génératifs ont différentes méthodes de génération de données et de calcul des distributions de probabilité. Par exemple, le Modèle Bayes naïf fonctionne en calculant une distribution de probabilité pour les différentes caractéristiques d'entrée et la classe générative. Lorsque le modèle Naive Bayes rend une prédiction, il calcule la classe la plus probable en prenant la probabilité des différentes variables et en les combinant. D'autres modèles génératifs d'apprentissage non profond incluent les modèles de mélange gaussien et l'allocation latente de Dirichlet (LDA). Modèles génératifs basés sur le Deep Leaning comprendre Machines Boltzmann restreintes (RBM), Autoencodeurs variationnels (VAE), et bien sûr, les GAN.
Les réseaux antagonistes génératifs étaient proposé pour la première fois par Ian Goodfellow en 2014, et ils ont été améliorés par Alec Redford et d'autres chercheurs en 2015, conduisant à une architecture standardisée pour les GAN. Les GAN sont en fait deux réseaux différents reliés entre eux. Les GAN sont composé de deux moitiés : un modèle de génération et un modèle de discrimination, également appelés générateur et discriminateur.
L'architecture du GAN
Les réseaux antagonistes génératifs sont construit à partir d'un modèle générateur et d'un modèle discriminateur réunis. Le travail du modèle générateur consiste à créer de nouveaux exemples de données, basés sur les modèles que le modèle a appris à partir des données d'apprentissage. Le travail du modèle discriminateur est d'analyser des images (en supposant qu'il est formé sur des images) et de déterminer si les images sont générées/fausses ou authentiques.

Les deux modèles sont opposés l'un à l'autre, entraînés à la manière d'une théorie des jeux. Le but du modèle générateur est de produire des images qui trompent son adversaire, le modèle discriminateur. Pendant ce temps, le travail du modèle discriminateur est de vaincre son adversaire, le modèle générateur, et d'attraper les fausses images produites par le générateur. Le fait que les modèles s'opposent entraîne une course aux armements où les deux modèles s'améliorent. Le discriminateur obtient une rétroaction sur les images qui étaient authentiques et celles qui ont été produites par le générateur, tandis que le générateur reçoit des informations sur lesquelles de ses images ont été signalées comme fausses par le discriminateur. Les deux modèles s'améliorent pendant la formation, dans le but de former un modèle de génération qui peut produire de fausses données qui sont fondamentalement impossibles à distinguer des données réelles et authentiques.
Une fois qu'une distribution gaussienne des données a été créée pendant la formation, le modèle génératif peut être utilisé. Le modèle du générateur est initialement alimenté par un vecteur aléatoire, qu'il transforme en fonction de la distribution gaussienne. En d'autres termes, le vecteur sème la génération. Lorsque le modèle est formé, l'espace vectoriel sera une version compressée, ou une représentation, de la distribution gaussienne des données. La version compressée de la distribution des données est appelée espace latent ou variables latentes. Plus tard, le modèle GAN peut alors prendre la représentation de l'espace latent et en tirer des points, qui peuvent être donnés au modèle de génération et utilisés pour générer de nouvelles données très similaires aux données d'apprentissage.
Le modèle de discriminateur est alimenté par des exemples de l'ensemble du domaine de formation, qui est composé d'exemples de données réels et générés. Les vrais exemples sont contenus dans l'ensemble de données d'apprentissage, tandis que les fausses données sont produites par le modèle génératif. Le processus de formation du modèle de discriminateur est exactement le même que la formation de base du modèle de classification binaire.
Processus de formation GAN
Regardons l'ensemble Formation processus pour une tâche hypothétique de génération d'images.
Pour commencer, le GAN est formé à l'aide d'images authentiques et réelles dans le cadre de l'ensemble de données de formation. Cela configure le modèle de discriminateur pour faire la distinction entre les images générées et les images réelles. Il produit également la distribution des données que le générateur utilisera pour produire de nouvelles données.
Le générateur prend un vecteur de données numériques aléatoires et les transforme en fonction de la distribution gaussienne, renvoyant une image. Ces images générées, ainsi que certaines images authentiques de l'ensemble de données de formation, sont introduites dans le modèle de discriminateur. Le discriminateur rendra une prédiction probabiliste sur la nature des images qu'il reçoit, en produisant une valeur comprise entre 0 et 1, où 1 correspond généralement à des images authentiques et 0 à une fausse image.
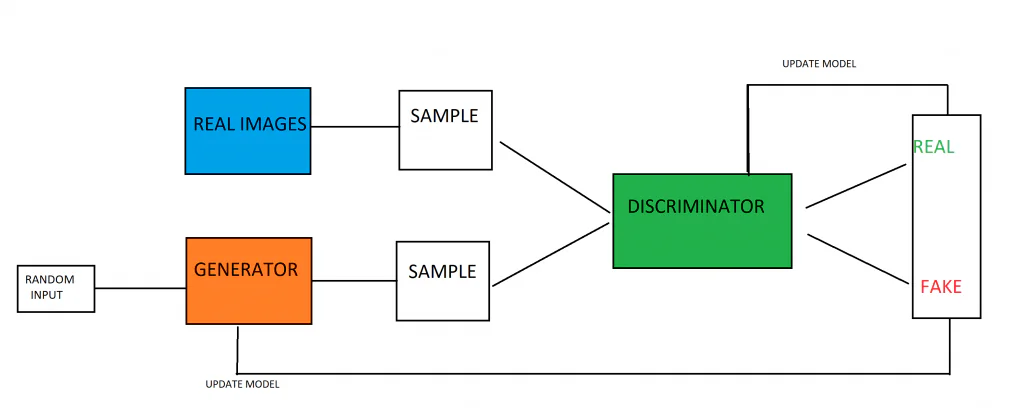
Il y a une double boucle de rétroaction en jeu, car le discriminateur au sol reçoit la vérité au sol des images, tandis que le générateur reçoit un retour sur ses performances par le discriminateur.
Les modèles génératif et de discrimination jouent entre eux un jeu à somme nulle. Un jeu à somme nulle est un jeu où les gains d'un côté se font au détriment de l'autre côté (la somme des deux actions est égale à zéro ex). Lorsque le modèle de discriminateur est capable de distinguer avec succès les exemples réels et faux, aucune modification n'est apportée aux paramètres du discriminateur. Cependant, des mises à jour importantes sont apportées aux paramètres du modèle lorsqu'il ne parvient pas à faire la distinction entre les images réelles et fausses. L'inverse est vrai pour le modèle génératif, il est pénalisé (et ses paramètres mis à jour) lorsqu'il ne trompe pas le modèle discriminatif, mais sinon ses paramètres sont inchangés (ou il est récompensé).
Idéalement, le générateur est capable d'améliorer ses performances à un point où le discriminateur ne peut pas discerner entre les images fausses et réelles. Cela signifie que le discriminateur aura toujours des probabilités de rendu de % 50 pour les images réelles et fausses, ce qui signifie que les images générées doivent être indiscernables des images authentiques. En pratique, les GAN n'atteindront généralement pas ce point. Cependant, le modèle génératif n'a pas besoin de créer des images parfaitement similaires pour être toujours utile pour les nombreuses tâches pour lesquelles les GAN sont utilisés.
Applications GAN
Les GAN ont un certain nombre d'applications différentes, la plupart d'entre elles tournant autour de la génération d'images et de composants d'images. Les GAN sont couramment utilisés dans les tâches où les données d'image requises sont manquantes ou limitées dans une certaine mesure, comme méthode de génération des données requises. Examinons quelques-uns des cas d'utilisation courants des GAN.
Génération de nouveaux exemples pour les ensembles de données
Les GAN peuvent être utilisés pour générer de nouveaux exemples d'ensembles de données d'images simples. Si vous n'avez qu'une poignée d'exemples de formation et que vous en avez besoin de plus, les GAN peuvent être utilisés pour générer de nouvelles données de formation pour un classificateur d'images, générant de nouveaux exemples de formation à différentes orientations et angles.
Générer des visages humains uniques

La femme sur cette photo n'existe pas. L'image a été générée par StyleGAN. Photo : Owlsmcgee via Wikimedia Commons, domaine public (https://commons.wikimedia.org/wiki/File:Woman_1.jpg)
Lorsqu'ils sont suffisamment formés, les GAN peuvent être utilisés pour générer des images extrêmement réalistes de visages humains. Ces images générées peuvent être utilisées pour aider à former des systèmes de reconnaissance faciale.
Traduction d'image à image
GAN exceller dans la traduction d'images. Les GAN peuvent être utilisés pour coloriser des images en noir et blanc, traduire des croquis ou des dessins en images photographiques ou convertir des images du jour à la nuit.
Traduction de texte en image
La traduction de texte en image est possible grâce à l'utilisation des GAN. Lorsqu'il est fourni avec un texte décrivant une image et l'image qui l'accompagne, un GAN peut être formé pour créer une nouvelle image lorsqu'il est fourni avec une description de l'image souhaitée.
Édition et réparation d'images
Les GAN peuvent être utilisés pour éditer des photographies existantes. GAN supprimer des éléments comme la pluie ou la neige à partir d'une image, mais ils peuvent également être utilisés pour réparer les anciennes images endommagées ou les images corrompues.
Super résolution
La super résolution est le processus qui consiste à prendre une image basse résolution et à insérer plus de pixels dans l'image, améliorant ainsi la résolution de cette image. Les GAN peuvent être formés pour prendre une image et générer une version à plus haute résolution de cette image.














