
AI 101
Qu'est-ce que la réduction de dimensionnalité ?
Qu'est-ce que la réduction de dimensionnalité ?
Réduction dimensionnelle est un processus utilisé pour réduire la dimensionnalité d'un jeu de données, en prenant de nombreuses fonctionnalités et en les représentant comme moins de fonctionnalités. Par exemple, la réduction de la dimensionnalité peut être utilisée pour réduire un jeu de données de vingt fonctionnalités à quelques fonctionnalités seulement. La réduction de dimensionnalité est couramment utilisée dans apprentissage non supervisé tâches pour créer automatiquement des classes à partir de nombreuses fonctionnalités. Afin de mieux comprendre pourquoi et comment la réduction de dimensionnalité est utilisée, nous examinerons les problèmes associés aux données de grande dimension et les méthodes les plus courantes de réduction de la dimensionnalité.
Plus de dimensions conduit à un surajustement
La dimensionnalité fait référence au nombre d'entités/colonnes dans un jeu de données.
On suppose souvent que dans l’apprentissage automatique, plus de fonctionnalités sont meilleures, car cela crée un modèle plus précis. Cependant, plus de fonctionnalités ne se traduisent pas nécessairement par un meilleur modèle.
Les caractéristiques d'un ensemble de données peuvent varier considérablement en termes d'utilité pour le modèle, de nombreuses caractéristiques n'ayant que peu d'importance. De plus, plus l'ensemble de données contient d'entités, plus il faut d'échantillons pour s'assurer que les différentes combinaisons d'entités sont bien représentées dans les données. Par conséquent, le nombre d'échantillons augmente proportionnellement au nombre de caractéristiques. Plus d'échantillons et plus de fonctionnalités signifient que le modèle doit être plus complexe, et à mesure que les modèles deviennent plus complexes, ils deviennent plus sensibles au surajustement. Le modèle apprend trop bien les modèles dans les données de formation et il ne parvient pas à généraliser à des données hors échantillon.
Réduire la dimensionnalité d'un ensemble de données présente plusieurs avantages. Comme mentionné, les modèles plus simples sont moins sujets au surajustement, car le modèle doit faire moins d'hypothèses sur la façon dont les caractéristiques sont liées les unes aux autres. De plus, moins de dimensions signifient que moins de puissance de calcul est nécessaire pour entraîner les algorithmes. De même, moins d'espace de stockage est nécessaire pour un ensemble de données qui a une dimensionnalité plus petite. La réduction de la dimensionnalité d'un jeu de données peut également vous permettre d'utiliser des algorithmes inadaptés aux jeux de données comportant de nombreuses fonctionnalités.
Méthodes courantes de réduction de la dimensionnalité
La réduction de la dimensionnalité peut se faire par sélection de caractéristiques ou par ingénierie de caractéristiques. La sélection des caractéristiques est l'endroit où l'ingénieur identifie les caractéristiques les plus pertinentes de l'ensemble de données, tandis que ingénierie des fonctionnalités est le processus de création de nouvelles fonctionnalités en combinant ou en transformant d'autres fonctionnalités.
La sélection et l'ingénierie des fonctionnalités peuvent être effectuées par programmation ou manuellement. Lors de la sélection et de l'ingénierie manuelles des fonctionnalités, la visualisation des données pour découvrir les corrélations entre les fonctionnalités et les classes est typique. La réduction de la dimensionnalité de cette manière peut prendre beaucoup de temps et, par conséquent, certaines des manières les plus courantes de réduire la dimensionnalité impliquent l'utilisation d'algorithmes disponibles dans des bibliothèques telles que Scikit-learn pour Python. Ces algorithmes courants de réduction de la dimensionnalité comprennent : l'analyse en composantes principales (ACP), la décomposition en valeurs singulières (SVD) et l'analyse discriminante linéaire (LDA).
Les algorithmes utilisés pour la réduction de dimensionnalité pour les tâches d'apprentissage non supervisées sont généralement PCA et SVD, tandis que ceux utilisés pour la réduction de dimensionnalité d'apprentissage supervisé sont généralement LDA et PCA. Dans le cas des modèles d'apprentissage supervisé, les fonctionnalités nouvellement générées sont simplement introduites dans le classificateur d'apprentissage automatique. Notez que les utilisations décrites ici ne sont que des cas d'utilisation généraux et ne sont pas les seules conditions dans lesquelles ces techniques peuvent être utilisées. Les algorithmes de réduction de dimensionnalité décrits ci-dessus sont simplement des méthodes statistiques et sont utilisés en dehors des modèles d'apprentissage automatique.
Analyse des composants principaux

Photo : Matrice avec principaux composants identifiés
Analyse en composantes principales (ACP) est une méthode statistique qui analyse les caractéristiques/caractéristiques d'un ensemble de données et résume les caractéristiques les plus influentes. Les caractéristiques de l'ensemble de données sont combinées dans des représentations qui conservent la plupart des caractéristiques des données, mais sont réparties sur moins de dimensions. Vous pouvez considérer cela comme « écraser » les données d'une représentation de dimension supérieure à une représentation avec seulement quelques dimensions.
Comme exemple d'une situation où l'ACP pourrait être utile, réfléchissez aux différentes façons dont on pourrait décrire le vin. Bien qu'il soit possible de décrire le vin en utilisant de nombreuses caractéristiques très spécifiques telles que les niveaux de CO2, les niveaux d'aération, etc., ces caractéristiques spécifiques peuvent être relativement inutiles lorsque vous essayez d'identifier un type de vin spécifique. Au lieu de cela, il serait plus prudent d'identifier le type en fonction de caractéristiques plus générales telles que le goût, la couleur et l'âge. L'ACP peut être utilisée pour combiner des fonctionnalités plus spécifiques et créer des fonctionnalités plus générales, utiles et moins susceptibles de provoquer un surajustement.
L'ACP est effectuée en déterminant comment les caractéristiques d'entrée varient par rapport à la moyenne les unes par rapport aux autres, en déterminant s'il existe des relations entre les caractéristiques. Pour ce faire, une matrice covariante est créée, établissant une matrice composée des covariances par rapport aux paires possibles des caractéristiques du jeu de données. Ceci est utilisé pour déterminer les corrélations entre les variables, avec une covariance négative indiquant une corrélation inverse et une corrélation positive indiquant une corrélation positive.
Les composants principaux (les plus influents) de l'ensemble de données sont créés en créant des combinaisons linéaires des variables initiales, ce qui se fait à l'aide de concepts d'algèbre linéaire appelés Valeurs propres et vecteurs propres. Les combinaisons sont créées de manière à ce que les composantes principales ne soient pas corrélées entre elles. La plupart des informations contenues dans les variables initiales sont compressées dans les premières composantes principales, ce qui signifie que de nouvelles fonctionnalités (les composantes principales) ont été créées qui contiennent les informations de l'ensemble de données d'origine dans un espace dimensionnel plus petit.
Décomposition en valeur singulière
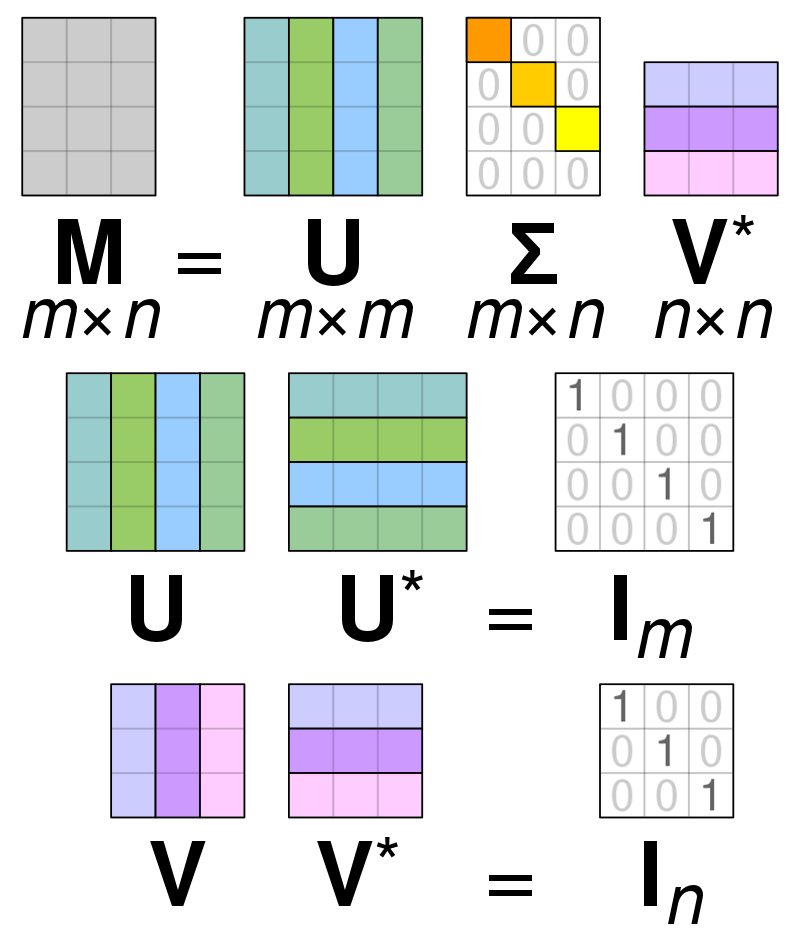
Photo : Par Cmglee – Travail personnel, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
Décomposition en valeurs singulières (SVD) is utilisé pour simplifier les valeurs dans une matrice, réduisant la matrice à ses éléments constitutifs et facilitant les calculs avec cette matrice. SVD peut être utilisé à la fois pour les matrices de valeurs réelles et complexes, mais pour les besoins de cette explication, nous examinerons comment décomposer une matrice de valeurs réelles.
Supposons que nous ayons une matrice composée de données à valeur réelle et que notre objectif soit de réduire le nombre de colonnes/caractéristiques dans la matrice, similaire à l'objectif de l'ACP. Comme PCA, SVD comprimera la dimensionnalité de la matrice tout en préservant autant que possible la variabilité de la matrice. Si nous voulons opérer sur la matrice A, nous pouvons représenter la matrice A comme trois autres matrices appelées U, D et V. La matrice A est composée des éléments x * y d'origine tandis que la matrice U est composée des éléments X * X (il est une matrice orthogonale). La matrice V est une matrice orthogonale différente contenant y * y éléments. La matrice D contient les éléments x * y et c'est une matrice diagonale.
Afin de décomposer les valeurs de la matrice A, nous devons convertir les valeurs originales de la matrice singulière en valeurs diagonales trouvées dans une nouvelle matrice. Lorsque vous travaillez avec des matrices orthogonales, leurs propriétés ne changent pas si elles sont multipliées par d'autres nombres. Par conséquent, nous pouvons approximer la matrice A en tirant parti de cette propriété. Lorsque nous multiplions les matrices orthogonales avec une transposition de la matrice V, le résultat est une matrice équivalente à notre A d'origine.
Lorsque la matrice a est décomposée en matrices U, D et V, elles contiennent les données trouvées dans la matrice A. Cependant, les colonnes les plus à gauche des matrices contiendront la majorité des données. Nous pouvons prendre seulement ces premières colonnes et avoir une représentation de la matrice A qui a beaucoup moins de dimensions et la plupart des données dans A.
Analyse discriminante linéaire

Gauche : Matrice avant LDA, Droite : Axe après LDA, maintenant séparable
Analyse discriminante linéaire (LDA) est un processus qui prend les données d'un graphique multidimensionnel et le reprojette sur un graphe linéaire. Vous pouvez imaginer cela en pensant à un graphique bidimensionnel rempli de points de données appartenant à deux classes différentes. Supposons que les points soient éparpillés de sorte qu'aucune ligne ne puisse être tracée qui sépare nettement les deux classes différentes. Afin de gérer cette situation, les points trouvés dans le graphe 2D peuvent être réduits à un graphe 1D (une ligne). Cette ligne aura tous les points de données répartis sur elle et elle peut, espérons-le, être divisée en deux sections qui représentent la meilleure séparation possible des données.
Lors de la réalisation de LDA, il y a deux objectifs principaux. Le premier objectif est de minimiser la variance pour les classes, tandis que le second objectif est de maximiser la distance entre les moyennes des deux classes. Ces objectifs sont atteints en créant un nouvel axe qui existera dans le graphique 2D. L'axe nouvellement créé agit pour séparer les deux classes en fonction des objectifs décrits précédemment. Une fois l'axe créé, les points trouvés dans le graphe 2D sont placés le long de l'axe.
Trois étapes sont nécessaires pour déplacer les points d'origine vers une nouvelle position le long du nouvel axe. Dans la première étape, la distance entre les moyennes des classes individuelles (la variance inter-classes) est utilisée pour calculer la séparabilité des classes. Dans la deuxième étape, la variance au sein des différentes classes est calculée, en déterminant la distance entre l'échantillon et la moyenne de la classe en question. Dans la dernière étape, l'espace de dimension inférieure qui maximise la variance entre les classes est créé.
La technique LDA obtient les meilleurs résultats lorsque les moyennes des classes cibles sont éloignées les unes des autres. LDA ne peut pas séparer efficacement les classes avec un axe linéaire si les moyennes des distributions se chevauchent.










