IA 101
Qu’est-ce que les RNN et les LSTMs dans l’apprentissage profond ?
Beaucoup des avancées les plus impressionnantes dans le traitement automatique des langues et les chatbots IA sont alimentées par les Réseaux de Neurones Récurrents (RNN) et les réseaux de mémoire à court terme (LSTM). Les RNN et les LSTMs sont des architectures de réseaux de neurones spéciales capables de traiter des données séquentielles, des données où l’ordre chronologique compte. Les LSTMs sont essentiellement des versions améliorées des RNN, capables d’interpréter des séquences de données plus longues. Examinons comment les RNN et les LSTMs sont structurés et comment ils permettent la création de systèmes de traitement de langage naturel sophistiqués.
Qu’est-ce que les réseaux de neurones à propagation avant ?
Avant de discuter de la façon dont les réseaux de mémoire à court terme (LSTM) et les réseaux de neurones convolutionnels (CNN) fonctionnent, nous devons discuter du format d’un réseau de neurones en général.
Un réseau de neurones est conçu pour examiner les données et apprendre des modèles pertinents, afin que ces modèles puissent être appliqués à d’autres données et que de nouvelles données puissent être classées. Les réseaux de neurones sont divisés en trois sections : une couche d’entrée, une couche cachée (ou plusieurs couches cachées) et une couche de sortie.
La couche d’entrée est ce qui prend les données en entrée du réseau de neurones, tandis que les couches cachées apprennent les modèles dans les données. Les couches cachées dans le jeu de données sont connectées aux couches d’entrée et de sortie par des « poids » et des « biais » qui ne sont que des hypothèses sur la façon dont les points de données sont liés les uns aux autres. Ces poids sont ajustés pendant l’entraînement. Au fur et à mesure que le réseau s’entraîne, les hypothèses du modèle sur les données d’entraînement (les valeurs de sortie) sont comparées aux étiquettes de formation réelles. Au cours de l’entraînement, le réseau devrait (espérons-le) devenir plus précis pour prédire les relations entre les points de données, afin qu’il puisse classer avec précision les nouveaux points de données. Les réseaux de neurones profonds sont des réseaux qui ont plus de couches au milieu / plus de couches cachées. Plus le modèle a de couches cachées et de neurones / nœuds, mieux il peut reconnaître les modèles dans les données.
Les réseaux de neurones à propagation avant réguliers, comme ceux que j’ai décrits ci-dessus, sont souvent appelés « réseaux de neurones denses ». Ces réseaux de neurones denses sont combinés avec différentes architectures de réseaux qui se spécialisent dans l’interprétation de différents types de données.
Qu’est-ce que les RNN (Réseaux de Neurones Récurrents) ?

Les réseaux de neurones récurrents prennent le principe général des réseaux de neurones à propagation avant et les permettent de gérer des données séquentielles en donnant au modèle une mémoire interne. La partie « récurrente » du nom RNN vient du fait que les entrées et les sorties font une boucle. Une fois que la sortie du réseau est produite, la sortie est copiée et retournée au réseau comme entrée. Lorsqu’une décision est prise, non seulement les entrées et les sorties actuelles sont analysées, mais l’entrée précédente est également prise en compte. Pour le dire autrement, si l’entrée initiale pour le réseau est X et la sortie est H, H et X1 (la prochaine entrée dans la séquence de données) sont tous deux alimentés dans le réseau pour le prochain cycle d’apprentissage. De cette façon, le contexte des données (les entrées précédentes) est préservé lorsque le réseau s’entraîne.
Le résultat de cette architecture est que les RNN sont capables de gérer des données séquentielles. Cependant, les RNN souffrent de quelques problèmes. Les RNN souffrent des problèmes de gradient disparaissant et de gradient explosant.
La longueur des séquences que les RNN peuvent interpréter est plutôt limitée, en particulier par rapport aux LSTMs.
Qu’est-ce que les LSTMs (Réseaux de Mémoire à Court Terme) ?
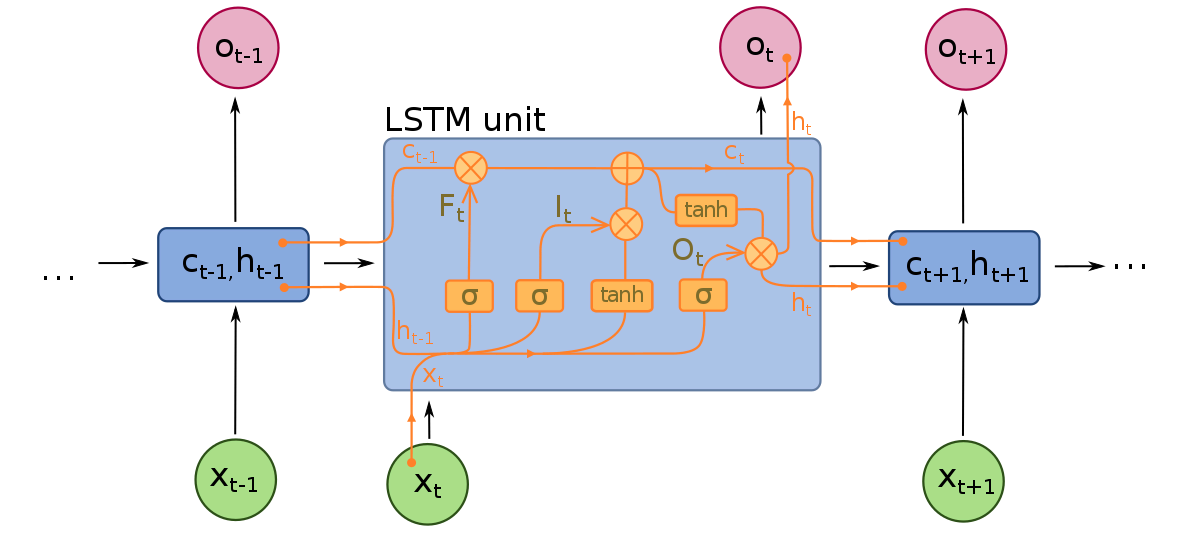
Les réseaux de mémoire à court terme peuvent être considérés comme des extensions des RNN, appliquant une fois de plus le concept de préservation du contexte des entrées. Cependant, les LSTMs ont été modifiés de plusieurs manières importantes qui leur permettent d’interpréter les données passées avec des méthodes supérieures. Les modifications apportées aux LSTMs concernent le problème de gradient disparaissant et permettent aux LSTMs de considérer des séquences d’entrée beaucoup plus longues.

Les modèles LSTMs sont composés de trois composants différents, ou portes. Il y a une porte d’entrée, une porte de sortie et une porte d’oubli. Tout comme les RNN, les LSTMs prennent en compte les entrées de l’étape de temps précédente lors de la modification de la mémoire et des poids d’entrée du modèle. La porte d’entrée prend des décisions sur les valeurs qui sont importantes et qui devraient être laissées passer dans le modèle. Une fonction sigmoïde est utilisée dans la porte d’entrée, qui prend des décisions sur les valeurs à transmettre au réseau récurrent. Zéro supprime la valeur, tandis que 1 la conserve. Une fonction TanH est également utilisée ici, qui décide de l’importance des valeurs d’entrée pour le modèle, allant de -1 à 1.
Une fois que les entrées actuelles et l’état de mémoire sont pris en compte, la porte de sortie décide des valeurs à transmettre à l’étape de temps suivante. Dans la porte de sortie, les valeurs sont analysées et assignées une importance allant de -1 à 1. Cela régule les données avant qu’elles ne soient transmises au calcul de l’étape de temps suivante. Enfin, le travail de la porte d’oubli est de supprimer les informations que le modèle juge inutiles pour prendre une décision sur la nature des valeurs d’entrée. La porte d’oubli utilise une fonction sigmoïde sur les valeurs, produisant des nombres entre 0 (oublier cela) et 1 (conserver cela).
Un réseau de neurones LSTMs est composé à la fois de couches LSTMs spéciales qui peuvent interpréter des données de mots séquentiels et de couches densément connectées comme celles décrites ci-dessus. Une fois que les données passent par les couches LSTMs, elles se poursuivent dans les couches densément connectées.








