AI 101
Mikä on Lineaari Regressio?
Mikä on Lineaari Regressio?
Lineaari regressio on algoritmi, jota käytetään ennustamaan tai visualisoimaan, suhdetta kahden eri ominaisuuden/muuttujan välillä. Lineaari regressio tehtävissä on kaksi tyyppiä muuttujia, jotka tutkitaan: riippuvainen muuttuja ja riippumaton muuttuja. Riippumaton muuttuja on muuttuja, joka on itsenäinen, eikä se ole vaikuttunut toisesta muuttujasta. Kun riippumatonta muuttujaa säätellään, riippuvan muuttujan tasot vaihtelevat. Riippuvainen muuttuja on muuttuja, jota tutkitaan, ja se on se, mihin regressiomalli ratkaisee/yrittää ennustaa. Lineaari regressio tehtävissä jokainen havainto/esiintymä koostuu sekä riippuvan muuttujan arvosta että riippumattoman muuttujan arvosta.
Tämä oli nopea selitys lineaari regressiosta, mutta tarkastellaan lineaari regressiota tarkemmin katsomalla esimerkkiä siitä ja tutkimalla kaavaa, jota se käyttää.
Ymmärtäminen Lineaari Regressio
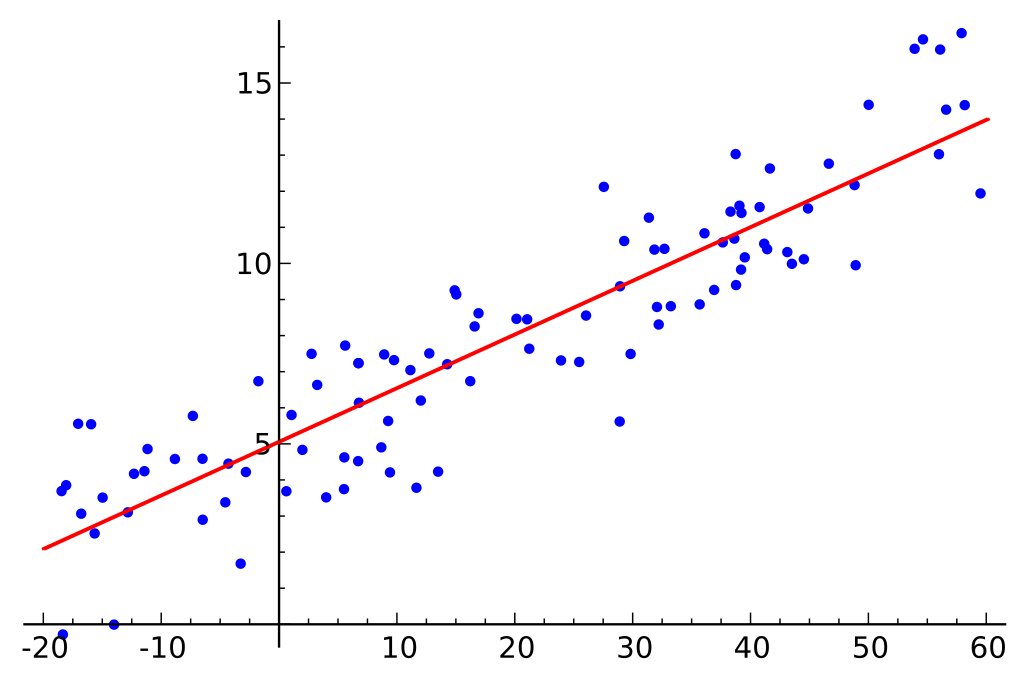
Oletetaan, että meillä on tietokanta, joka kattaa kiintolevyjen koot ja niiden kiintolevyjen hinnat.
Oletetaan, että meillä oleva tietokanta koostuu kahdesta eri ominaisuudesta: muistin määrästä ja kustannuksista. Mitä enemmän muistia ostitietokoneeseen, sitä enemmän ostoksen hinta nousee. Jos juottaisimme yksittäiset datapisteet pisteettä kuvaavaan kaavioon, saattaisimme saada graafin, joka näyttää jotain tältä:

Tarkan muisti-kustannus-suhde saattaa vaihdella valmistajien ja kiintolevyjen mallejen mukaan, mutta yleisesti ottaen, datan trendi on sellainen, joka alkaa alhaalta vasemmasta (missä kiintolevyt ovat sekä halvempia että pienempiä) ja siirtyy yläoikeaan (missä aseet ovat kalliimpia ja suurempia).
Jos meillä olisi muistin määrä X-akselilla ja kustannukset Y-akselilla, suora, joka kuvaa X- ja Y-muuttujien välistä suhdetta, alkaisi alhaalta vasemmasta ja kulkee yläoikeaan.

Regressiomallin tehtävä on määrittää lineaarinen funktio X- ja Y-muuttujien välillä, joka parhaiten kuvaa näiden kahden muuttujan välistä suhdetta. Lineaari regressiossa oletetaan, että Y voidaan laskea jostakin syötemuuttujien yhdistelmästä. Syöte- (X) ja kohdemuuttujien (Y) välinen suhde voidaan kuvata piirtämällä suora pisteiden läpi graafissa. Suora edustaa funktiota, joka parhaiten kuvaa X:n ja Y:n välistä suhdetta (esim. jokaisella kerralla, kun X kasvaa 3:lla, Y kasvaa 2:lla). Tavoitteena on löytää optimaalinen “regressiolinja” tai funktio, joka parhaiten sopii dataan.
Suorat ovat tyypillisesti edustettuina yhtälöllä: Y = m * X + b. X viittaa riippumattomaan muuttujaan, kun taas Y on riippuvainen muuttuja. Samalla m on suoran kulma, määritelty “nousun” ja “juoksun” avulla. Koneoppimisen harjoittajat edustavat kuuluisan kulma-suoran yhtälön hieman eri tavalla, käyttäen tätä yhtälöä:
y(x) = w0 + w1 * x
Yllä olevassa yhtälössä y on kohdemuuttuja, kun taas “w” on mallin parametreja ja syöte on “x”. Niinpä yhtälö luetaan: “Funktio, joka antaa Y:n, riippuen X:stä, on yhtä suuri kuin mallin parametreja kerrottuna ominaisuuksilla”. Mallin parametreja säätellään koulutuksen aikana saadakseen parhaan sopivan regressiolinjan.
Moniulotteinen Lineaari Regressio

Kuva: Cbaf via Wikimedia Commons, Public Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Yllä kuvattu prosessi koskee yksinkertaista lineaarista regressiota eli regressiota, jossa on vain yksi ominaisuus/riippumaton muuttuja. Regressio voidaan kuitenkin tehdä myös useilla ominaisuuksilla. Moniulotteisessa lineaarisessa regressiossa yhtälö laajennetaan muuttujien määrällä, jotka löytyvät tietokannasta. Toisin sanoen, kun yhtälö säännölliselle lineaariselle regressiolle on y(x) = w0 + w1 * x, moniulotteisen lineaarisen regressioyhtälö olisi y(x) = w0 + w1x1 plussa painot ja syötteet eri ominaisuuksille. Jos edustamme kaikkia painoja ja ominaisuuksia w(n)x(n):na, voimme edustaa kaavaa tällä tavalla:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Mallin lineaarisen regressioyhtälön määrittämisen jälkeen koneoppimismalli käyttää eri arvoja painoille ja piirtää eri sovittamisen linjoja. Muistakaa, että tavoitteena on löytää linja, joka parhaiten sopii dataan, jotta voidaan määrittää, kumpi mahdollisista painoyhdistelmistä (ja siten kumpi mahdollinen linja) sopii parhaiten dataan ja selittää muuttujien välistä suhdetta.
Kustannusfunktiota käytetään mittaamaan, kuinka lähellä oletetut Y-arvot ovat todellisista Y-arvoista, kun annetaan tietty painoarvo. Lineaarisessa regressiossa kustannusfunktioksi käytetään keskineliövirhettä, joka laskee vain keskimääräisen (neliöitetyn) virheen ennustetun arvon ja todellisen arvon välillä kaikissa tietokannan datapisteissä. Kustannusfunktiota käytetään laskemaan kustannus, joka sisältää ennustetun kohdearvon ja todellisen kohdearvon välistä eroa. Jos sovittamisen linja on kaukana datapisteistä, kustannus on suurempi, kun taas kustannus pienenee, kun linja lähestyy datapisteitä ja kuvaa muuttujien välistä suhdetta. Mallin painoja säädetään, kunnes löydetään painokonfiguraatio, joka tuottaa vähiten virhettä.








