Τεχνητή νοημοσύνη
Η Επανάσταση MoE: Πώς η Προηγμένη Διαδρομή και η Ειδίκευση Μεταμορφώνουν τα Μεγάλα Γλωσσικά Μοντέλα
Σε λίγα χρόνια, τα μεγάλα γλωσσικά μοντέλα (LLMs) έχουν επεκταθεί από εκατομμύρια σε εκατοντάδες δισεκατομμύρια παραμέτρων, επιδεικνύοντας την αξιοσημείωτη πρόοδο στην ικανότητά μας να σχεδιάζουμε και να κλιμακώνουμε τεράστια συστήματα AI. Αυτά τα τεράστια συστήματα έχουν παραδώσει αξιοθαύμαστες ικανότητες, όπως η γραφή ευφώνου κειμένου, η δημιουργία κώδικα, η αντιμετώπιση σύνθετων προβλημάτων και η συμμετοχή σε ανθρώπινες συνομιλίες. Αλλά αυτή η ταχεία κλιμάκωση έχει ένα σημαντικό κόστος. Η εκπαίδευση και η εκτέλεση τέτοιων τεράστιων μοντέλων καταναλώνουν εξαιρετικές ποσότητες υπολογιστικής δύναμης, ενέργειας και κεφαλαίου. Η στρατηγική “μεγαλύτερο είναι καλύτερο” που曾 καύτηκε την πρόοδο έχει αρχίσει να δείχνει τα όριά της. Σε απάντηση σε αυτές τις αυξανόμενες περιορισμούς, μια αρχιτεκτονική AI γνωστή ως Μίξη Ειδικών (MoE) προωθείται για να προσφέρει ένα έξυπνο και πιο αποτελεσματικό μονοπάτι για την κλιμάκωση των μεγάλων γλωσσικών μοντέλων. Αντί να εξαρτάται από ένα τεράστιο, πάντα ενεργό δίκτυο, η MoE διασπάει το μοντέλο σε μια συλλογή από εξειδικευμένα υποδίκτυα ή “ειδικούς”, κάθε ένας εκ των οποίων έχει εκπαιδευτεί για να χειρίζεται συγκεκριμένα είδη δεδομένων ή εργασιών. Μέσω της έξυπνης διαδρομής, το μοντέλο ενεργοποιεί μόνο τους πιο σχετικούς ειδικούς για κάθε είσοδο, μειώνοντας τον υπολογιστικό φόρτο ενώ διατηρεί ή ακόμη και βελτιώνει την απόδοση. Αυτή η ικανότητα να συνδυάσει την κλιμάκωση με την αποτελεσματικότητα καθιστά τη MoE одну από τις πιο οριστικές αναδυόμενες παραδείγματα στην AI. Αυτό το άρθρο εξετάζει πώς η προηγμένη διαδρομή και η εξειδίκευση οδηγούν αυτή τη μεταμόρφωση και τι σημαίνει για το μέλλον των ευφυών συστημάτων.
Κατανόηση της Κεντρικής Αρχιτεκτονικής
Η ιδέα πίσω από τη Μίξη Ειδικών (MoE) δεν είναι καινούρια. Χρονολογείται από τις μεθόδους συνδυασμού μαθημάτων της δεκαετίας του 1990. Τι έχει αλλάξει είναι η τεχνολογία που την κάνει να λειτουργεί. Μόνο τα τελευταία χρόνια, οι προόδους στην υλική και τις αλγόριθμους διαδρομής έχουν κάνει praktικό να φέρουν αυτή την έννοια στα σύγχρονα μοντέλα Transformer.
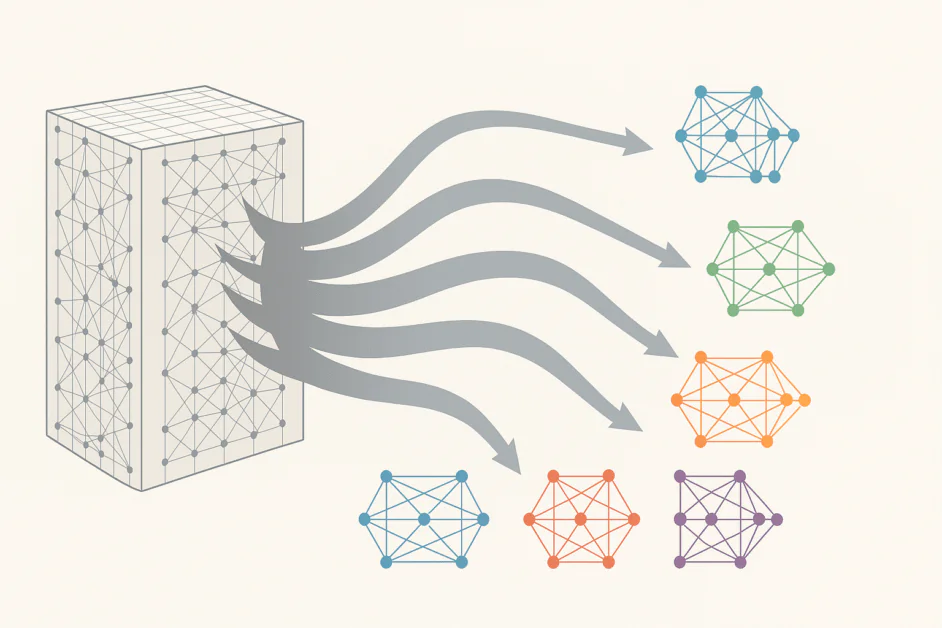
Στην ουσιαστική του, η MoE αναedefinει ένα μεγάλο νευρωνικό δίκτυο ως μια συλλογή από μικρότερα, εξειδικευμένα υποδίκτυα, κάθε ένας εκ των οποίων έχει εκπαιδευτεί για να χειρίζεται συγκεκριμένα είδη δεδομένων ή εργασιών. Αντί να ενεργοποιεί κάθε παράμετρο για κάθε είσοδο, η MoE εισάγει einen μηχανισμό διαδρομής που αποφασίζει ποιους ειδικούς είναι οι πιο σχετικοί για μια δεδομένη είσοδο. Το αποτέλεσμα είναι ένα μοντέλο που χρησιμοποιεί μόνο μια μικρή parte των παραμέτρων του σε κάθε δεδομένη στιγμή, μειώνοντας δραματικά τον υπολογιστικό φόρτο ενώ διατηρεί ή ακόμη και βελτιώνει την απόδοση.
Στην πράξη, αυτή η αρχιτεκτονική μεταβολή επιτρέπει στους ερευνητές να κλιμακώσουν τα μοντέλα στα τρισεκατομμύρια παραμέτρων χωρίς να απαιτείται μια αναλογική αύξηση των υπολογιστικών πόρων. Αντικαθιστά τις παραδοσιακές πυκνές στρώσεις με ένα πιο έξυπνο και δυναμικό σύστημα. Κάθε στρώση MoE περιέχει πολλούς ειδικούς, συνήθως μικρότερα δίκτυα, και einen ρουτήρα ή δίκτυο πυλών που αποφασίζει ποιους ειδικούς πρέπει να επεξεργαστούν κάθε κομμάτι εισόδου. Ο ρουτήρας λειτουργεί σαν ένας διευθυντής έργου, στέλνοντας σχετικές ερωτήσεις σε κάθε ειδικό. Με τον καιρό, το σύστημα μαθαίνει ποιους ειδικούς εκτελούν καλύτερα για διαφορετικά είδη προβλημάτων, βελτιώνοντας την στρατηγική διαδρομής του κατά την εκπαίδευση.
Αυτή η σχεδίαση προσφέρει μια εντυπωσιακή συνδυασμό κλίμακας και αποτελεσματικότητας. Για παράδειγμα, DeepSeek V3, ένα από τα πιο προηγμένα μοντέλα MoE, χρησιμοποιεί ένα आशημένο 685 δισεκατομμύρια παραμέτρους αλλά ενεργοποιεί μόνο μια μικρή parte τους κατά την εκτέλεση. Παρέχει την απόδοση ενός τεράστιου μοντέλου με σημαντικά χαμηλότερες υπολογιστικές και ενεργειακές απαιτήσεις.
Η Εξέλιξη των Μηχανισμών Διαδρομής
Ο ρουτήρας είναι η καρδιά της MoE, καθορίζοντας ποιους ειδικούς χειρίζονται κάθε είσοδο. Τα πρώτα μοντέλα χρησιμοποιούσαν απλές στρατηγικές, επιλέγοντας τους δύο ή τρεις ειδικούς με βάση τις εκπαιδευμένες βαρύτητες. Τα σύγχρονα συστήματα είναι πολύ πιο σύνθετα.
Σήμερα, οι δυναμικοί μηχανισμοί διαδρομής προσαρμόζουν τον αριθμό των ενεργοποιημένων ειδικών με βάση τη σύνθετη είσοδο. Μια απλή ερώτηση μπορεί να χρειάζεται μόνο έναν ειδικό, ενώ δύσκολοι λόγοι μπορεί να ενεργοποιήσουν πολλούς. DeepSeek-V2 υλοποίησε διαδρομή περιορισμένη από συσκευή για να ελέγξει τους κόστους επικοινωνίας σε κατανεμημένα υλικά. DeepSeek-V3 πρωτοπόρησε στρατηγικές χωρίς輔助-απώλεια που επιτρέπουν πλουσιότερη εξειδίκευση ειδικών χωρίς υποβάθμιση της απόδοσης.
Προηγμένα ρουτήρα τώρα λειτουργούν ως έξυπνοι διαχειριστές πόρων, προσαρμόζοντας τις στρατηγικές επιλογής με βάση τις ιδιότητες εισόδου, το βάθος του δικτύου ή την απόδοση σε πραγματικό χρόνο. Ορισμένοι ερευνητές ερευνούν την ενίσχυση του μαθήματος για να βελτιώσουν την απόδοση των εργασιών μακροπρόθεσμης. Τεχνικές όπως μαλακή πύλη επιτρέπουν ομαλότερη επιλογή ειδικών, ενώ η πιθανοτική αποστολή χρησιμοποιεί στατιστικές μεθόδους για να βελτιώσει τις αναθέσεις.
Η Ειδίκευση Οδηγεί στην Απόδοση
Η κεντρική υπόσχεση της MoE είναι ότι η βαθιά εξειδίκευση υπερέχει της ευρείας γενίκευσης. Κάθε ειδικός επικεντρώνεται στο να εξειδικευτεί σε συγκεκριμένα πεδία αντί να είναι μετρίος σε όλα. Κατά την εκπαίδευση, οι μηχανισμοί διαδρομής στέλνουν συνεχώς certains τύπους εισόδου προς συγκεκριμένους ειδικούς, δημιουργώντας einen ισχυρό βρόχο ανατροφοδότησης. Ορισμένοι ειδικοί ξεχωρίζουν στο κώδικα, άλλοι στην ιατρική ορολογία και άλλοι στη δημιουργική γραφή.
Ωστόσο, η επίτευξη αυτού του στόχου παρουσιάζει προκλήσεις. Οι παραδοσιακές προσεγγίσεις ισορροπίας φόρτου μπορούν ironικά να εμποδίσουν την εξειδίκευση με το να αναγκάζουν την ομοιόμορφη χρήση ειδικών. Ωστόσο, το πεδίο προχωράει γρήγορα. Μελέτες αποκαλύπτουν ότι τα μοντέλα MoE με λεπτομερή εξειδίκευση εμφανίζουν σαφή εξειδίκευση, με διαφορετικούς ειδικούς να κυριαρχούν στα αντίστοιχα πεδία. Μελέτες επιβεβαιώνουν ότι οι μηχανισμοί διαδρομής παίζουν einen ενεργό ρόλο στη διαμόρφωση αυτής της αρχιτεκτονικής διαίρεσης εργασίας.
Στρατηγικές που απασχολούν ειδικούς με κλειδιά πεδίου έχουν αποδείξει αξιοσημείωτες βελτιώσεις της απόδοσης. Για παράδειγμα, ερευνητές ανέφεραν μια αύξηση ακρίβειας 3,33% στο AIME2024. Όταν η εξειδίκευση λειτουργεί, τα αποτελέσματα είναι αξιοθαύμαστα. Το DeepSeek V3 υπερέχει του GPT-4o σε hầu hết τις φυσικές γλωσσικές βάσεις και προηγείται σε όλες τις εργασίες κωδικοποίησης και μαθηματικών λογισμών, ένα εντυπωσιακό ορόσημο για ένα ανοιχτό μοντέλο.
Πρακτική Επίδραση στις Ικανότητες του Μοντέλου
Η επανάσταση MoE έχει παραδώσει ουσιαστικές βελτιώσεις στις κεντρικές ικανότητες του μοντέλου. Τα μοντέλα τώρα χειρίζονται μεγαλύτερες περιπτώσεις πιο αποτελεσματικά· και το DeepSeek V3 και GPT-4o μπορούν να επεξεργαστούν 128K tokens σε μια einzahl είσοδο, με την αρχιτεκτονική MoE να βελτιώνει την απόδοση, ιδιαίτερα στα τεχνικά πεδία. Αυτό είναι κρίσιμο για εφαρμογές όπως η ανάλυση ολόκληρων κωδικών ή η επεξεργασία μεγάλων νομικών εγγράφων.
Οι κέρδη της αποτελεσματικότητας είναι ακόμη πιο δραματικά. Ανάλυση υποδεικνύει ότι το DeepSeek-V3 είναι περίπου 29,8 φορές φθηνότερο ανά token σε σύγκριση με το GPT-4o. Αυτή η διαφορά τιμής καθιστά την προηγμένη AI προσβάσιμη σε ένα ευρύτερο φάσμα χρηστών και εφαρμογών. Βελτιώνει σημαντικά την ταχύτητα της δημοκρατίας της AI.
Επιπλέον, η αρχιτεκτονική επιτρέπει μια πιο βιώσιμη ανάπτυξη. Η εκπαίδευση ενός μοντέλου MoE εξακολουθεί να απαιτεί σημαντικούς πόρους, αλλά ο δραματικά χαμηλότερος κόστος inference ανοίγει το δρόμο για ένα πιο αποτελεσματικό και οικονομικά βιώσιμο μοντέλο για τις εταιρείες AI και τους πελάτες τους.
Προκλήσεις και ο Δρόμος προς τα Εμπρός
Παρά τις σημαντικές πλεονεκτήματα, η MoE δεν είναι χωρίς προκλήσεις. Η εκπαίδευση μπορεί να είναι ασταθής, με ειδικούς που μερικές φορές αποτυγχάνουν να εξειδικευτούν όπως προορίζονται. Τα πρώτα μοντέλα έπασχαν από “κατάρρευση διαδρομής“, όπου ένας ειδικός κυριαρχούσε. Η διασφάλιση ότι όλοι οι ειδικοί λαμβάνουν επαρκές δεδομένα εκπαίδευσης ενώ μόνο ένας υποσέτ είναι ενεργός απαιτεί προσεκτική ισορροπία.
Η πιο σημαντική σφραγίδα είναι η επικοινωνιακή υπερβολική. Σε κατανεμημένες ρυθμίσεις GPU, οι κόστος επικοινωνίας μπορούν να καταναλώσουν μέχρι και 77% του χρόνου επεξεργασίας. Πολλοί ειδικοί είναι “υπερσυνεργατικοί”, ενεργοποιούνται συχνά μαζί και αναγκάζουν επαναλαμβανόμενες μεταφορές δεδομένων σε υλικούς επιταχυντές. Αυτό οδηγεί σε θεμελιώδεις επαναξιολογήσεις του σχεδιασμού υλικού AI.
Οι απαιτήσεις μνήμης παρουσιάζουν μια άλλη σημαντική πρόκληση. Ενώ η MoE μειώνει τον υπολογιστικό φόρτο κατά την εκτέλεση, όλοι οι ειδικοί πρέπει να φορτωθούν στη μνήμη, πιέζοντας τις περιφερειακές συσκευές ή τους πόρους-περιορισμένους περιβάλλοντες. Η ερμηνευσιμότητα παραμένει μια άλλη κρίσιμη πρόκληση, поскольку η αναγνώριση ποίου ειδικού συνεισέφερε σε μια δεδομένη έξοδο προσθέτει ένα επιπλέον επίπεδο复雑ότητας στην αρχιτεκτονική. Οι ερευνητές τώρα εξερευνούν μεθόδους για να αναλύσουν τις ενεργοποιήσεις ειδικών και να οπτικοποιήσουν τα μονοπάτια αποφάσεων, με στόχο να κάνουν τα συστήματα MoE πιο διαφανή και πιο εύκολα να ελεγχθούν.
Το Κύριο Σημείο
Η παραδείγματος MoE δεν είναι απλά μια νέα αρχιτεκτονική· είναι μια νέα φιλοσοφία για την κατασκευή μοντέλων AI. Συνδυάζοντας έξυπνη διαδρομή με εξειδίκευση σε επίπεδο πεδίου, η MoE επιτυγχάνει αυτό που κάποτε φαινόταν αντίθετο: μεγαλύτερη κλίμακα με λιγότερη υπολογιστική ισχύ. Ενώ οι προκλήσεις στη σταθερότητα, την επικοινωνία και την ερμηνευσιμότητα παραμένουν, η ισορροπία της αποτελεσματικότητας, της προσαρμογής και της ακρίβειας δείχνει προς το μέλλον των συστημάτων AI που δεν είναι μόνο μεγαλύτερα αλλά και έξυπνα.












