Künstliche Intelligenz
Wie sich Stable Diffusion zu einem Mainstream-Verbraucherprodukt entwickeln könnte

Ironischerweise ist Stable Diffusion, das neue AI-Bildsynthese-Framework, das die Welt im Sturm erobert hat, weder stabil noch wirklich “diffus” – zumindest noch nicht.
Die vollständige Bandbreite der Systemfähigkeiten ist über eine vielfältige Auswahl an ständig mutierenden Angeboten von einer Handvoll Entwickler verteilt, die verzweifelt die neuesten Informationen und Theorien in verschiedenen Diskussionen auf Discord austauschen – und die meisten Installationsverfahren für die von ihnen erstellten oder modifizierten Pakete sind weit entfernt von “plug and play”.
Stattdessen erfordern sie tendenziell eine Kommandozeilen- oder BAT-gesteuerte Installation über GIT, Conda, Python, Miniconda und andere High-End-Entwicklungsframeworks – Software-Pakete, die so selten unter den allgemeinen Verbrauchern sind, dass ihre Installation häufig von Antivirus- und Anti-Malware-Anbietern als Beweis für ein kompromittiertes Host-System gekennzeichnet wird.

Nur eine kleine Auswahl der Stadien, die die Standard-Installation von Stable Diffusion derzeit erfordert. Viele der Distributionen erfordern auch spezifische Versionen von Python, die mit den auf dem Benutzergerät installierten Versionen in Konflikt geraten können – obwohl dies mit Docker-basierten Installationsverfahren und bis zu einem bestimmten Grad durch die Verwendung von Conda-Umgebungen vermieden werden kann.
Nachrichtenfäden in beiden Stable-Diffusion-Communities, SFW und NSFW, sind überfüllt mit Tipps und Tricks im Zusammenhang mit dem Hacken von Python-Skripten und Standard-Installationen, um eine verbesserte Funktionalität zu ermöglichen oder häufige Abhängigkeitsfehler und eine Reihe anderer Probleme zu beheben.
Dies lässt den durchschnittlichen Verbraucher, der an der Erstellung von atemberaubenden Bildern aus Textprompts interessiert ist, mehr oder weniger der wachsenden Anzahl von kommerziellen API-Web-Schnittstellen ausgeliefert, die meisten davon bieten eine minimale Anzahl von kostenlosen Bildgenerierungen an, bevor der Kauf von Token erforderlich wird.
Zusätzlich weigern sich fast alle dieser webbasierten Angebote, NSFW-Inhalte (von denen viele sich auf nicht-pornografische Themen allgemeinen Interesses beziehen können, wie z.B. “Krieg”) auszugeben, die Stable Diffusion von den zensierten Diensten von OpenAIs DALL-E 2 unterscheiden.
‘Photoshop für Stable Diffusion’
Von den atemberaubenden, gewagten oder außerirdischen Bildern, die täglich den Twitter-Hashtag #stablediffusion bevölkern, ist das, was die breite Welt offensichtlich erwartet, ‘Photoshop für Stable Diffusion’ – eine plattformübergreifende installierbare Anwendung, die die beste und leistungsfähigste Funktionalität von Stability.aus Architektur sowie die verschiedenen genialen Innovationen der aufkommenden SD-Entwicklergemeinschaft umfasst, ohne schwimmende CLI-Fenster, unklare und ständig wechselnde Installations- und Update-Routinen oder fehlende Funktionen.
Was wir derzeit haben, ist in den meisten leistungsfähigen Installationen eine verschiedene, elegante Web-Seite, die von einem abgetrennten Kommandozeilenfenster überlagert wird, und deren URL ein localhost-Port ist:

Ähnlich wie CLI-gesteuerte Synthese-Apps wie FaceSwap und die BAT-zentrierte DeepFaceLab zeigt die ‘prepack’-Installation von Stable Diffusion ihre Kommandozeilenwurzeln, wobei die Schnittstelle über einen localhost-Port (siehe oberer Teil des Bildes oben) zugänglich ist, der mit der CLI-basierten Stable-Diffusion-Funktionalität kommuniziert.
Ohne Zweifel kommt eine straffere Anwendung. Schon jetzt gibt es mehrere Patreon-basierte integrierte Anwendungen, die heruntergeladen werden können, wie z.B. GRisk und NMKD (siehe Bild unten) – aber keine, die bisher die gesamte Bandbreite an Funktionen integrieren, die einige der fortgeschritteneren und weniger zugänglichen Implementierungen von Stable Diffusion anbieten können.

Frühe, Patreon-basierte Pakete von Stable Diffusion, leicht ‘app-isiert’. NMKDs ist das erste, das die CLI-Ausgabe direkt in die GUI integriert.
Lassen Sie uns einen Blick darauf werfen, wie eine poliertere und integralere Implementierung dieses erstaunlichen Open-Source-Wunders aussehen könnte – und welche Herausforderungen es möglicherweise zu überwinden hat.
Rechtliche Überlegungen für eine vollständig finanzierte kommerzielle Stable-Diffusion-Anwendung
Der NSFW-Faktor
Der Stable-Diffusion-Quellcode wurde unter einer extrem permissiven Lizenz veröffentlicht, die kommerzielle Neuimplementierungen und abgeleitete Werke, die umfassend auf dem Quellcode aufbauen, nicht verbietet.
Neben den bereits erwähnten und wachsenden Zahl von Patreon-basierten Stable-Diffusion-Builds sowie der umfangreichen Anzahl von Anwendungs-Plugins, die für Figma, Krita, Photoshop, GIMP und Blender (unter anderen) entwickelt werden, gibt es keinen praktischen Grund, warum ein gut finanziertes Software-Entwicklungsunternehmen nicht eine viel fortschrittlichere und leistungsfähigere Stable-Diffusion-Anwendung entwickeln könnte. Aus marktorientierter Sicht gibt es jeden Grund zu der Annahme, dass mehrere solcher Initiativen bereits gut im Gange sind.
Hier stehen solche Bemühungen sofort vor dem Dilemma, ob die Anwendung, ähnlich wie die meisten Web-APIs für Stable Diffusion, den natürlichen NSFW-Filter von Stable Diffusion (ein Fragment des Codes) zulassen oder nicht.
‘Verstecken’ des NSFW-Schalters
Obwohl die offene Lizenz von Stability.ai für Stable Diffusion eine breit interpretierbare Liste von Anwendungen enthält, für die sie nicht verwendet werden darf (arguably einschließlich pornografischen Inhalts und Deepfakes), ist der einzige Weg, wie ein Anbieter solche Verwendung effektiv verbieten könnte, die Kompilierung des NSFW-Filters in einen undurchsichtigen ausführbaren Code anstelle eines Parameters in einer Python-Datei oder die Durchsetzung eines Prüfsummenvergleichs auf die Python-Datei oder DLL, die den NSFW-Direktiven enthält, so dass keine Rendern erfolgen können, wenn Benutzer diese Einstellung ändern.
Dies würde die putative Anwendung “verstümmeln” auf eine ähnliche Weise, wie DALL-E 2 derzeit ist, und ihren kommerziellen Reiz verringern. Außerdem würden unweigerlich dekompilierte “veränderte” Versionen dieser Komponenten (entweder ursprüngliche Python-Laufzeit-Elemente oder kompilierte DLL-Dateien, wie sie nun in der Topaz-Linie von AI-Bildverbesserungstools verwendet werden) in der Torrent-/Hacking-Community auftauchen, um solche Einschränkungen aufzuheben, indem sie die behindernden Elemente ersetzen und die Prüfsummenanforderungen negieren.
Am Ende kann der Anbieter einfach die Warnung von Stability.ai gegen Missbrauch wiederholen, die das erste Laufwerk vieler aktueller Stable-Diffusion-Verteilungen kennzeichnet.
Allerdings haben die kleinen Open-Source-Entwickler, die derzeit solche Haftungsausschlüsse verwenden, wenig zu verlieren im Vergleich zu einem Software-Unternehmen, das erhebliche Zeit und Geld in die Erstellung einer vollständigen und benutzerfreundlichen Stable-Diffusion-Anwendung investiert hat – was eine tiefere Überlegung erfordert.
Deepfake-Haftung
Wie wir kürzlich festgestellt haben, enthält die LAION-Ästhetik-Datenbank, ein Teil der 4,2 Milliarden Bilder, auf denen die laufenden Modelle von Stable Diffusion trainiert wurden, eine große Anzahl von Prominentenbildern, wodurch Benutzer effektiv Deepfakes, einschließlich Deepfake-Prominenten-Pornos, erstellen können.

Von unserem vorherigen Artikel, vier Stadien von Jennifer Connelly über vier Jahrzehnte ihrer Karriere, abgeleitet aus Stable Diffusion.
Dies ist ein separates und umstritteneres Problem als die Erstellung von (in der Regel) legalem “abstraktem” Pornografie, die keine “echten” Menschen (obwohl solche Bilder aus mehreren echten Fotos im Trainingsmaterial abgeleitet werden) darstellt.
Da eine wachsende Anzahl von US-Bundesstaaten und Ländern Gesetze gegen Deepfake-Pornografie entwickelt oder erlassen hat, könnte die Fähigkeit von Stable Diffusion, Prominenten-Pornos zu erstellen, bedeuten, dass eine kommerzielle Anwendung, die nicht vollständig zensiert ist (d.h. die pornografische Materialien erstellen kann), möglicherweise einige Fähigkeiten zur Filterung wahrgenommener Prominentengesichter benötigt.
Eine Methode könnte darin bestehen, eine integrierte “Schwarze Liste” von Begriffen bereitzustellen, die nicht in einem Benutzer-Prompt akzeptiert werden, die sich auf Prominentennamen und fiktive Charaktere beziehen, mit denen sie in Verbindung gebracht werden können. Vermutlich müssten solche Einstellungen in mehr Sprachen als nur Englisch verfügbar sein, da die ursprünglichen Daten andere Sprachen enthalten. Eine andere Herangehensweise könnte darin bestehen, Prominenten-Erkennungssysteme wie die von Clarifai zu integrieren.
Es kann notwendig sein, dass Software-Hersteller solche Methoden implementieren, möglicherweise zunächst deaktiviert, um zu verhindern, dass eine eigenständige Stable-Diffusion-Anwendung Prominentengesichter erstellt, bis neue Gesetze erlassen werden, die eine solche Funktionalität illegal machen.
Noch einmal jedoch könnte eine solche Funktionalität unweigerlich dekomponiert und umgekehrt werden; jedoch könnte der Software-Hersteller in diesem Fall behaupten, dass dies effektiv unerlaubte Vandalismus ist – solange eine solche Umkehrung nicht übermäßig einfach gemacht wird.
Funktionen, die enthalten sein könnten
Die Kernfunktionalität in jeder Verteilung von Stable Diffusion würde erwartet werden, von jeder gut finanzierten kommerziellen Anwendung. Dazu gehören die Fähigkeit, Textprompts zu verwenden, um geeignete Bilder zu generieren (Text-to-Image); die Fähigkeit, Skizzen oder andere Bilder als Richtlinien für neue generierte Bilder zu verwenden (Image-to-Image); die Möglichkeit, anzupassen, wie “kreativ” das System angewiesen wird, zu sein; eine Möglichkeit, die Renderzeit gegen die Qualität abzuwägen; und andere “Grundlagen”, wie optionale automatische Bild-/Prompt-Archivierung und optionale Aufskalierung über RealESRGAN sowie mindestens grundlegende “Gesichtsreparatur” mit GFPGAN oder CodeFormer.
Das ist eine ziemlich “vanille-Installierung”. Lassen Sie uns einen Blick auf einige der fortgeschritteneren Funktionen werfen, die derzeit entwickelt oder erweitert werden und die in eine vollständige “traditionelle” Stable-Diffusion-Anwendung integriert werden könnten.
Stochastische Einfrierung
Selbst wenn Sie einen Seed aus einem vorherigen erfolgreichen Render wiederverwenden, ist es sehr schwierig, Stable Diffusion dazu zu bringen, eine Transformation genau zu wiederholen, wenn jedes Teil des Prompts oder des Quellbildes (oder beides) für einen nachfolgenden Render geändert wird.
Dies ist ein Problem, wenn Sie EbSynth verwenden möchten, um Stable-Diffusions-Transformationen auf echtes Video in einer zeitlich kohärenten Weise aufzuprägen – obwohl die Technik für einfache Kopf-und-Schulter-Aufnahmen sehr effektiv sein kann:

Begrenzte Bewegung kann EbSynth zu einem effektiven Mittel machen, um Stable-Diffusion-Transformationen in realistisches Video umzuwandeln. Quelle: https://streamable.com/u0pgzd
EbSynth funktioniert, indem es eine kleine Auswahl von “veränderten” Schlüsselbildern in ein Video extrapoliert, das in eine Reihe von Bilddateien gerendert und später wieder in ein Video zusammengesetzt werden kann.

In diesem Beispiel von der EbSynth-Website wurden eine Handvoll Frames aus einem Video in künstlerischer Weise bemalt. EbSynth verwendet diese Frames als Stil-Leitfäden, um das gesamte Video entsprechend dem gemalten Stil zu ändern.
Im folgenden Beispiel, bei dem fast keine Bewegung von der (echten) blonden Yoga-Lehrerin auf der linken Seite stattfindet, hat Stable Diffusion dennoch Schwierigkeiten, ein konsistentes Gesicht beizubehalten, da die drei als “Schlüsselbilder” transformierten Bilder nicht vollständig identisch sind, obwohl sie alle den gleichen numerischen Seed teilen.

Hier haben selbst mit dem gleichen Prompt und Seed für alle drei Transformationen und sehr wenigen Änderungen zwischen den Quellbildern die Körpermuskeln unterschiedliche Größe und Form, aber wichtiger ist, dass das Gesicht inkonsistent ist, was die zeitliche Kohärenz in einem potenziellen EbSynth-Render behindert.
Obwohl das SD/EbSynth-Video unten sehr erfinderisch ist, wo die Finger des Benutzers in (jeweils) ein Paar Hosenbeine und eine Ente verwandelt wurden, sind die Inkonsistenzen der Hosen typisch für das Problem, das Stable Diffusion bei der Aufrechterhaltung der Konsistenz über verschiedene Schlüsselbilder hinweg hat, selbst wenn die Quellbilder ähnlich sind und der Seed konsistent ist.

Die Finger eines Mannes werden zu einem gehenden Mann und einer Ente, via Stable Diffusion und EbSynth. Quelle: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
Der Benutzer, der dieses Video erstellte, kommentierte, dass die Ente-Transformation, die möglicherweise die effektivere der beiden ist, nur ein einziges transformiertes Schlüsselbild erforderte, während es notwendig war, 50 Stable-Diffusion-Bilder zu rendern, um die gehenden Hosen zu erstellen, die mehr zeitliche Inkonsistenz aufweisen. Der Benutzer fügte auch hinzu, dass es fünf Versuche erforderte, um Konsistenz für jedes der 50 Schlüsselbilder zu erreichen.
Daher wäre es ein großer Vorteil für eine wirklich umfassende Stable-Diffusion-Anwendung, eine Funktionalität bereitzustellen, die Merkmale über Schlüsselbilder hinweg maximal beibehält.
Eine Möglichkeit besteht darin, die Anwendung so zu gestalten, dass der Benutzer die stochastische Kodierung für die Transformation in jedem Frame “einfrieren” kann, was derzeit nur durch manuelle Änderung des Quellcodes erreicht werden kann. Wie das folgende Beispiel zeigt, hilft dies bei der zeitlichen Kohärenz, auch wenn es das Problem nicht vollständig löst:

Ein Reddit-Benutzer verwandelte Webcam-Footage von sich selbst in verschiedene berühmte Menschen, indem er nicht nur den Seed beibehielt (was jede Implementierung von Stable Diffusion kann), sondern auch sicherstellte, dass der stochastic_encode()-Parameter in jeder Transformation identisch war. Dies wurde durch Änderung des Codes erreicht, könnte aber leicht zu einem benutzerzugänglichen Schalter werden. Offensichtlich löst es jedoch nicht alle zeitlichen Probleme.
Cloud-basierte Textuelle Inversion
Eine bessere Lösung für die Erzielung zeitlich konsistenter Charaktere und Objekte besteht darin, sie in eine Textuelle Inversion zu “backen” – eine 5-KB-Datei, die in wenigen Stunden auf der Grundlage von nur fünf annotierten Bildern trainiert werden kann, die dann durch einen speziellen ‘*’-Prompt abgerufen werden können, um beispielsweise ein anhaltendes Erscheinungsbild neuer Charaktere für die Aufnahme in eine Erzählung zu ermöglichen.

Bilder, die mit geeigneten Tags verknüpft sind, können in separate Entitäten umgewandelt werden, indem sie textuell invertiert werden, und ohne Ambiguität und im richtigen Kontext und Stil durch spezielle Token-Wörter abgerufen werden. Quelle: https://huggingface.co/docs/diffusers/training/text_inversion
Textuelle Inversionen sind Zusatzdateien zum großen, vollständig trainierten Modell, das Stable Diffusion verwendet, und werden effektiv in den Abruf-/Prompt-Prozess “eingeschleust”, sodass sie teilnehmen können, um Szenen abzuleiten, die vom Modell profitieren, und von dessen enormer Datenbank an Wissen über Objekte, Stile, Umgebungen und Interaktionen zu profitieren.
Allerdings erfordert eine Textuelle Inversion nicht viel Zeit, um trainiert zu werden, erfordert aber eine große Menge an VRAM; laut verschiedenen aktuellen Anleitungen irgendwo zwischen 12, 20 und sogar 40 GB.
Da die meisten Casual-Benutzer wahrscheinlich nicht über diese Art von GPU-Leistung verfügen, entstehen bereits Cloud-Dienste, die den Vorgang ausführen, einschließlich einer Hugging-Face-Version. Obwohl es Google-Colab-Implementierungen gibt, die Textuelle Inversionen für Stable Diffusion erstellen können, können die erforderliche VRAM und Zeit die Anforderungen für Free-Tier-Colab-Benutzer herausfordern.
Für eine potenzielle vollständige und gut investierte Stable-Diffusion-Anwendung (installiert) scheint es offensichtlich, diesen anspruchsvollen Auftrag an die Cloud-Server des Unternehmens weiterzuleiten (unter der Annahme, dass eine kostenlose oder kostengünstige Stable-Diffusion-Anwendung mit solchen nicht kostenlosen Funktionen durchsetzt ist, was in vielen möglichen Anwendungen, die in den nächsten 6-9 Monaten aus dieser Technologie hervorgehen, wahrscheinlich ist).
Zusätzlich könnte der ziemlich komplizierte Prozess des Annotierens und Formatierens der eingereichten Bilder und Texte von einer Automatisierung in einer integrierten Umgebung profitieren. Der potenzielle “Suchtfaktor” der Erstellung einzigartiger Elemente, die die weiten Welten von Stable Diffusion erkunden und interagieren können, scheint potenziell zwanghaft, sowohl für allgemeine Enthusiasten als auch für jüngere Benutzer.
Vielseitige Prompt-Gewichtung
Es gibt viele aktuelle Implementierungen, die es dem Benutzer ermöglichen, einem Teil eines langen Textprompts mehr Gewicht zu geben, aber die Instrumentalität variiert ziemlich stark zwischen diesen und ist häufig ungeschickt oder unintuitiv.
Die sehr beliebte Stable-Diffusion-Gabel von AUTOMATIC1111 kann beispielsweise den Wert eines Prompt-Worts senken oder erhöhen, indem es in einzelne oder mehrere Klammern (für Entwertung) oder eckige Klammern für Extra-Betonung eingeschlossen wird.

Eckige Klammern und/oder Klammern können Ihr Frühstück in dieser Version von Stable-Diffusion-Prompt-Gewichten transformieren, aber es ist ein Cholesterin-Albtraum auf jede Weise.
Andere Iterationen von Stable Diffusion verwenden Ausrufezeichen für Betonung, während die vielseitigsten es Benutzern ermöglichen, Gewichte jedem Wort im Prompt über die GUI zuzuweisen.
Das System sollte auch negative Prompt-Gewichte ermöglichen – nicht nur für Horror-Fans, sondern weil es weniger alarmierende und mehr aufschlussreiche Geheimnisse in Stable Diffusions latenter Raum geben kann, als unsere begrenzte Verwendung von Sprache heraufbeschwören kann.
Outpainting
Kurz nach der sensationellen Open-Sourcing von Stable Diffusion versuchte OpenAI, größtenteils erfolglos, einige von DALL-E 2s Donner zurückzugewinnen, indem es “Outpainting” ankündigte, das es dem Benutzer ermöglicht, ein Bild über seine Grenzen hinaus mit semantischer Logik und visueller Kohärenz zu erweitern.
Natürlich wurde dies seitdem in verschiedenen Formen für Stable Diffusion implementiert, sowie in Krita, und sollte sicherlich in einer umfassenden, Photoshop-ähnlichen Version von Stable Diffusion enthalten sein.
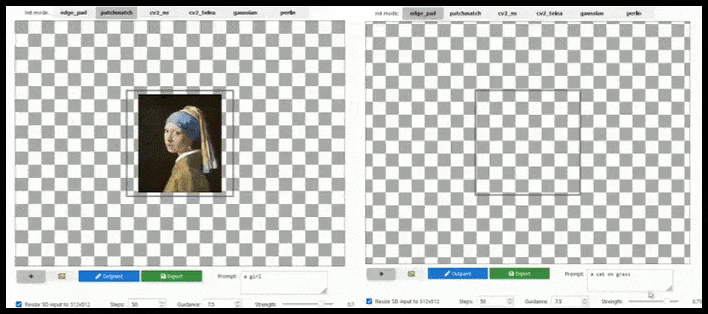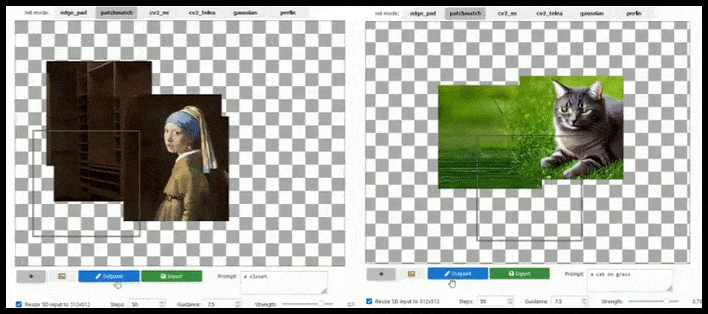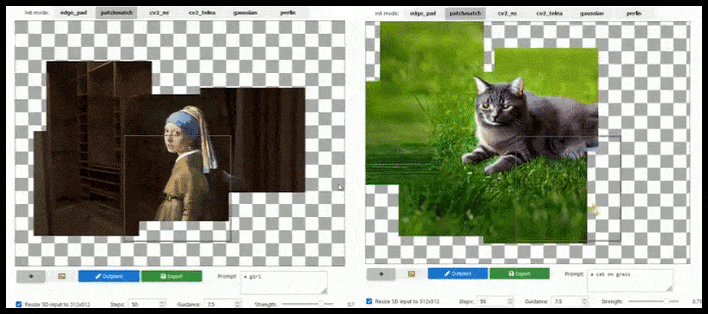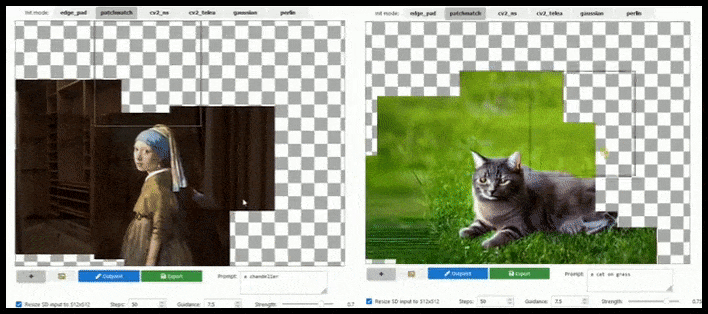
Fliesenbasierte Erweiterung kann ein Standard-512×512-Render fast endlos erweitern, solange die Prompts, das vorhandene Bild und die semantische Logik es zulassen. Quelle: https://github.com/lkwq007/stablediffusion-infinity
Da Stable Diffusion auf 512x512px-Bildern trainiert wurde (und aus einer Reihe anderer Gründe), schneidet es häufig die Köpfe (oder andere wesentliche Körperteile) von menschlichen Subjekten ab, selbst wenn der Prompt eindeutig “Kopfbetonung” usw. angab.

Typische Beispiele für Stable-Diffusions-“Enthauptung”; aber Outpainting könnte George wieder ins Bild bringen.
Jede Outpainting-Implementierung der im animierten Bild oben gezeigten Art (die ausschließlich auf Unix-Bibliotheken basiert, aber auf Windows repliziert werden sollte) sollte auch als ein-Klick-/Prompt-Lösung für dieses Problem ausgestattet sein.
Derzeit erweitern viele Benutzer die Leinwand von “enthaupteten” Darstellungen nach oben, füllen den Kopfbereich ungefähr aus und verwenden img2img, um den fehlerhaften Render zu vervollständigen.
Effektives Maskieren, das Kontext versteht
Maskieren kann in Stable Diffusion ein sehr hit-and-miss-Unternehmen sein, abhängig von der Gabel oder Version in Frage. Häufig ist es, wo es möglich ist, eine kohärente Maske zu zeichnen, der angegebene Bereich mit Inhalten aufgefüllt, die den gesamten Kontext des Bildes nicht berücksichtigen.
In einem Fall maskierte ich die Kornea eines Gesichtsbildes und gab den Prompt ‘blaue Augen’ als Masken-Aufmalung – nur um festzustellen, dass ich durch zwei ausgeschnittene menschliche Augen auf ein fernes Bild eines unheimlichen Wolfs blickte. Ich denke, ich bin lucky, dass es nicht Frank Sinatra war.
Semantische Bearbeitung ist auch möglich, indem das Rauschen identifiziert wird, das das Bild ursprünglich erstellt hat, was es dem Benutzer ermöglicht, spezifische strukturelle Elemente in einem Render anzusprechen, ohne den Rest des Bildes zu stören:

Ändern eines Elements in einem Bild, ohne traditionelles Maskieren und ohne Änderung benachbarter Inhalte, indem das Rauschen identifiziert wird, das das Bild ursprünglich erstellt hat, und die Teile davon angesprochen werden, die zum Zielbereich beigetragen haben. Quelle: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Diese Methode basiert auf dem K-Diffusion-Sampler.
Semantische Filter für physiologische Fehler
Wie wir bereits erwähnt haben, kann Stable Diffusion häufig Gliedmaßen hinzufügen oder subtrahieren, größtenteils aufgrund von Datenproblemen und Mängeln in den Annotationen, die die Bilder begleiten, die es trainiert haben.

Wie dieser unartige Junge, der in der Schulgruppenfoto seine Zunge herausstreckt, sind Stable-Diffusions biologische Greuel nicht immer sofort offensichtlich, und Sie haben möglicherweise Ihr neuestes AI-Meisterwerk auf Instagram geteilt, bevor Sie die extra Hände oder geschmolzenen Gliedmaßen bemerken.
Es ist so schwierig, diese Arten von Fehlern zu beheben, dass es nützlich wäre, wenn eine vollständige Stable-Diffusion-Anwendung ein anatomisches Erkennungssystem enthielte, das semantische Segmentierung verwendet, um zu berechnen, ob das eingehende Bild schwere anatomische Mängel aufweist (wie im Bild oben), und es gegen einen neuen Render austauscht, bevor es dem Benutzer präsentiert wird.

Natürlich möchten Sie möglicherweise die Göttin Kali oder Doctor Octopus oder sogar einen unversehrten Teil eines Gliedmaßen-geschädigten Bildes retten, sodass diese Funktion als optionale Umschaltung dienen sollte.
Wenn Benutzer den Telemetrie-Aspekt tolerieren könnten, könnten solche Fehlschläge anonym in einem kollektiven Bemühen um federatives Lernen übertragen werden, um zukünftige Modelle bei der Verbesserung ihres Verständnisses für anatomische Logik zu unterstützen.
LAION-basierte automatische Gesichtsverbesserung
Wie ich in meinem vorherigen Blick auf drei Dinge, die Stable Diffusion in Zukunft angehen könnte, festgestellt habe, sollte es nicht allein GFPGAN überlassen werden, um in erster Linie gerenderte Gesichter in Stable Diffusion zu “verbessern”.
GFPGANs “Verbesserungen” sind furchtbar generisch, untergraben häufig die Identität des dargestellten Individuums und funktionieren ausschließlich auf einem Gesicht, das keine mehr Verarbeitungszeit oder Aufmerksamkeit erhalten hat als jeder andere Teil des Bildes.
Daher sollte ein professionelles Programm für Stable Diffusion in der Lage sein, ein Gesicht zu erkennen (mit einer Standard- und relativ leichten Bibliothek wie YOLO), die volle Leistung der verfügbaren GPU zu nutzen, um es neu zu rendern, und entweder das verbesserte Gesicht in den ursprünglichen Vollkontext-Render einblenden oder es separat für manuelle Neukomposition speichern. Derzeit ist dies ein ziemlich “hands-on”-Vorgang.
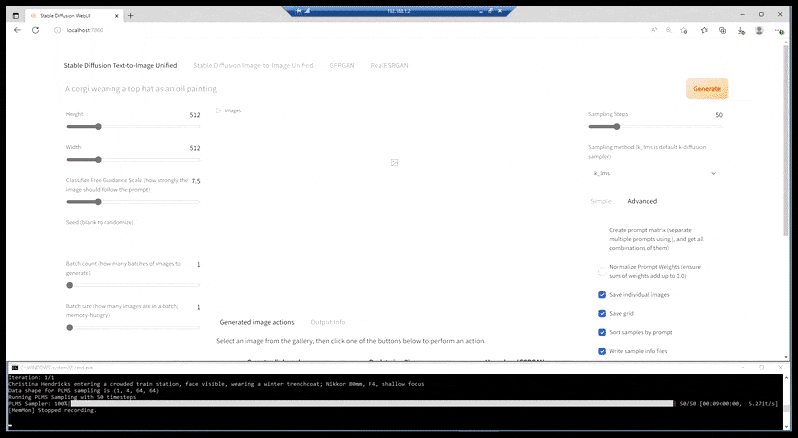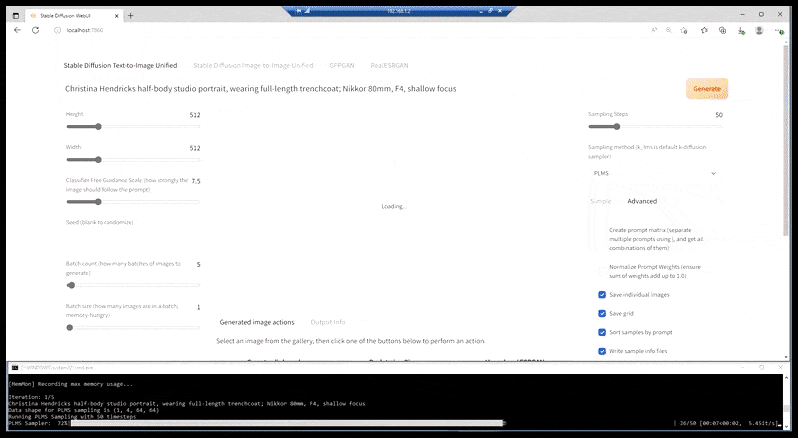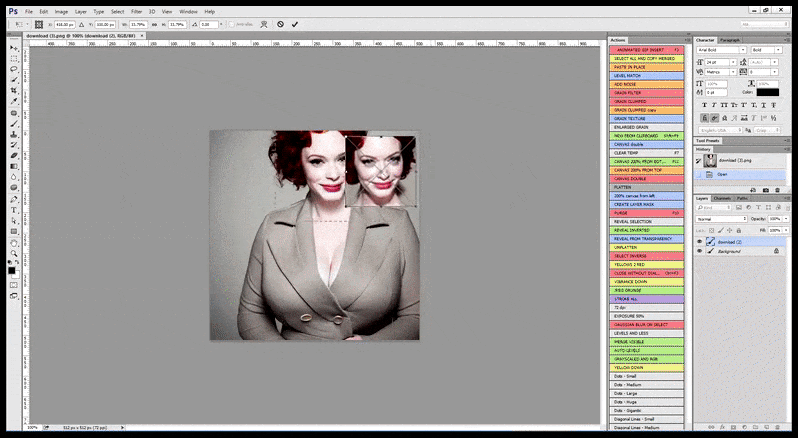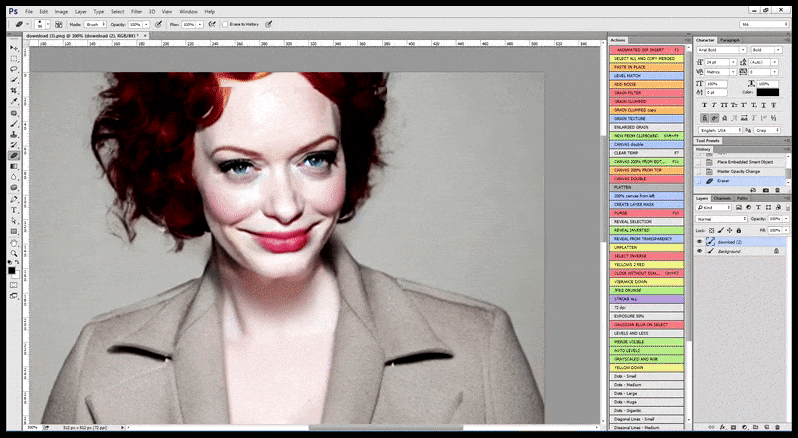
In Fällen, in denen Stable Diffusion auf einer ausreichenden Anzahl von Bildern einer Prominenten trainiert wurde, ist es möglich, die gesamte GPU-Kapazität auf eine nachfolgende Renderung allein des Gesichts des gerenderten Bildes zu konzentrieren, was in der Regel eine bemerkenswerte Verbesserung ist – und im Gegensatz zu GFPGAN auf Informationen aus LAION-trainierten Daten und nicht nur auf die Anpassung der gerenderten Pixel zurückgreift.
In-App-LAION-Suchen
Seit Benutzer begannen, zu erkennen, dass die Suche in LAIONs Datenbank nach Konzepten, Personen und Themen eine Hilfe für eine bessere Nutzung von Stable Diffusion sein kann, wurden mehrere Online-LAION-Explorer erstellt, einschließlich haveibeentrained.com.

Die Suchfunktion bei haveibeentrained.com ermöglicht es Benutzern, die Bilder zu erkunden, die Stable Diffusion antreiben, und zu entdecken, ob Objekte, Personen oder Ideen, die sie möglicherweise aus dem System heraufbeschwören möchten, wahrscheinlich in es trainiert wurden. Solche Systeme sind auch nützlich, um benachbarte Entitäten zu entdecken, wie z.B. die Art und Weise, wie Prominente gruppiert sind, oder die “nächste Idee”, die auf die aktuelle folgt. Quelle: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Obwohl solche webbasierten Datenbanken oft einige der Tags anzeigen, die die Bilder begleiten, bedeutet der Prozess der Verallgemeinerung, der während des Modelltrainings stattfindet, dass es unwahrscheinlich ist, dass ein bestimmtes Bild durch die Verwendung seines Tags als Prompt abgerufen werden kann.
Zusätzlich bedeutet die Entfernung von ‘Stop-Wörtern’ und die Praxis des Stemming und Lemmatisierens in der natürlichen Sprachverarbeitung, dass viele der Phrasen, die in diesen Schnittstellen angezeigt werden, aufgeteilt oder weggelassen wurden, bevor sie in Stable Diffusion trainiert wurden.
Trotzdem kann die Art und Weise, wie ästhetische Gruppierungen in diesen Schnittstellen zusammenhängen, dem Endbenutzer viel über die Logik (oder die “Persönlichkeit”) von Stable Diffusion beibringen und eine Hilfe für eine bessere Bildproduktion sein.
Schlussfolgerung
Es gibt viele andere Funktionen, die ich in einer nativen Desktop-Implementierung von Stable Diffusion sehen möchte, wie z.B. native CLIP-basierte Bildanalyse, die den Standard-Stable-Diffusion-Prozess umkehrt und es dem Benutzer ermöglicht, Phrasen und Wörter abzurufen, die das System natürlicherweise mit dem Quellbild assoziieren würde, oder dem Render.
Zusätzlich wäre eine wahre tile-basierte Skalierung eine willkommene Ergänzung, da ESRGAN fast so stumpf ist wie GFPGAN. Zum Glück machen Pläne, die txt2imghd-Implementierung von GOBIG zu integrieren, dies schnell über die Distributionen hinweg Realität, und es scheint eine offensichtliche Wahl für eine Desktop-Iteration.
Einige andere beliebte Anfragen aus den Discord-Communities interessieren mich weniger, wie z.B. integrierte Prompt-Wörterbücher und anwendbare Listen von Künstlern und Stilen, obwohl ein in-App-Notizbuch oder ein anpassbares Lexikon von Phrasen eine logische Ergänzung wäre.
Ebenso bleibt die aktuelle Einschränkung der menschlichen Animation in Stable Diffusion, obwohl sie durch CogVideo und verschiedene andere Projekte angestoßen wurde, unglaublich nascent und der Gnade von Upstream-Forschung in zeitlichen Prioritäten im Zusammenhang mit authentischer menschlicher Bewegung ausgeliefert.
Für den Moment ist Stable-Diffusion-Video streng psychedelisch, obwohl es in naher Zukunft eine viel hellere Zukunft in Deepfake-Puppen haben kann, via EbSynth und andere relativ neue Text-zu-Video-Initiativen (und es ist erwähnenswert, dass es in Runways letztem Werbevideo keine synthetisierten oder “veränderten” Menschen gibt).
Eine weitere wertvolle Funktionalität wäre transparente Photoshop-Pass-Through, die bereits in Cinema4Ds Textureditor und anderen ähnlichen Implementierungen etabliert ist. Damit kann man Bilder leicht zwischen Anwendungen verschieben und jede Anwendung verwenden, um die Transformationen durchzuführen, die sie am besten beherrscht.
Schließlich und vielleicht am wichtigsten sollte eine vollständige Desktop-Stable-Diffusion-Anwendung in der Lage sein, nicht nur leicht zwischen Checkpoints (d.h. Versionen des zugrunde liegenden Modells, das das System antreibt) zu wechseln, sondern auch benutzerdefinierte Textuelle Inversionen zu aktualisieren, die mit früheren offiziellen Modellveröffentlichungen funktionierten, die aber möglicherweise durch spätere Versionen des Modells (wie von den Entwicklern im offiziellen Discord angegeben) gebrochen werden.
Ironischerweise ist die Organisation, die in der besten Position ist, um ein so leistungsfähiges und integriertes Werkzeug-Set für Stable Diffusion zu erstellen, Adobe, hat sich so stark mit der Content Authenticity Initiative verbündet, dass es ein rückwärtsgewandter PR-Missgriff für das Unternehmen sein könnte – es sei denn, es würde Stable Diffusions generative Kräfte so stark behindern, wie OpenAI es mit DALL-E 2 getan hat, und es stattdessen als natürliche Evolution seiner umfangreichen Bestände an Stockfotografie positionieren.
Erstveröffentlicht am 15. September 2022.












