Gesundheitswesen
Bestimmung der Intoxikation mit Machine-Learning-Analyse der Augen
Forscher aus Deutschland und Chile haben ein neues Machine-Learning-Framework entwickelt, das in der Lage ist, zu bewerten, ob eine Person betrunken ist, basierend auf Nah-Infrarot-Bildern ihrer Augen.
Die Forschung zielt auf die Entwicklung von ‘Fitness for Duty’-Echtzeitsystemen ab, die in der Lage sind, die Bereitschaft eines Einzelnen zu bewerten, kritische Aufgaben wie das Fahren oder das Bedienen von Maschinen auszuführen, und verwendet einen neuartigen und von Grund auf trainierten Objekterkennungsalgorithmus, der in der Lage ist, die Augenkomponenten eines Subjekts aus einem einzelnen Bild zu individuieren und sie gegen eine Datenbank zu bewerten, die betrunkenen und nicht betrunkenen Augenbilder enthält.

You Only Look Once (YOLO) individuiert die Augen des Subjekts, nachdem das Framework die Instanzen getrennt und eine Segmentierung durchgeführt hat, um das Augenbild in seine Bestandteile zu zerlegen. Quelle: https://arxiv.org/pdf/2106.15828.pdf
Zunächst erfasst und individuiert das System ein Bild jedes Auges mit dem You-Only-Look-Once- (YOLO)-Objekterkennungsframework. Danach werden zwei optimierte Netzwerke verwendet, um die Augenbilder in semantische Regionen zu zerlegen – das Criss Cross-Aufmerksamkeitsnetz (CCNet), das 2020 von der Huazhong University of Science and Technology veröffentlicht wurde, und das DenseNet10-Segmentierungsalgorithmus, der auch von einigen der Forscher des neuen Papiers in Chile entwickelt wurde.

Segmentierung, die aus Nah-Infrarot-Augenbildern erhalten wird. Quelle: https://www.researchgate.net/publication/346903035_Towards_an_Efficient_Segmentation_Algorithm_for_Near-Infrared_Eyes_Images#pf6
Die beiden Algorithmen verwenden nur 122.514 und 210.732 Parameter – ein sparsamer Aufwand im Vergleich zu einigen der größeren Feature-Sets in ähnlichen Modellen und im Widerspruch zur allgemeinen Tendenz zu höheren Datenmengen in ML-Frameworks.
Datenbank der Betrunkenen
Um das Machine-Learning-Framework zu informieren, entwickelten die Forscher eine originale Datenbank mit 266 betrunkenen und 765 nüchternen Subjekten.

Beispiele aus der erhaltenen Datenbank betrunkenen und nicht betrunkenen Subjekten.
Die Subjekte mussten vor zwei Iritech-Kameras, der Gemini/Venus-Reihe, stehen, dem Gerät gegenüberstehen und aufgenommen werden, während sie nüchtern waren. Danach konsumierten sie 200 ml Alkohol und wurden in 15-Minuten-Intervallen aufgenommen, während ihre Blutalkoholspiegel stiegen, bis zur letzten Sitzung 60 Minuten nach dem Alkoholkonsum.
Dies ergab 21.309 Bilder, die dann mit der Python-Bibliothek imgaug annotiert wurden.
Vorbereitung der Daten für die reale Welt
Es war kein hochautomatisierter Arbeitsablauf, trotz der verwendeten fortschrittlichen Tools – die manuelle Annotation der Augenbilder wurde von den Forschern als “sehr anspruchsvoll und zeitaufwändig” beschrieben und dauerte mehr als ein Jahr.
Die Daten wurden aggressiv mit einer Reihe von Methoden augmentiert, die darauf abzielten, das System zu degradieren und zu herauszufordern, um mögliche reale Weltbedingungen zu simulieren, einschließlich Schneeflocken, Poisson-Rauschen (um Low-Light-Sensoren zu simulieren), Weichzeichnen, Sprühen und Regeneffekten. Darüber hinaus entfällt die Notwendigkeit idealer Beleuchtungsbedingungen durch die Verwendung von Infrarot-Aufnahmen, die in wirtschaftlichen und praktischen Einrichtungen nicht garantiert werden können.
Diese anstrengende Arbeit zahlte sich letztendlich mit einer Genauigkeit von 98,60 % für die Augenerfassung und -segmentierung aus.

Iris-Segmentierung mit der Least-Means-Squared-Methode.
Testen
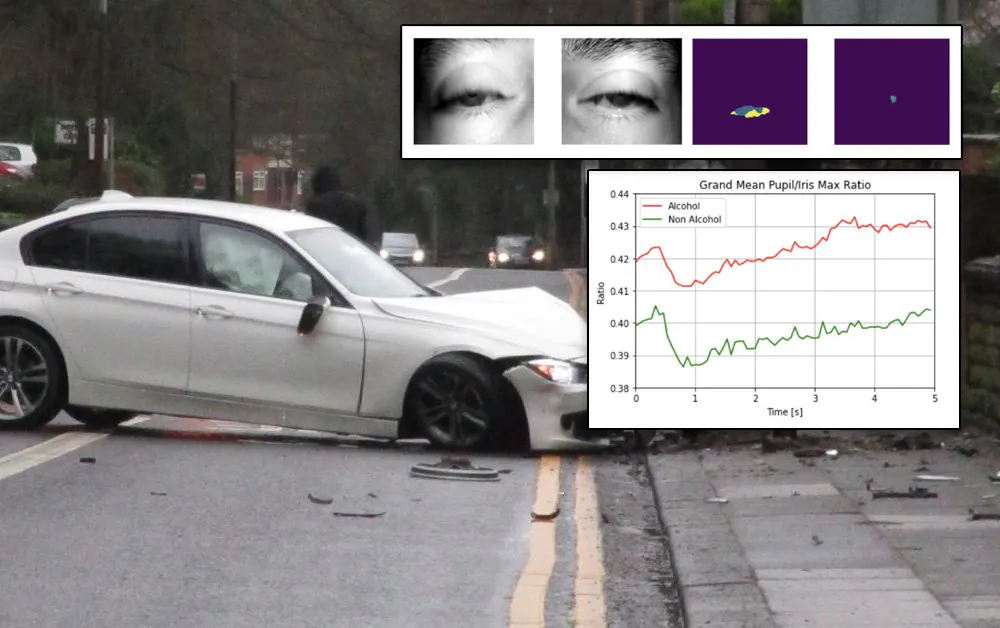
Das Segmentierungsframework wurde mit fünf Plattformen getestet: Osiris, DeepVOG, DenseNet10 (siehe oben), CCNet (siehe oben) und Grand-Mean. In allen Fällen zeigte die Analyse erfolgreiche Ergebnisse für die Korrelation der Pupillenerweiterung mit dem Grad der Betrunkenheit, obwohl ein hybrider Ansatz mit DenseNet und CCNet sich als am effektivsten erwies.
Die Forscher gehen davon aus, dass ihre Arbeit letztendlich in einen Standard-NIR-Iris-Sensor integriert werden kann und bemerken, dass die herkulische Anstrengung, die zur Erstellung der beitragenden betrunkenen Augendatenbank erforderlich war, wahrscheinlich von Vorteil für diesen Bereich der biometrischen Forschung sein wird.
Verbraucher- und Industrie-Intoxikationstests durch Augenbewertung
Die neue Forschung baut auf einigen bemerkenswerten vorherigen Literatur auf, einschließlich eines grundlegenden Papiers von 2015 von Forschern in Brasilien und den USA, das eine systematische und rationalisierte Methode zur Bewertung der Intoxikation aus der Pupillenreaktion vorschlug. Die Forscher dieses Papiers beobachteten, dass Alkohol die Hirneffizienz reduziert und die Nachtsicht um 25 % und die Reaktionszeit um 30 % beeinträchtigt, mit variierenden Schweregraden je nach individueller Toleranz.

Quelle: https://pixellab.group/publication/2015/pinheiro2015/pinheiro2015.pdf
Das primäre Problem für die Verbreitung solcher Technologien ist die Portabilität. Bereits 2003 bot das britische Forschungsunternehmen Hampton Knight ein System für die Intoxikationsevaluation durch Augenanalyse an – es kostete jedoch 10.000 Pfund Sterling zu diesem Zeitpunkt.
Eine vorläufige Studie von 2012 aus Neu-Delhi und den USA erforschte auch die Möglichkeit, systematische AI-Techniken zu verwenden, um einen Intoxikationsscore aus okularen Bildern abzuleiten, jedoch mit weniger Erfolg als die aktuelle Forschung. Diese Studie trug auch einen wertvollen Datensatz (IITD Iris Under Alcohol Influence) zum Bereich bei.
Jedoch öffnen neuere Innovationen in Edge-Computing und optimierten mobilen Machine-Learning-Hardware-Ressourcen das Feld für weit mehr mobile Anwendungen von Voraktivitäts-Checks für Intoxikation, einschließlich In-Car-Sensoren, die möglicherweise Iris-Checks zu den aktuellen Methoden hinzufügen könnten, die für das Driver Alcohol Detection System for Safety (DADSS)-Framework von Interesse sind, das in den USA entwickelt wird – das bisher auf Haut-Alkohol-Sensoren und die Bewertung von Innenraumluft für Alkoholdampf angewiesen war.
Ein Bericht von 2020 schätzte, dass die Einführung solcher Technologien 11.000 Leben pro Jahr in den USA allein retten könnte.












