Künstliche Intelligenz
AudioSep: Trennen Sie alles, was Sie beschreiben
LASS oder Language-Queryed Audio Source Separation ist das neue Paradigma für CASA oder Computational Auditory Scene Analysis, das darauf abzielt, einen Zielklang aus einer gegebenen Audiomischung mithilfe einer Abfrage in natürlicher Sprache zu trennen, die die natürliche und dennoch skalierbare Schnittstelle für digitale Audioaufgaben und -anwendungen bereitstellt . Obwohl die LASS-Frameworks in den letzten Jahren hinsichtlich der Erzielung der gewünschten Leistung bei bestimmten Audioquellen wie Musikinstrumenten erhebliche Fortschritte gemacht haben, sind sie nicht in der Lage, das Zielaudio im offenen Bereich zu trennen.
AudioSepist ein grundlegendes Modell, das darauf abzielt, die aktuellen Einschränkungen von LASS-Frameworks zu beseitigen, indem Ziel-Audio-Trennung mithilfe von Abfragen in natürlicher Sprache ermöglicht wird. Die Entwickler des AudioSep-Frameworks haben das Modell umfassend an einer Vielzahl großer multimodaler Datensätze trainiert und die Leistung des Frameworks bei einer Vielzahl von Audioaufgaben bewertet, darunter Musikinstrumententrennung, Audioereignistrennung und Verbesserung der Sprache unter vielen anderen. Die anfängliche Leistung von AudioSep erfüllt die Benchmarks, da es beeindruckende Zero-Shot-Lernfähigkeiten demonstriert und eine starke Audiotrennungsleistung liefert.
In diesem Artikel werden wir tiefer in die Funktionsweise des AudioSep-Frameworks eintauchen und dabei die Architektur des Modells, die für Training und Bewertung verwendeten Datensätze sowie die wesentlichen Konzepte bewerten, die bei der Funktionsweise des AudioSep-Modells eine Rolle spielen. Beginnen wir also mit einer grundlegenden Einführung in das CASA-Framework.
CASA-, USS-, QSS-, LASS-Frameworks: Die Grundlage für AudioSep
Das CASA- oder Computational Auditory Scene Analysis-Framework ist ein Framework, das von Entwicklern zum Entwerfen maschineller Hörsysteme verwendet wird, die in der Lage sind, komplexe Klangumgebungen auf ähnliche Weise wahrzunehmen, wie Menschen Schall mit ihren Hörsystemen wahrnehmen. Die Schalltrennung, mit besonderem Schwerpunkt auf der Zielschalltrennung, ist ein grundlegender Forschungsbereich im CASA-Rahmen und zielt darauf ab, das „Cocktailparty-Problem” oder das Trennen realer Audioaufnahmen von einzelnen Audioquellenaufnahmen oder -dateien. Die Bedeutung der Klangtrennung lässt sich hauptsächlich auf ihre weit verbreiteten Anwendungen zurückführen, darunter Musikquellentrennung, Audioquellentrennung, Sprachverbesserung, Zielklangidentifizierung und vieles mehr.
Die meisten Arbeiten zur Klangtrennung, die in der Vergangenheit durchgeführt wurden, drehten sich hauptsächlich um die Trennung einer oder mehrerer Audioquellen, beispielsweise Musiktrennung oder Sprachtrennung. Ein neues Modell namens USS oder Universal Sound Separation zielt darauf ab, beliebige Geräusche in realen Audioaufnahmen zu trennen. Es ist jedoch eine herausfordernde und restriktive Aufgabe, jede Tonquelle aus einer Audiomischung zu trennen, vor allem aufgrund der großen Vielfalt unterschiedlicher Tonquellen auf der Welt, was der Hauptgrund dafür ist, dass die USS-Methode für reale Anwendungen nicht geeignet ist in Echtzeit.
Eine praktikable Alternative zur USS-Methode ist das QSS oder die Query-based Sound Separation-Methode, die darauf abzielt, eine einzelne oder Zieltonquelle anhand eines bestimmten Satzes von Abfragen aus der Audiomischung zu trennen. Dank dessen ermöglicht das QSS-Framework Entwicklern und Benutzern, die gewünschten Audioquellen aus der Mischung basierend auf ihren Anforderungen zu extrahieren, was die QSS-Methode zu einer praktischeren Lösung für digitale reale Anwendungen wie die Bearbeitung von Multimedia-Inhalten oder Audiobearbeitung macht.
Darüber hinaus haben Entwickler kürzlich eine Erweiterung des QSS-Frameworks, des LASS-Frameworks oder des Language-Queryed Audio Source Separation Frameworks vorgeschlagen, die darauf abzielt, beliebige Tonquellen aus einer Audiomischung zu trennen, indem sie die Beschreibungen der Ziel-Audioquelle in natürlicher Sprache nutzt . Da das LASS-Framework es Benutzern ermöglicht, die Ziel-Audioquellen mithilfe einer Reihe von Anweisungen in natürlicher Sprache zu extrahieren, könnte es zu einem leistungsstarken Werkzeug mit weit verbreiteten Anwendungen in digitalen Audioanwendungen werden. Im Vergleich zu herkömmlichen Methoden mit Audio- oder Bildabfrage bietet die Verwendung von Anweisungen in natürlicher Sprache zur Audiotrennung einen größeren Vorteil, da sie die Flexibilität erhöht und die Erfassung von Abfrageinformationen viel einfacher und bequemer macht. Darüber hinaus schränkt das LASS-Framework im Vergleich zu Label-Abfrage-basierten Audio-Trennungs-Frameworks, die einen vordefinierten Satz von Anweisungen oder Abfragen verwenden, die Anzahl der Eingabeabfragen nicht ein und bietet die Flexibilität, nahtlos verallgemeinert zu werden, um Domänen zu öffnen.
Ursprünglich basiert das LASS-Framework auf überwachtem Lernen, bei dem das Modell anhand eines Satzes markierter gepaarter Audio-Text-Daten trainiert wird. Das Hauptproblem bei diesem Ansatz ist jedoch die begrenzte Verfügbarkeit annotierter und beschrifteter Audiotextdaten. Um die Zuverlässigkeit des LASS-Frameworks auf Annotationen zu verringern Audiotext-beschriftete DatenDie Modelle werden mithilfe des multimodalen Supervision-Lernansatzes trainiert. Das Hauptziel bei der Verwendung eines multimodalen Überwachungsansatzes besteht darin, multimodale kontrastive Pre-Training-Modelle wie das CLIP- oder Contrastive Language Image Pre-Training-Modell als Abfrage-Encoder für das Framework zu verwenden. Da das CLIP-Framework in der Lage ist, Texteinbettungen mit anderen Modalitäten wie Audio oder Bild abzugleichen, ermöglicht es Entwicklern, die LASS-Modelle mit datenreichen Modalitäten zu trainieren und die Interferenz mit den Textdaten in einer Zero-Shot-Umgebung zu ermöglichen. Die aktuellen LASS-Frameworks nutzen jedoch kleine Datensätze für das Training, und Anwendungen des LASS-Frameworks in Hunderten potenziellen Bereichen müssen noch erforscht werden.
Um die aktuellen Einschränkungen der LASS-Frameworks zu überwinden, haben Entwickler AudioSep eingeführt, ein grundlegendes Modell, das darauf abzielt, mithilfe natürlichsprachlicher Beschreibungen den Ton aus einer Audiomischung zu trennen. Der aktuelle Schwerpunkt von AudioSep liegt auf der Entwicklung eines vorab trainierten Klangtrennungsmodells, das vorhandene große multimodale Datensätze nutzt, um die Verallgemeinerung von LASS-Modellen in Open-Domain-Anwendungen zu ermöglichen. Zusammenfassend lautet das AudioSep-Modell: „Ein grundlegendes Modell für die universelle Klangtrennung im offenen Bereich mithilfe von Abfragen oder Beschreibungen in natürlicher Sprache, die auf großen Audio- und multimodalen Datensätzen trainiert wurden".
AudioSep: Schlüsselkomponenten und Architektur
Die Architektur des AudioSep-Frameworks besteht aus zwei Schlüsselkomponenten: einem Text-Encoder und einem Trennungsmodell.
Der Text-Encoder
Das AudioSep-Framework verwendet einen Textencoder des CLIP- oder Contrastive Language Image Pre Training-Modells oder des CLAP- oder Contrastive Language Audio Pre Training-Modells, um Texteinbettungen innerhalb einer Abfrage in natürlicher Sprache zu extrahieren. Die Eingabetextabfrage besteht aus einer Folge von „N”-Tokens, die dann vom Textencoder verarbeitet werden, um die Texteinbettungen für die angegebene Eingabesprachenabfrage zu extrahieren. Der Text-Encoder verwendet einen Stapel von Transformatorblöcken, um die Eingabetext-Tokens zu kodieren, und die Ausgabedarstellungen werden aggregiert, nachdem sie die Transformatorschichten durchlaufen haben, was zur Entwicklung einer D-dimensionalen Vektordarstellung mit fester Länge führt, wobei D entspricht an die Dimensionen von CLAP oder den CLIP-Modellen angepasst, während der Text-Encoder während des Trainingszeitraums eingefroren ist.
Das CLIP-Modell wird anhand eines großen Datensatzes von gepaarten Bild-Text-Daten mithilfe von kontrastivem Lernen vorab trainiert. Dies ist der Hauptgrund dafür, dass sein Text-Encoder lernt, Textbeschreibungen im semantischen Raum abzubilden, der auch von den visuellen Darstellungen gemeinsam genutzt wird. Der Vorteil, den AudioSep durch die Verwendung des Text-Encoders von CLIP erhält, besteht darin, dass es nun das LASS-Modell aus unbeschrifteten audiovisuellen Daten skalieren oder trainieren kann, indem es alternativ die visuellen Einbettungen verwendet, wodurch das Training von LASS-Modellen ermöglicht wird, ohne dass Anmerkungen oder Beschriftungen erforderlich sind Audio-Text-Daten.
Das CLAP-Modell funktioniert ähnlich wie das CLIP-Modell und nutzt ein kontrastives Lernziel, da es einen Text- und einen Audio-Encoder verwendet, um Audio und Sprache zu verbinden und so Text- und Audiobeschreibungen in einem latenten Audio-Text-Raum zusammenzuführen.
Trennungsmodell
Das AudioSep-Framework verwendet ein ResUNet-Modell im Frequenzbereich, dem eine Mischung aus Audioclips als Trennungsrückgrat für das Framework zugeführt wird. Das Framework funktioniert, indem es zunächst eine STFT oder eine Kurzzeit-Fourier-Transformation auf die Wellenform anwendet, um ein komplexes Spektrogramm, das Größenspektrogramm und die Phase von X zu extrahieren. Das Modell folgt dann derselben Einstellung und erstellt ein Encoder-Decoder-Netzwerk zur Verarbeitung das Magnitudenspektrogramm.
Das ResUNet-Encoder-Decoder-Netzwerk besteht aus 6 Restblöcken, 6 Decoderblöcken und 4 Engpassblöcken. Das Spektrogramm in jedem Encoderblock verwendet vier restliche konventionelle Blöcke, um sich selbst in ein Engpassmerkmal herunterzurechnen, während die Decoderblöcke vier restliche Entfaltungsblöcke nutzen, um die Trennkomponenten durch Upsampling der Merkmale zu erhalten. Anschließend stellt jeder der Encoderblöcke und seine entsprechenden Decoderblöcke eine Sprungverbindung her, die mit der gleichen Upsampling- oder Downsampling-Rate arbeitet. Der Restblock des Frameworks besteht aus 4 Leaky-ReLU-Aktivierungsschichten, 4 Batch-Normalisierungsschichten und 2 CNN-Schichten. Darüber hinaus führt das Framework auch eine zusätzliche Restverknüpfung ein, die die Eingabe und Ausgabe jedes einzelnen Restblocks verbindet. Das ResUNet-Modell verwendet das komplexe Spektrogramm Das getrennte komplexe Spektrogramm kann dann durch Multiplikation der vorhergesagten Größenmaske und des Phasenrests mit der STFT (Kurzzeit-Fourier-Transformation) der Mischung extrahiert werden.

In seinem Framework verwendet AudioSep eine FiLm- oder Feature-wise linear modulierte Ebene, um das Trennungsmodell und den Text-Encoder nach der Bereitstellung der Faltungsblöcke im ResUNet zu überbrücken.
Training und Verlust
Während des Trainings des AudioSep-Modells verwenden Entwickler die Methode der Lautstärkeverstärkung und trainieren das AudioSep-Framework durchgängig, indem sie eine L1-Verlustfunktion zwischen der Grundwahrheit und den vorhergesagten Wellenformen nutzen.
Datensätze und Benchmarks
Wie in den vorherigen Abschnitten erwähnt, ist AudioSep ein grundlegendes Modell, das darauf abzielt, die aktuelle Abhängigkeit von LASS-Modellen von annotierten gepaarten Audio-Text-Datensätzen aufzulösen. Das AudioSep-Modell wird auf einer Vielzahl von Datensätzen trainiert, um es mit multimodalen Lernfunktionen auszustatten. Hier finden Sie eine detaillierte Beschreibung des Datensatzes und der Benchmarks, die von Entwicklern zum Trainieren des AudioSep-Frameworks verwendet werden.
AudioSet
AudioSet ist ein schwach gekennzeichneter großer Audiodatensatz, der über 2 Millionen 10-Sekunden-Audioausschnitte enthält, die direkt von YouTube extrahiert wurden. Jedes Audio-Snippet im AudioSet-Datensatz wird nach dem Fehlen oder Vorhandensein von Klangklassen ohne die spezifischen Timing-Details der Klangereignisse kategorisiert. Der AudioSet-Datensatz umfasst über 500 verschiedene Audioklassen, darunter natürliche Geräusche, menschliche Geräusche, Fahrzeuggeräusche und vieles mehr.
VGGSound
Der VGGSound-Datensatz ist ein umfangreicher Bild-Audio-Datensatz, der genau wie AudioSet direkt von YouTube stammt und über 2,00,000 Videoclips mit einer Länge von jeweils 10 Sekunden enthält. Der VGGSound-Datensatz ist in über 300 Geräuschklassen kategorisiert, darunter menschliche Geräusche, natürliche Geräusche, Vogelgeräusche und mehr. Durch die Verwendung des VGGSound-Datensatzes wird sichergestellt, dass das für die Erzeugung des Zielsounds verantwortliche Objekt auch im entsprechenden visuellen Clip beschreibbar ist.
AudioCaps
AudioCaps ist der größte öffentlich verfügbare Datensatz für Audiountertitel und umfasst über 50,000 10-Sekunden-Audioclips, die aus dem AudioSet-Datensatz extrahiert werden. Die Daten in den AudioCaps sind in drei Kategorien unterteilt: Trainingsdaten, Testdaten und Validierungsdaten, und die Audioclips werden mithilfe der Amazon Mechanical Turk-Plattform von Menschen mit Beschreibungen in natürlicher Sprache versehen. Es ist erwähnenswert, dass jeder Audioclip im Trainingsdatensatz eine einzige Beschriftung hat, wohingegen die Daten in den Test- und Validierungssätzen jeweils fünf grundgetreue Beschriftungen haben.
KlothoV2
Bei ClothoV2 handelt es sich um einen Audio-Untertiteldatensatz, der aus Clips besteht, die von der FreeSound-Plattform stammen. Genau wie bei AudioCaps wird jeder Audioclip mithilfe der Amazon Mechanical Turk-Plattform von Menschen mit Beschreibungen in natürlicher Sprache versehen.
WavCaps
Genau wie AudioSet ist WavCaps ein schwach gekennzeichneter großer Audiodatensatz, der über 400,000 Audioclips mit Untertiteln und einer Gesamtlaufzeit von etwa 7568 Stunden Trainingsdaten umfasst. Die Audioclips im WavCaps-Datensatz stammen aus einer Vielzahl von Audioquellen, darunter BBC Sound Effects, AudioSet, FreeSound, SoundBible und mehr.

Schulungsdetails
Während der Trainingsphase tastet das AudioSep-Modell zufällig zwei Audiosegmente ab, die aus zwei verschiedenen Audioclips aus dem Trainingsdatensatz stammen, und mischt sie dann zusammen, um eine Trainingsmischung zu erstellen, bei der die Länge jedes Audiosegments etwa 5 Sekunden beträgt. Das Modell extrahiert dann das komplexe Spektrogramm aus dem Wellenformsignal mithilfe eines Hann-Fensters der Größe 1024 mit einer Hop-Größe von 320.
Das Modell nutzt dann den Text-Encoder der CLIP/CLAP-Modelle, um die Texteinbettungen zu extrahieren, wobei die Textüberwachung die Standardkonfiguration für AudioSep ist. Für das Trennungsmodell verwendet das AudioSep-Framework eine ResUNet-Schicht, die aus 30 Schichten, 6 Encoderblöcken und 6 Decoderblöcken besteht und der Architektur ähnelt, die im Universal Sound Separation Framework verfolgt wird. Darüber hinaus verfügt jeder Encoderblock über zwei Faltungsschichten mit einer Kernelgröße von 3×3, wobei die Anzahl der Ausgabe-Feature-Maps der Encoderblöcke jeweils 32, 64, 128, 256, 512 und 1024 beträgt. Die Decoderblöcke weisen eine gemeinsame Symmetrie mit den Encoderblöcken auf, und die Entwickler wenden den Adam-Optimierer an, um das AudioSep-Modell mit einer Stapelgröße von 96 zu trainieren.
Resultate der Auswertung
Auf gesehene Datensätze
Die folgende Abbildung vergleicht die Leistung des AudioSep-Frameworks bei gesehenen Datensätzen während der Trainingsphase, einschließlich der Trainingsdatensätze. Die folgende Abbildung stellt die Benchmark-Bewertungsergebnisse des AudioSep-Frameworks im Vergleich zu Basissystemen einschließlich Speech dar Erweiterungsmodelle, LASS und CLIP. Das AudioSep-Modell mit CLIP-Textencoder wird als AudioSep-CLIP dargestellt, während das AudioSep-Modell mit CLAP-Textencoder als AudioSep-CLAP dargestellt wird.

Wie in der Abbildung zu sehen ist, schneidet das AudioSep-Framework gut ab, wenn Audiountertitel oder Textbeschriftungen als Eingabeabfragen verwendet werden, und die Ergebnisse zeigen die überlegene Leistung des AudioSep-Frameworks im Vergleich zu früheren LASS-Benchmark-Modellen und audioabgefragten Tontrennungsmodellen.
Über unsichtbare Datensätze
Um die Leistung von AudioSep in einer Zero-Shot-Einstellung zu bewerten, haben die Entwickler die Leistung an bisher unbekannten Datensätzen weiter evaluiert. Das AudioSep-Framework liefert eine beeindruckende Trennleistung in einer Zero-Shot-Einstellung. Die Ergebnisse sind in der folgenden Abbildung dargestellt.

Darüber hinaus zeigt das Bild unten die Ergebnisse der Bewertung des AudioSep-Modells im Vergleich zur Sprachverbesserung von Voicebank-Demand.

Die Evaluierung des AudioSep-Frameworks zeigt eine starke und gewünschte Leistung bei unsichtbaren Datensätzen in einer Zero-Shot-Einstellung und macht somit Platz für die Durchführung solider Betriebsaufgaben bei neuen Datenverteilungen.
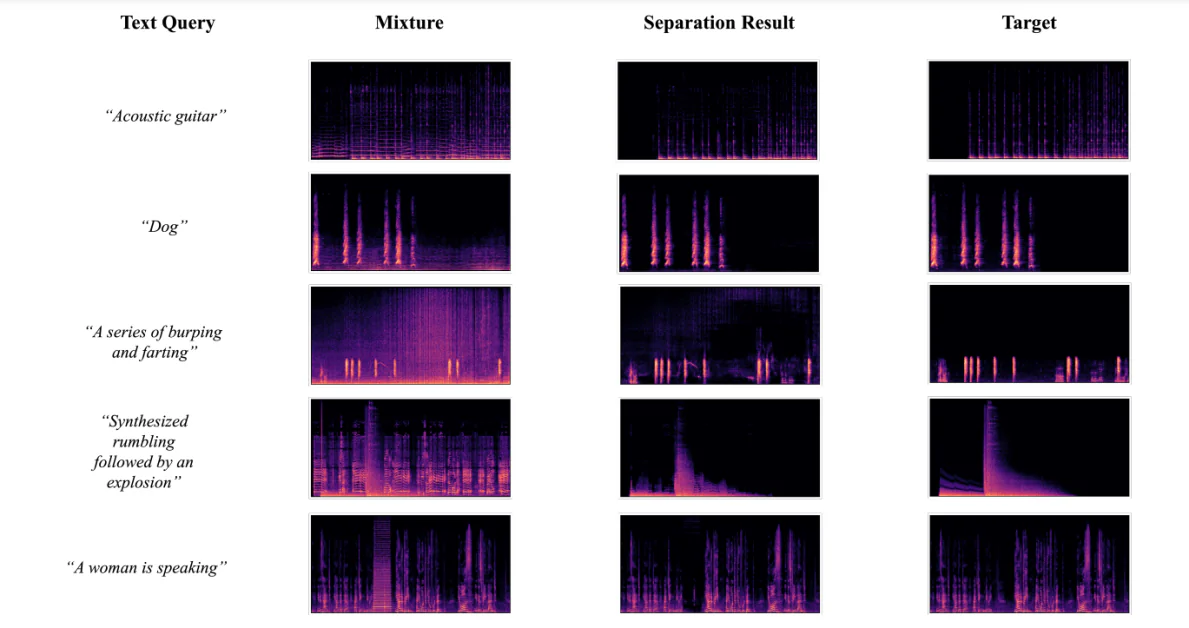
Visualisierung der Trennergebnisse
Die folgende Abbildung zeigt die Ergebnisse, die erzielt wurden, als die Entwickler das AudioSep-CLAP-Framework verwendeten, um Visualisierungen von Spektrogrammen für Ground-Truth-Ziel-Audioquellen sowie Audiomischungen und getrennte Audioquellen mithilfe von Textabfragen verschiedener Audios oder Sounds durchzuführen. Anhand der Ergebnisse konnten Entwickler beobachten, dass das getrennte Quellmuster des Spektrogramms nahe an der Quelle der Grundwahrheit liegt, was die objektiven Ergebnisse der Experimente weiter untermauert.
Vergleich von Textabfragen
Die Entwickler bewerten die Leistung von AudioSep-CLAP und AudioSep-CLIP auf AudioCaps Mini und nutzen die AudioSet-Ereignisbezeichnungen, die AudioCaps-Beschriftungen und neu annotierte Beschreibungen in natürlicher Sprache, um die Auswirkungen verschiedener Abfragen und Folgendes zu untersuchen Die Abbildung zeigt ein Beispiel des AudioCaps Mini in Aktion.

Fazit
AudioSep ist ein grundlegendes Modell, das mit dem Ziel entwickelt wurde, ein universelles Open-Domain-Framework für die Klangtrennung zu sein, das Beschreibungen in natürlicher Sprache für die Audiotrennung verwendet. Wie bei der Evaluierung festgestellt wurde, ist das AudioSep-Framework in der Lage, nahtlos Zero-Shot- und unüberwachtes Lernen durchzuführen, indem es Audiountertitel oder Textbeschriftungen als Abfragen verwendet. Die Ergebnisse und die Bewertungsleistung von AudioSep deuten auf eine starke Leistung hin, die aktuelle Klangtrennungs-Frameworks wie LASS übertrifft und möglicherweise in der Lage ist, die aktuellen Einschränkungen gängiger Klangtrennungs-Frameworks zu überwinden.












