
Medicinal
Algoritme kan adressere raceforstyrrelser i sundhedsvæsenet, hvis den er korrekt trænet
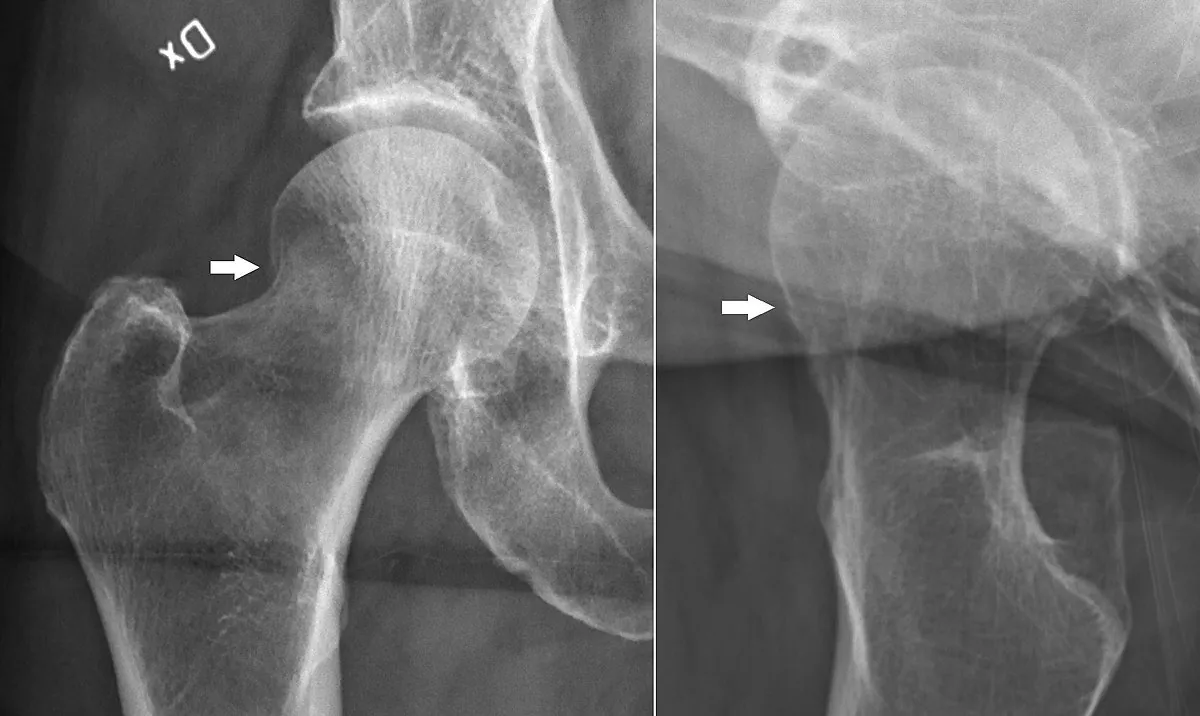
Et team af forskere fra Stanford University, Harvard University og University of Chicago trænede algoritmer at diagnosticere gigt ved røntgenbilleder af knæ. Det viser sig, at når patienternes rapporter bruges som træningsdata for algoritmen, var algoritmen mere nøjagtig end radiologer, når de analyserede journalerne for sorte patienter.
Problem med Algorthimic Bias
Brugen af maskinlæringsalgoritmer på det medicinske område kan potentielt forbedre resultaterne for patienter, der lider af alle slags sygdomme, men der er også veldokumenterede problemer med at bruge AI-algoritmer til at diagnosticere patienter. Undersøgelser af virkningerne af implementerede AI-modeller har fundet en række bemærkelsesværdige hændelser, der involverer algoritmisk bias. Disse inkludere algoritmer som giver minoriteter færre henvisninger til kardiologiske enheder end hvide patienter, selvom alle rapporterede symptomer var de samme.
En af forfatterne til Studiet, professor Ziad Obermeyer ved University of California Berkeley's School of Public Health, besluttede at anvende AI til at undersøge forskelle mellem røntgendiagnoser fra radiologer og mængden af smerte, som patienterne rapporterede. Selvom sorte patienter og lavindkomstpatienter rapporterede højere niveauer af smerte, blev deres røntgenfortolkninger scoret det samme som den generelle befolkning. Dataene om de rapporterede smerteniveauer kom fra NIH, og forskerne ønskede at undersøge, om menneskelige læger manglede noget i deres analyse af dataene.
Som rapporteret af Wired, for at identificere de potentielle årsager til disse forskelle, konstruerede Obermeyer og andre forskere en computervisionsmodel trænet på data fra NIH. Algoritmerne blev designet til at analysere røntgenbilleder og forudsige en patients smerteniveau baseret på billederne. Softwaren formåede at finde mønstre i billederne, der viste sig at være meget korrelerede med en patients smerteniveau.
Når algoritmen præsenteres med et uset billede, returnerer modellen forudsigelser for en patients niveau af rapporterede smerte. De forudsigelser, som modellen returnerede, passede tættere sammen med de faktiske rapporterede smerteniveauer hos patienterne end de scores, der blev tildelt af radiologerne. Dette gjaldt især for sorte patienter. Obermeyer forklarede via Wired, at computersynsalgoritmen var i stand til at detektere fænomener, der var mere almindeligt forbundet med smerter hos sorte patienter.
Korrekt træningssystemer
Efter sigende blev kriterierne, der blev brugt til at evaluere røntgenstråler, oprindeligt udviklet baseret på resultaterne af en lille undersøgelse udført i det nordlige England i 1957. Den oprindelige befolkning, der blev brugt til at udvikle slidgigtvurderingskriterier, var meget anderledes end den meget forskelligartede befolkning i det moderne United stater, så det er ikke overraskende, at der er begået fejl, når man diagnosticerer disse forskellige mennesker.
Den nye undersøgelse viser, at når AI-algoritmer er korrekt trænet, kan de reducere bias. Træningen var baseret på feedback fra patienterne selv i stedet for ekspertudtalelser. Obermeyer og kolleger tidligere påvist at en almindeligt brugt AI-algoritme gav fortrinsret til hvide patienter frem for sorte patienter, men Obermeyer viste også, at træning af et maskinlæringssystem på de rigtige data kan hjælpe med at forhindre bias.
En bemærkelsesværdig advarsel til undersøgelsen er en, der er kendt for mange maskinlæringsforskere. AI-modellen udviklet af forskerholdet er en sort boks, og holdet af forskere er selv ikke sikre på, hvilken slags funktioner algoritmen registrerer i røntgenstrålerne, hvilket betyder, at de ikke kan fortælle lægerne, hvilke funktioner de mangler .
Andre radiologer og forskere sigter efter at grave i den sorte boks og afdække mønstrene i dem, forhåbentlig at hjælpe lægerne med at forstå, hvad de går glip af. Radiolog og professor ved Emory University, Judy Gichoya, er ved at indsamle et mere ekspansivt og varieret sæt røntgenbilleder for at træne AI-modellen. Gichoya vil få radiologer til at lave detaljerede noter om disse røntgenstråler. Disse noter vil blive sammenlignet med outputtet af modellen for at se, om de mønstre, der er detekteret af algoritmen, kan afsløres.











