
AI 101
Hvad er overfitting?
Hvad er overfitting?
Når du træner et neuralt netværk, skal du undgå overfitting. overfitting er et problem inden for maskinlæring og statistik, hvor en model lærer mønstrene i et træningsdatasæt for godt, og forklarer træningsdatasættet perfekt, men undlader at generalisere dets forudsigelsesevne til andre datasæt.
For at sige det på en anden måde, vil den i tilfælde af en overfitting-model ofte vise ekstrem høj nøjagtighed på træningsdatasættet, men lav nøjagtighed på data indsamlet og kørt gennem modellen i fremtiden. Det er en hurtig definition af overfitting, men lad os gennemgå begrebet overfitting mere detaljeret. Lad os tage et kig på, hvordan overfitting opstår, og hvordan det kan undgås.
Forståelse af "Fit" og Underfitting
Det er nyttigt at tage et kig på begrebet undertilpasning og "passer” generelt når man diskuterer overfitting. Når vi træner en model, forsøger vi at udvikle en ramme, der er i stand til at forudsige arten eller klassen af elementer i et datasæt, baseret på de funktioner, der beskriver disse elementer. En model bør være i stand til at forklare et mønster i et datasæt og forudsige klasserne af fremtidige datapunkter baseret på dette mønster. Jo bedre modellen forklarer forholdet mellem træningssættets funktioner, jo mere "fit" er vores model.
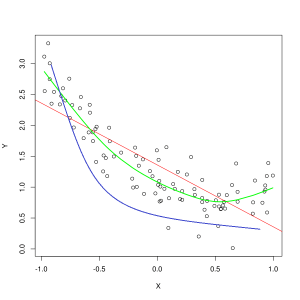
Blå linje repræsenterer forudsigelser af en model, der ikke passer, mens den grønne linje repræsenterer en model, der passer bedre. Foto: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
En model, der dårligt forklarer forholdet mellem funktionerne i træningsdataene og dermed ikke klarer at klassificere fremtidige dataeksempler, er undertilpasning træningsdataene. Hvis du skulle tegne det forudsagte forhold mellem en undertilpasset model i forhold til det faktiske skæringspunkt mellem funktionerne og etiketterne, ville forudsigelserne afvige fra mærket. Hvis vi havde en graf med de faktiske værdier af et træningssæt mærket, ville en stærkt undertilpasset model drastisk gå glip af de fleste af datapunkterne. En model med en bedre tilpasning kan skære en sti gennem midten af datapunkterne, hvor individuelle datapunkter kun er lidt væk fra de forudsagte værdier.
Undertilpasning kan ofte forekomme, når der ikke er tilstrækkelige data til at skabe en nøjagtig model, eller når man forsøger at designe en lineær model med ikke-lineære data. Flere træningsdata eller flere funktioner vil ofte hjælpe med at reducere undertilpasning.
Så hvorfor skulle vi ikke bare lave en model, der forklarer hvert punkt i træningsdataene perfekt? Sikkert perfekt nøjagtighed er ønskelig? At skabe en model, der har lært mønstrene i træningsdataene for godt, er det, der forårsager overfitting. Træningsdatasættet og andre fremtidige datasæt, du kører gennem modellen, vil ikke være helt det samme. De vil sandsynligvis være meget ens i mange henseender, men de vil også adskille sig på vigtige måder. Derfor betyder det at designe en model, der forklarer træningsdatasættet perfekt, at du ender med en teori om forholdet mellem funktioner, der ikke generaliserer godt til andre datasæt.
Forståelse af overfitting
Overfitting opstår, når en model lærer detaljerne i træningsdatasættet for godt, hvilket får modellen til at lide, når forudsigelser foretages på eksterne data. Dette kan forekomme, når modellen ikke kun lærer datasættets funktioner, den lærer også tilfældige fluktuationer eller støj i datasættet og lægger vægt på disse tilfældige/uvigtige hændelser.
Overtilpasning er mere sandsynligt, når der anvendes ikke-lineære modeller, da de er mere fleksible, når de lærer datafunktioner. Ikke-parametriske maskinlæringsalgoritmer har ofte forskellige parametre og teknikker, der kan anvendes til at begrænse modellens følsomhed over for data og derved reducere overfitting. Som et eksempel, beslutningstræmodeller er meget følsomme over for overfitting, men en teknik kaldet beskæring kan bruges til tilfældigt at fjerne nogle af de detaljer, som modellen har lært.
Hvis du skulle tegne modellens forudsigelser på X- og Y-akser, ville du have en forudsigelseslinje, der zigzagger frem og tilbage, hvilket afspejler det faktum, at modellen har prøvet for meget på at passe alle punkter i datasættet ind i dens forklaring.
Kontrol af overfitting
Når vi træner en model, ønsker vi ideelt set, at modellen ikke laver fejl. Når modellens præstation konvergerer mod at lave korrekte forudsigelser på alle datapunkterne i træningsdatasættet, bliver pasformen bedre. En model med en god pasform er i stand til at forklare næsten hele træningsdatasættet uden overtilpasning.
Når en model træner, forbedres dens ydeevne over tid. Modellens fejlrate vil falde, efterhånden som træningstiden går, men den falder kun til et vist punkt. Det punkt, hvor modellens ydeevne på testsættet begynder at stige igen, er typisk det punkt, hvor overfitting forekommer. For at få den bedste pasform til en model, ønsker vi at stoppe med at træne modellen på det tidspunkt, hvor der er det laveste tab på træningssættet, før fejlen begynder at stige igen. Det optimale stoppunkt kan konstateres ved at tegne modellens præstationer i hele træningstiden og stoppe træningen, når tabet er lavest. En risiko ved denne metode til at kontrollere for overfitting er dog, at specificering af endpoint for træningen baseret på testpræstation betyder, at testdataene bliver noget inkluderet i træningsproceduren, og de mister sin status som rent "uberørte" data.
Der er et par forskellige måder, man kan bekæmpe overfitting på. En metode til at reducere overfitting er at bruge en resampling-taktik, som fungerer ved at estimere modellens nøjagtighed. Du kan også bruge en validering datasæt ud over testsættet og plot træningsnøjagtigheden mod valideringssættet i stedet for testdatasættet. Dette holder dit testdatasæt uset. En populær resamplingmetode er K-folds krydsvalidering. Denne teknik gør dig i stand til at opdele dine data i delmængder, som modellen er trænet på, og derefter analyseres modellens ydeevne på delmængderne for at estimere, hvordan modellen vil præstere på eksterne data.
Brug af krydsvalidering er en af de bedste måder at estimere en models nøjagtighed på usete data, og når det kombineres med et valideringsdatasæt, kan overtilpasning ofte holdes på et minimum.










