AI 101
Hvad er RNNs og LSTMs i Deep Learning?
Mange af de mest imponerende fremskridt i naturlig sprogbehandling og AI-chatbots er drevet af Recurrent Neural Networks (RNNs) og Long Short-Term Memory (LSTM) netværk. RNNs og LSTMs er speciale neurale netværksarkitekturer, der kan behandle sekventielle data, data hvor kronologisk orden er vigtig. LSTMs er essentielt forbedrede versioner af RNNs, der kan fortolke længere sekvenser af data. Lad os se på, hvordan RNNs og LSTMs er struktureret og hvordan de muliggør oprettelsen af avancerede naturlige sprogbehandlingsystemer.
Hvad er Feed-Forward Neural Networks?
Så før vi taler om, hvordan Long Short-Term Memory (LSTM) og Convolutional Neural Networks (CNN) virker, skal vi diskutere formatet for et neuralt netværk i almindelighed.
Et neuralt netværk er beregnet til at undersøge data og lære relevante mønstre, så disse mønstre kan anvendes på andre data, og nye data kan klassificeres. Neurale netværk er inddelt i tre sektioner: en inputlag, en skjult lag (eller flere skjulte lag) og en outputlag.
Inputlaget er det, der tager imod data i neuralt netværk, mens de skjulte lag er det, der lærer mønstre i data. De skjulte lag i datasættet er forbundet til input- og outputlagene med “vægte” og “forudindstillinger”, som blot er antagelser om, hvordan datapunkterne er relateret til hinanden. Disse vægte justeres under træning. Da netværket træner, sammenlignes modellens gæt om træningsdata (outputværdierne) med de faktiske træningsmærker. Under træningsforløbet skal netværket (håbefuldt) blive mere præcist i at forudsige relationer mellem datapunkter, så det kan klassificere nye datapunkter nøjagtigt. Dybe neurale netværk er netværk, der har flere lag i midten/flere skjulte lag. Jo flere skjulte lag og neuroner/noder modellen har, jo bedre kan den genkende mønstre i data.
Almindelige, feed-forward neurale netværk, som dem jeg har beskrevet ovenfor, kaldes ofte “tætte neurale netværk”. Disse tætte neurale netværk kombineres med forskellige netværksarkitekturer, der specialiserer sig i at fortolke forskellige typer data.
Hvad er RNNs (Recurrent Neural Networks)?

Recurrent Neural Networks tager den generelle princip for feed-forward neurale netværk og muliggør, at de kan behandle sekventielle data ved at give modellen en intern hukommelse. Den “Recurrent” del af RNN-navnet kommer fra det faktum, at input og output løber i ring. Når outputtet af netværket er produceret, kopieres outputtet og returneres til netværket som input. Når der træffes en beslutning, analyseres ikke kun det aktuelle input og output, men også det forrige input. For at sige det på en anden måde, hvis det første input for netværket er X og outputtet er H, føres både H og X1 (det næste input i datasekvensen) ind i netværket til næste runde af læring.
Resultatet af denne arkitektur er, at RNNs kan behandle sekventielle data. Men RNNs lider af et par problemer. RNNs lider af forsvindende gradient og eksploderende gradientproblemer.
Længden af sekvenser, som en RNN kan fortolke, er ret begrænsede, især i sammenligning med LSTMs.
Hvad er LSTMs (Long Short-Term Memory Networks)?
Long Short-Term Memory netværk kan betragtes som udvidelser af RNNs, igen ved at anvende konceptet med at bevare konteksten af inputs. Men LSTMs er blevet modificeret på flere vigtige måder, der tillader dem at fortolke tidligere data med overlegne metoder. Ændringerne, der er gjort til LSTMs, omhandler forsvindende gradientproblemet og muliggør, at LSTMs kan overveje langt længere inputsekvenser.

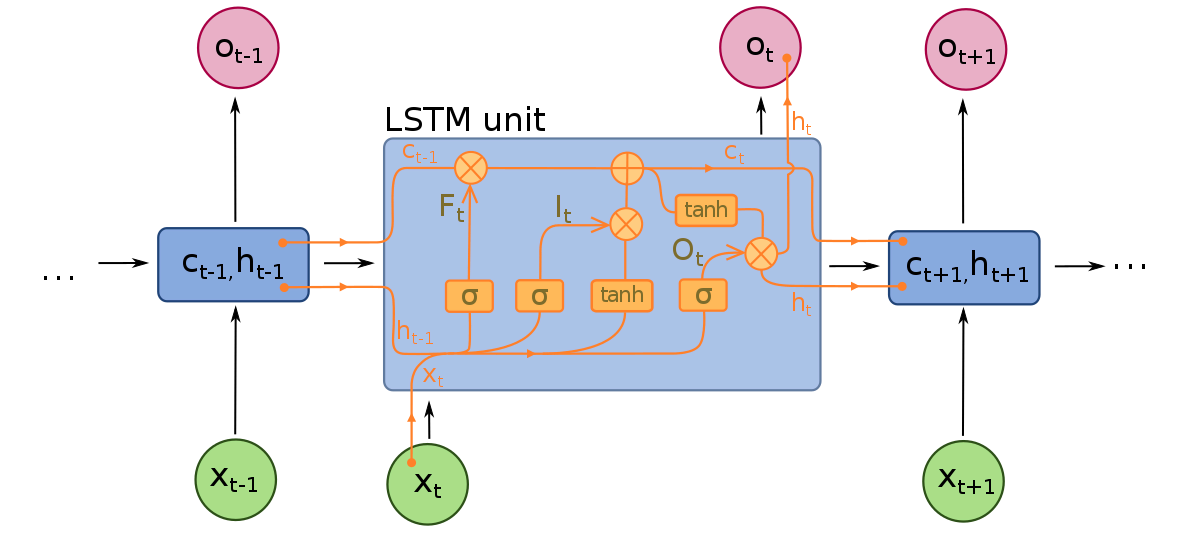
LSTM-modeller består af tre forskellige komponenter eller porte. Der er en inputport, en outputport og en forgetport. Ligesom RNNs tager LSTMs input fra den forrige tidssteg i betragtning, når de ændrer modellens hukommelse og inputvægte. Inputporten træffer beslutninger om, hvilke værdier der er vigtige og skal lukkes igennem modellen. En sigmoidfunktion anvendes i inputporten, som træffer beslutninger om, hvilke værdier der skal videregive gennem det rekurrente netværk. Nul dropper værdien, mens 1 bevare den. En TanH-funktion anvendes her også, som beslutter, hvor vigtigt inputværdierne er for modellen, fra -1 til 1.
Efter den aktuelle input og hukommelsestilstand er blevet taget i betragtning, beslutter outputporten, hvilke værdier der skal føres til næste tidssteg. I outputporten analyseres værdierne og tildeles en vigtighed fra -1 til 1. Dette regulerer data, før de føres videre til næste tidsstegsberegning. Endelig er forgetportens opgave at droppe information, som modellen betragter som unødvendig for at træffe en beslutning om inputværdiernes natur. Forgetporten anvender en sigmoidfunktion på værdierne, der giver tal mellem 0 (glem dette) og 1 (bevar dette).
Et LSTM-neuralt netværk består af både speciale LSTM-lag, der kan fortolke sekventielle orddata, og tæt forbundne lag som dem, der er beskrevet ovenfor. Når dataene passerer gennem LSTM-lagene, går de videre til de tæt forbundne lag.








