Kybernetická bezpečnost
Proč útoky na obrázky jsou žádná legrace
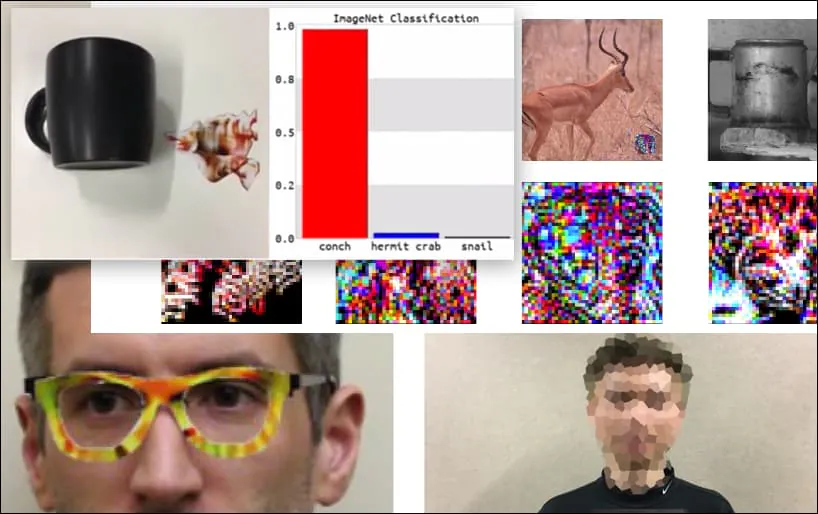
Útoky na systémy rozpoznávání obrázků pomocí pečlivě vytvořených adversářských obrázků byly v posledních pěti letech považovány za zábavnou, ale triviální demonstraci. Nová studie z Austrálie však naznačuje, že neformální použití velmi populárních sad obrázků pro komerční projekty AI může vytvořit nový bezpečnostní problém.
Po dobu několika let se skupina akademiků na University of Adelaide snažila vysvětlit něco velmi důležitého o budoucnosti systémů rozpoznávání obrázků založených na AI.
Je to něco, co by bylo obtížné (a velmi drahé) opravit právě teď, a co by bylo neuvěřitelně drahé napravit, až se současné trendy ve výzkumu rozpoznávání obrázků plně rozvinou do komerčních a industrializovaných nasazení za 5-10 let.
Než se ponoříme do toho, podívejme se na květinu, která je klasifikována jako prezident Barack Obama, z jednoho ze šesti videí, které tým zveřejnil na projektové stránce:
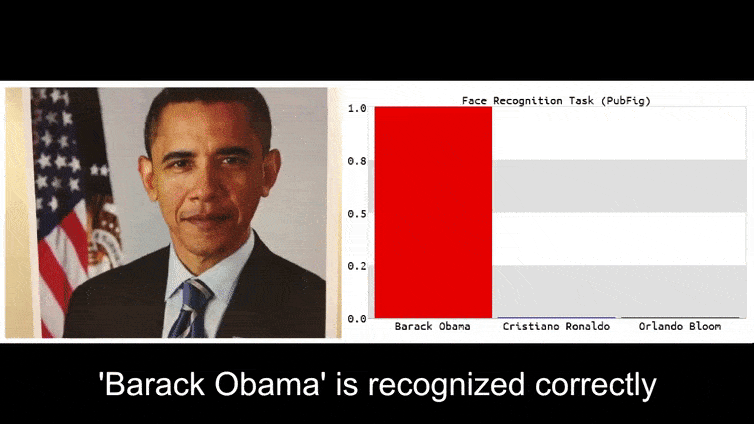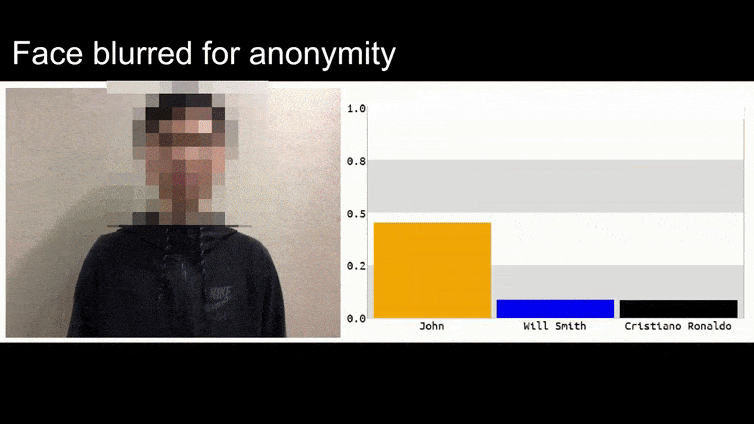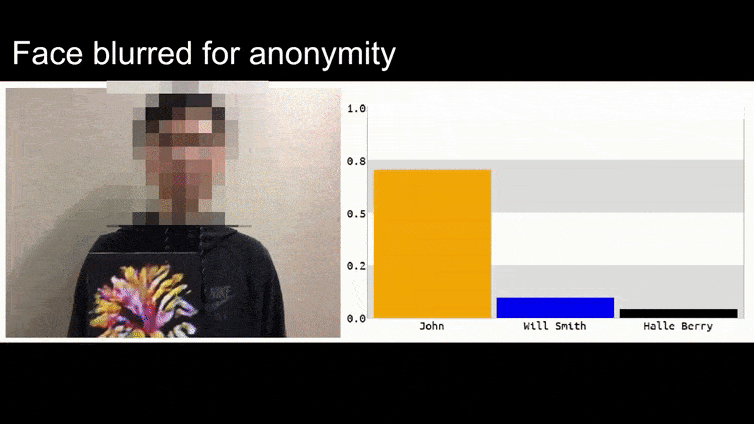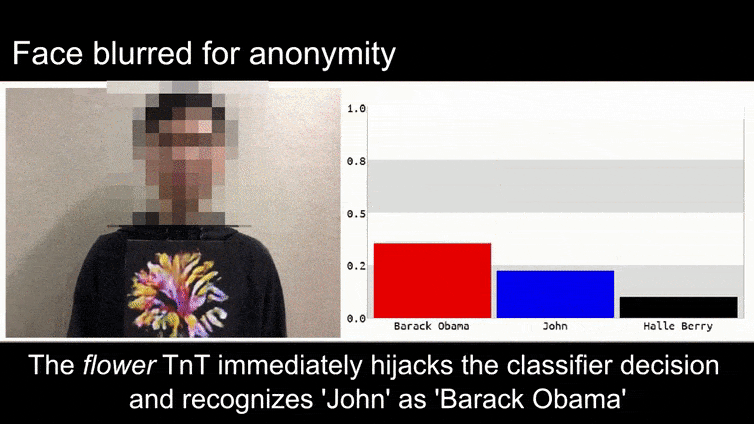
Source: https://www.youtube.com/watch?v=Klepca1Ny3c
Na výše uvedeném obrázku je systém rozpoznávání obličeje, který jasně ví, jak rozpoznat Baracka Obamu, oklámán s 80% jistotou, že anonymní muž držící vytvořený, vytištěný adversářský obrázek květiny je také Barack Obama. Systém se ani nezajímá o to, že “falešná tvář” je na hrudi subjektu, místo na ramenou.
Ačkoli je působivé, že výzkumníci byli schopni dosáhnout tohoto druhu zachycení identity generováním koherentního obrázku (květiny) místo obvyklého náhodného šumu, zdá se, že takové hloupé exploity se objevují poměrně pravidelně ve výzkumu bezpečnosti počítačového vidění. Například ty podivně vzorované brýle, které byly schopny oklamat rozpoznávání obličeje v roce 2016, nebo speciálně vytvořené adversářské obrázky, které se snaží přepisovat dopravní značky.
Pokud máte zájem, model Convolutional Neural Network (CNN), který je v výše uvedeném příkladu napaden, je VGGFace (VGG-16), který byl vyškoleno na sadě PubFig z Kolumbijské univerzity. Další ukázkové útoky vyvinuté výzkumníky používaly různé zdroje v různých kombinacích.

Klávesnice je znovu klasifikována jako lastura, v modelu WideResNet50 na ImageNet. Výzkumníci také zajistili, že model nemá žádnou předpojatost vůči lasturám. Viz kompletní video pro prodloužené a další demonstrace na https://www.youtube.com/watch?v=dhTTjjrxIcU
Rozpoznávání obrázků jako vznikající vektor útoku
Mnohé působivé útoky, které výzkumníci popisují a ilustrují, nejsou kritikou konkrétních sad dat nebo specifických architektur strojového učení, které je používají. Ani je nelze snadno bránit přepnutím sad dat nebo modelů, přeškolováním modelů nebo jakýmikoli jinými “jednoduchými” prostředky, které způsobují, že praktici strojového učení se smějí sporadickým demonstracím tohoto druhu triků.
Spíše demonstrují centrální slabost v celé současné architektuře rozvoje AI pro rozpoznávání obrázků; slabost, která by mohla vystavit mnoho budoucích systémů rozpoznávání obrázků facilní manipulaci útočníky a umístit jakékoli následné obranné opatření do pozice, kdy bude reagovat na útoky.
Představte si nejnovější adversářské útoky na obrázky (jako je květinový obrázek výše) přidávané jako “zero-day exploity” do bezpečnostních systémů budoucnosti, stejně jako současné anti-malware a antivirové rámce aktualizují své definice virů každý den.
Potenciál pro nové adversářské útoky na obrázky by byl nevyčerpatelný, protože základová architektura systému nezohlednila problémy, které mohou nastat později, stejně jako se to stalo s internetem, Millennium Bug a šikmou věží v Pise.
Jakým způsobem tedy vytváříme podmínky pro to?
Získání dat pro útok
Adversářské obrázky, jako je výše uvedený příklad květiny, jsou generovány pomocí přístupu k sadám obrázků, které byly použity pro výcvik počítačových modelů. Není třeba “privilegovaný” přístup k trénovacím datům (nebo architekturám modelů), protože nejpopulárnější sady dat (a mnoho trénovaných modelů) jsou široce dostupné v robustním a neustále aktualizovaném torrent scénáři.
Například slavný Goliáš počítačového vidění, ImageNet, je dostupný přes Torrent ve všech svých mnoha iteracích, čímž se obcházejí jeho obvyklá omezení, a zpřístupňují důležité sekundární prvky, jako jsou validační sady.

Source: https://academictorrents.com
Pokud máte data, můžete (jak pozorují australský výzkumníci) efektivně “reverzně inženýrovat” jakoukoli populární sadu dat, jako je CityScapes, nebo CIFAR.
V případě PubFig, sady dat, která umožnila “Obama Flower” v předchozím příkladu, Kolumbijská univerzita řeší rostoucí trend autorskoprávních problémů kolem redistribuce sad obrázků tím, že instruuje výzkumníky, jak reprodukovat sadu dat prostřednictvím kuriózních odkazů, místo aby přímo zpřístupnili kompilaci, a to s poznámkou ‘Toto se zdá být způsobem, jakým se ostatní velké webové databáze zdají vyvíjet’.
Ve většině případů to není nutné: Kaggle odhaduje, že deset nejpopulárnějších sad obrázků v počítačovém vidění jsou: CIFAR-10 a CIFAR-100 (obě přímo stažitelné); CALTECH-101 a 256 (obě dostupné, a obě aktuálně dostupné jako torrenty); MNIST (oficiálně dostupné, také na torrentech); ImageNet (viz výše); Pascal VOC (dostupné, také na torrentech); MS COCO (dostupné, a na torrentech); Sports-1M (dostupné); a YouTube-8M (dostupné).
Tato dostupnost je také reprezentativní pro širší rozsah dostupných počítačových vidění sad obrázků, protože neznámost je smrt v kultuře otevřeného vývoje “publikuj nebo zemři”.
V každém případě je vzácnost spravovatelných nových sad dat, vysoká cena vývoje sady obrázků, závislost na “starých oblíbencích” a tendence pouze přizpůsobit starší sady dat všechny zhoršují problém popsáný v nové australské studii.
Typické kritiky metod adversářských útoků na obrázky
Nejběžnější a nejtrvalejší kritika strojového učení inženýrů proti účinnosti nejnovější techniky adversářského útoků na obrázky je, že útok je specifický pro konkrétní sadu dat, konkrétní model nebo obojí; že není “generalizovatelný” na jiné systémy; a že tudíž představuje pouze triviální hrozbu.
Druhá nejčastější stížnost je, že adversářský útok na obrázky je ‘bílá skříňka’, což znamená, že byste potřebovali přímý přístup k trénovacímu prostředí nebo datům. To je skutečně nepravděpodobný scénář, ve většině případů – například, pokud byste chtěli využít trénovací proces pro systémy rozpoznávání obličeje londýnské metropolitní policie, museli byste se nabourat do NEC, buď pomocí konzole nebo sekerou.
Dlouhodobá “DNA” populárních počítačových vidění sad dat
Pokud jde o první kritiku, měli bychom zvážit nejen to, že pouhý hrstka počítačových vidění sad dat dominuje průmyslu podle sektoru rok od roku (tj. ImageNet pro více typů objektů, CityScapes pro scény řízení a FFHQ pro rozpoznávání obličeje); ale také to, že jako jednoduchá anotovaná data obrázků jsou “platform agnostické” a vysoce přenositelné.
V závislosti na svých schopnostech najde jakýkoli trénovací architektura počítačového vidění nějaké funkce objektů a tříd v sadě dat ImageNet. Některé architektury mohou najít více funkcí než jiné, nebo udělat více užitečných spojení než jiné, ale všechny by měly najít alespoň nejvyšší úroveň funkcí:

Data ImageNet, s minimálním počtem správných identifikací – ‘vyšší úroveň’ funkcí.
Je to ta “vyšší úroveň” funkcí, která rozlišuje a “otiskuje” sadu dat, a která jsou spolehlivými “háčky” pro zavěšení dlouhodobé metodologie adversářského útoků na obrázky, která může překročit různé systémy a růst společně se “starou” sadou dat, jak je ta poslední zachovávána v novém výzkumu a produktech.
Více sofistikovaná architektura bude produkovat více přesné a jemné identifikace, funkce a třídy:

Avšak čím více se adversářský útok na obrázky spoléhá na tyto nižší funkce (tj. “Mladý běloch” místo “Obličej”), tím méně účinný bude v překročení nebo pozdějších architekturách, které používají různé verze původní sady dat – jako je podmnožina nebo filtrovaná sada, kde mnoho původních obrázků ze sady dat není přítomno:

Adversářské útoky na “zeroed”, předtrénované modely
Co se týče případů, kdy si prostě stáhnete předtrénovaný model, který byl původně trénován na velmi populární sadě dat, a dáte mu zcela nová data?
Model byl již trénován na (například) ImageNet, a vše, co zbývá, jsou váhy, které mohou trvat týdny nebo měsíce, a jsou nyní připraveny pomoci vám identifikovat podobné objekty jako ty, které existovaly v původních (nyní chybějících) datech.

S původními daty odstraněnými z trénovací architektury, co zbývá, je ‘predispozice’ modelu klasifikovat objekty způsobem, jakým se původně naučil dělat, což bude způsobovat, že mnoho původních ‘signatur’ se opět vytvoří a stane se zranitelnými vůči stejným starým metodám adversářských útoků na obrázky.
Tyto váhy jsou cenné. Bez dat nebo váh, máte vlastně prázdnou architekturu bez dat. Budete muset ji trénovat od začátku, při velkých nákladech času a výpočetních zdrojů, stejně jako původní autoři (pravděpodobně na výkonnějším hardwaru a s vyšším rozpočtem, než máte k dispozici).
Problém je, že váhy jsou již khá dobře utvořené a odolné. Ačkoli se budou trochu přizpůsobovat během trénování, budou se chovat podobně na vašich nových datech jako na původních datech, produkovat signální funkce, které může systém adversářského útoků na obrázky opět použít.
V dlouhodobém horizontu to také zachovává “DNA” počítačových vidění sad dat, které jsou dvanáct nebo více let staré, a které mohou projít pozoruhodnou evolucí od otevřených zdrojů až po komerční nasazení – i když původní trénovací data byla zcela odstraněna na začátku projektu. Některé z těchto komerčních nasazení se nemusí objevit až za několik let.
Žádná bílá skříňka není potřeba
Pokud jde o druhou běžnou kritiku systémů adversářských útoků na obrázky, autoři nové studie zjistili, že jejich schopnost oklamat systémy rozpoznávání s vytvořenými obrázky květin je vysoce přenositelná napříč několika architekturami.
Zatímco pozorují, že jejich metoda “Universal NaTuralistic adversarial paTches” (TnT) je první, která používá rozpoznatelné obrázky (místo náhodného rušení) k oklamání systémů rozpoznávání obrázků, autoři také uvádějí:
‘[TnTs] jsou účinné proti několika státním klasifikátorům, od široce používaného WideResNet50 v úkolu Large-Scale Visual Recognition sady dat ImageNet na modely VGG-face v úkolu rozpoznávání obličeje sady dat PubFig v obou cílených a neřízených útocích.
‘TnTs mohou mít: i) naturalismus dosažitelný [s] spouštěči používanými v metodách Trojan útoků; a ii) generalizaci a přenositelnost adversářských příkladů na jiné sítě.
‘To vyvolává bezpečnostní a bezpečnostní obavy týkající se již nasazených DNN, stejně jako budoucích nasazení DNN, kde útočníci mohou použít nenápadné, přirozeně vypadající objektové patche, aby svedli neuronové sítě, aniž by ohrozili model a riskovali objev.
Autoři naznačují, že konvenční protiopatření, jako je zhoršení Clean Acc. sítě, by teoreticky mohla poskytnout some obranu proti patche TnT, ale že ‘TnTs stále mohou úspěšně obejít tuto SOTA prokazatelnou obranu metod, s většinou obranných systémů, které dosahují 0% odolnosti’.
Možnými dalšími řešeními jsou federované učení, kde je chráněna provenience přispívajících obrázků, a nové přístupy, které by mohly přímo “zašifrovat” data během trénování, jako je jeden nedávno navržen Nanjing University of Aeronautics and Astronautics.
I v těchto případech by bylo důležité trénovat na skutečně nová data obrázků – nyní jsou obrázky a přidružené anotace v malé skupině nejpopulárnějších sad dat CV tak hluboce zakořeněny v vývojových cyklech po celém světě, že připomínají software více než data; software, který často nebyl pozoruhodně aktualizován za roky.
Závěr
Adversářské útoky na obrázky jsou umožňovány nejen otevřenými praktikami strojového učení, ale také firemní kulturou AI, která je motivována k opětovnému použití zavedených počítačových vidění sad dat z několika důvodů: prokázaly se jako účinné; jsou mnohem levnější než “začít od začátku”; a jsou udržovány a aktualizovány předními myslí a organizacemi napříč akademií a průmyslem, na úrovních financování a personálu, které by bylo obtížné pro jednu společnost replikovat.
Kromě toho, ve mnoha případech, kde data nejsou původní (na rozdíl od CityScapes), byly obrázky shromážděny před nedávnými kontroverzemi kolem praktik ochrany soukromí a shromažďování dat, což zanechává tyto starší sady dat v某 druhu poloprávního limbu, který může vypadat jako “bezpečný přístav” z pohledu společnosti.
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems je spoluvydaný Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe z University of Adelaide, spolu se Shiqing Ma z Department of Computer Science na Rutgers University.
Aktualizováno 1. prosince 2021, 7:06 GMT+2 – opravena chyba.












