AI 101
Co je Bayesův teorém?
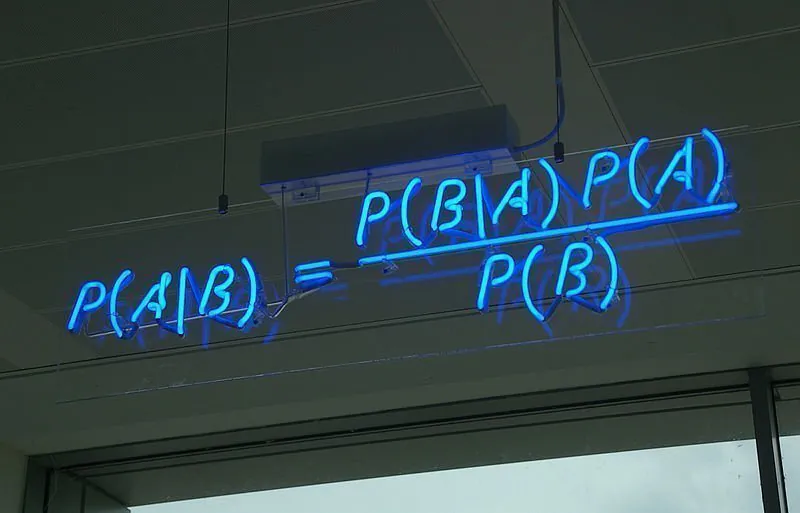
Pokud jste se učí o datové vědě nebo strojovém učení, existuje dobrá šance, že jste již dříve slyšeli termín „Bayesův teorém“ nebo „Bayesův klasifikátor“. Tyto koncepty mohou být somewhat matoucí, zejména pokud nejste zvyklí myslet na pravděpodobnost z tradičního, frequentistického statistického hlediska. Tento článek se pokusí vysvětlit principy, které stojí za Bayesovým teorémem, a jak je používán ve strojovém učení.
Co je Bayesův teorém?
Bayesův teorém je metoda výpočtu podmíněné pravděpodobnosti. Tradiční metoda výpočtu podmíněné pravděpodobnosti (pravděpodobnost, že nastane jeden událost, za předpokladu, že nastane jiná událost) spočívá v použití vzorce podmíněné pravděpodobnosti, výpočtu společné pravděpodobnosti obou událostí a poté dělení tímto výsledkem podle pravděpodobnosti druhé události. Podmíněná pravděpodobnost lze však vypočítat i jiným způsobem pomocí Bayesova teorému.
Při výpočtu podmíněné pravděpodobnosti pomocí Bayesova teorému postupujete takto:
- Určete pravděpodobnost, že podmínka B je pravdivá, za předpokladu, že podmínka A je pravdivá.
- Určete pravděpodobnost, že událost A je pravdivá.
- Vynásobte obě pravděpodobnosti.
- Vydělte výsledkem pravděpodobností události B.
To znamená, že vzorec pro Bayesův teorém lze vyjádřit takto:
P(A|B) = P(B|A)*P(A) / P(B)
Výpočet podmíněné pravděpodobnosti tímto způsobem je zvláště užitečný, pokud lze snadno vypočítat obrácenou podmíněnou pravděpodobnost, nebo pokud by výpočet společné pravděpodobnosti byl příliš složitý.
Příklad Bayesova teorému
Toto může být snazší interpretovat, pokud strávíme nějaký čas prohlížením příkladu toho, jak byste aplikovali Bayesianovu logiku a Bayesův teorém. Předpokládejme, že hrajete jednoduchou hru, ve které vám více účastníků vypráví příběh a musíte určit, který z účastníků lže. Předpokládejme, že chcete vyplnit rovnici pro Bayesův teorém s proměnnými v tomto hypotetickém scénáři.
Snažíme se předpovědět, zda je každý jedinec v hře lžící nebo říká pravdu, takže pokud existují tři hráči kromě vás, kategoriální proměnné lze vyjádřit jako A1, A2 a A3. Důkazy o jejich lžích/pravdě jsou jejich chováním. Jako při hraní pokeru byste hledali určité „signály“, které naznačují, že osoba lže, a použili byste tyto informace k informování vaší odhadu. Nebo pokud byste mohli položit otázky, důkazy by byly jakékoli nesrovnalosti ve vyprávění. Důkazy o tom, že osoba lže, lze reprezentovat jako B.
Chceme předpovědět pravděpodobnost (A lže/říká pravdu | za předpokladu důkazů o jejich chování). Chceme zjistit, za jakých podmínek by se chovalo nejlépe. Pokud existují tři chování, která pozorujete, provedete výpočet pro každé chování. Například P(B1, B2, B3 * A). Provedete to pro každou událost A/pro každého člověka v hře kromě vás. To je tato část rovnice výše:
P(B1, B2, B3,|A) * P|A
Nakonec pouze vydělíme výsledkem pravděpodobností B.
Pokud bychom získali jakékoli důkazy o skutečných pravděpodobnostech v tomto vzorci, rekreovali bychom náš model pravděpodobnosti, přičemž bychom zohlednili nová důkazy. To se nazývá aktualizace našich předpokladů, protože aktualizujeme naše předpoklady o předchozí pravděpodobnosti pozorovaných událostí.
Aplikace Bayesova teorému ve strojovém učení
Nejčastější použití Bayesova teorému ve strojovém učení je v podobě algoritmu Naive Bayes.
Naive Bayes se používá pro klasifikaci binárních a multi-třídních dat, Naive Bayes získává své jméno, protože hodnoty přiřazené k důkazům/atributům – B v P(B1, B2, B3 * A) – se předpokládají jako nezávislé na sobě. Předpokládá se, že tyto atributy neovlivňují navzájem, aby se zjednodušil model a ermögnil výpočty, místo aby se pokusily vypočítat vztahy mezi každým atributem. Navzdory tomuto zjednodušení se Naive Bayes často osvědčuje jako klasifikační algoritmus, i když toto předpoklad pravděpodobně není pravdivý (což je většina času).
Existují také běžně používané varianty klasifikátoru Naive Bayes, jako je Multinomial Naive Bayes, Bernoulli Naive Bayes a Gaussian Naive Bayes.
Multinomial Naive Bayes algoritmy se často používají pro klasifikaci dokumentů, protože jsou efektivní při interpretaci frekvence slov v dokumentu.
Bernoulli Naive Bayes funguje podobně jako Multinomial Naive Bayes, ale předpovědi vygenerované algoritmem jsou booleany. To znamená, že při předpovídání třídy budou hodnoty binární, ano nebo ne. V oblasti klasifikace textu by algoritmus Bernoulli Naive Bayes přiřadil parametrům ano nebo ne na základě toho, zda je slovo nalezeno v textu nebo ne.
Pokud jsou hodnoty prediktorů/prvků nekonečné, ale jsou místo toho kontinuální, lze použít Gaussian Naive Bayes. Předpokládá se, že hodnoty kontinuálních prvků byly vzorkovány z gaussovského rozdělení.












