
AI 101
Co je Overfitting?
Co je Overfitting?
Když trénujete neuronovou síť, musíte se vyvarovat nadměrného vybavení. Přetížení je problém v rámci strojového učení a statistiky, kdy se model příliš dobře učí vzory trénovací datové sady, dokonale vysvětluje trénovací datovou sadu, ale nedokáže zobecnit její prediktivní schopnost na jiné sady dat.
Řečeno jinak, v případě přepasovaného modelu bude často vykazovat extrémně vysokou přesnost trénovací datové sady, ale nízkou přesnost dat shromážděných a procházejících modelem v budoucnu. To je rychlá definice nadměrného vybavení, ale pojďme si tento pojem probrat podrobněji. Pojďme se podívat na to, jak dochází k nadměrnému vybavení a jak se mu lze vyhnout.
Porozumění „přizpůsobení“ a nedostatečnému vybavení
Je užitečné podívat se na koncept underfitting a „fit“ obecně při diskusi o nadměrném vybavení. Když trénujeme model, snažíme se vyvinout rámec, který je schopen předpovídat povahu nebo třídu položek v rámci datové sady na základě funkcí, které tyto položky popisují. Model by měl být schopen vysvětlit vzor v rámci datové sady a předpovědět třídy budoucích datových bodů na základě tohoto vzoru. Čím lépe model vysvětluje vztah mezi vlastnostmi tréninkové sady, tím je náš model „vhodnější“.
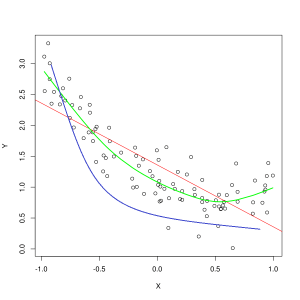
Modrá čára představuje předpovědi modelu, který nevyhovuje, zatímco zelená čára představuje vhodnější model. Foto: Pep Roca přes Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Model, který špatně vysvětluje vztah mezi vlastnostmi trénovacích dat, a proto nedokáže přesně klasifikovat budoucí příklady dat, je podvybavení tréninková data. Pokud byste měli vykreslit graf předpokládaného vztahu modelu nedostatečného přizpůsobení proti skutečnému průniku prvků a štítků, předpovědi by se odchýlily od značky. Pokud bychom měli graf se skutečnými hodnotami trénovací sady označený, silně nevyhovující model by drasticky minul většinu datových bodů. Model s lepším přizpůsobením by mohl proříznout cestu středem datových bodů, přičemž jednotlivé datové body budou jen o málo mimo předpokládané hodnoty.
K nedostatečnému přizpůsobení může často dojít, když není dostatek dat k vytvoření přesného modelu, nebo když se pokoušíte navrhnout lineární model s nelineárními daty. Více tréninkových dat nebo více funkcí často pomůže snížit nedostatečné vybavení.
Proč bychom tedy prostě nevytvořili model, který dokonale vysvětluje každý bod v trénovacích datech? Je jistě žádoucí dokonalá přesnost? Vytváření modelu, který se příliš dobře naučil vzorce trénovacích dat, způsobuje nadměrné přizpůsobení. Tréninková datová sada a další budoucí datové sady, které spustíte modelem, nebudou úplně stejné. Pravděpodobně si budou v mnoha ohledech velmi podobné, ale budou se také lišit v klíčových ohledech. Proto navržení modelu, který dokonale vysvětluje trénovací datovou sadu, znamená, že skončíte s teorií o vztahu mezi funkcemi, která se nedá dobře zobecnit na jiné datové sady.
Pochopení nadměrného vybavení
K přefitování dochází, když se model příliš dobře učí podrobnosti v rámci trénovací datové sady, což způsobuje, že model trpí, když jsou předpovědi prováděny na externích datech. K tomu může dojít, když se model nejen naučí vlastnosti datové sady, ale také se naučí náhodné fluktuace resp hluk v rámci datové sady, přičemž důraz je kladen na tyto náhodné/nedůležité události.
Při použití nelineárních modelů je pravděpodobnější, že dojde k přesazení, protože jsou flexibilnější při učení datových funkcí. Algoritmy neparametrického strojového učení mají často různé parametry a techniky, které lze použít k omezení citlivosti modelu na data, a tím ke snížení nadměrného přizpůsobení. Jako příklad, modely rozhodovacích stromů jsou vysoce citlivé na přemontování, ale k náhodnému odstranění některých detailů, které se model naučil, lze použít techniku zvanou prořezávání.
Pokud byste měli znázornit předpovědi modelu na osách X a Y, měli byste předpovědní čáru, která se klikatí tam a zpět, což odráží skutečnost, že se model příliš snažil začlenit všechny body v souboru dat do jeho vysvětlení.
Ovládání overfittingu
Když model trénujeme, v ideálním případě chceme, aby model nedělal žádné chyby. Když výkon modelu konverguje k provádění správných předpovědí pro všechny datové body v trénovací datové sadě, shoda se stává lepší. Model, který se dobře hodí, je schopen vysvětlit téměř všechny trénovací datové sady, aniž by se přepínal.
Jak model trénuje, jeho výkon se postupem času zlepšuje. Chybovost modelu se bude s postupem času trénování snižovat, ale snižuje se pouze do určitého bodu. Bod, ve kterém výkon modelu na testovací sadě začíná opět stoupat, je obvykle bodem, kdy dochází k přemontování. Abychom pro model co nejlépe seděli, chceme ukončit trénování modelu v bodě nejnižší ztráty na trénovací sadě, než se chyba začne znovu zvyšovat. Optimální bod zastavení lze zjistit grafem výkonu modelu po celou dobu tréninku a zastavením tréninku, když je ztráta nejnižší. Jedním rizikem této metody kontroly nadměrného vybavení je však to, že specifikování koncového bodu pro trénování na základě výkonu testu znamená, že testovací data budou poněkud zahrnuta do tréninkového postupu a ztratí svůj status jako čistě „nedotčená“ data.
Existuje několik různých způsobů, jak lze bojovat proti nadměrnému vybavení. Jednou z metod, jak omezit přemontování, je použití taktiky převzorkování, která funguje na základě odhadu přesnosti modelu. Můžete také použít a validace datovou sadu navíc k testovací sadě a vykreslete přesnost tréninku proti ověřovací sadě namísto testovací datové sady. Vaše testovací datová sada tak zůstane neviditelná. Oblíbenou metodou převzorkování je křížová validace K-foldů. Tato technika vám umožňuje rozdělit data do podmnožin, na kterých je model trénován, a poté je analyzován výkon modelu na podmnožinách, aby bylo možné odhadnout, jak bude model fungovat na externích datech.
Využití křížové validace je jedním z nejlepších způsobů, jak odhadnout přesnost modelu na neviditelných datech, a v kombinaci s validační datovou sadou může být přepastování často omezeno na minimum.










