
AI 101
Co je lineární regrese?
Co je lineární regrese?
Lineární regrese je algoritmus používaný k predikci nebo vizualizaci a vztah mezi dvěma různými rysy/proměnnými. V úlohách lineární regrese se zkoumají dva druhy proměnných: závislá proměnná a nezávislá proměnná. Nezávislá proměnná je proměnná, která stojí sama o sobě a není ovlivněna jinou proměnnou. Jak se nezávislá proměnná upravuje, úrovně závislé proměnné budou kolísat. Závislá proměnná je proměnná, která je studována, a to je to, co regresní model řeší/pokouší se předpovídat. V úlohách lineární regrese se každé pozorování/instance skládá jak z hodnoty závislé proměnné, tak z hodnoty nezávisle proměnné.
To bylo rychlé vysvětlení lineární regrese, ale pojďme se ujistit, že lineární regresi lépe porozumíme tím, že se podíváme na její příklad a prozkoumáme vzorec, který používá.
Porozumění lineární regresi
Předpokládejme, že máme datovou sadu pokrývající velikosti pevných disků a náklady na tyto pevné disky.
Předpokládejme, že soubor dat, který máme, se skládá ze dvou různých funkcí: množství paměti a náklady. Čím více paměti do počítače zakoupíme, tím více se cena nákupu zvýší. Pokud bychom vynesli jednotlivé datové body do bodového grafu, mohli bychom získat graf, který vypadá asi takto:

Přesný poměr paměti k ceně se může lišit mezi výrobci a modely pevných disků, ale obecně platí, že trend dat začíná vlevo dole (kde jsou pevné disky levnější a mají menší kapacitu) a přesouvají se do vpravo nahoře (kde jsou disky dražší a mají vyšší kapacitu).
Pokud bychom měli množství paměti na ose X a náklady na ose Y, začínala by čára zachycující vztah mezi proměnnými X a Y v levém dolním rohu a probíhala by vpravo nahoře.
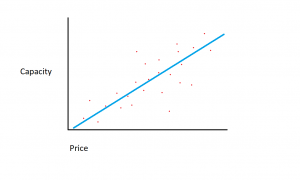
Funkcí regresního modelu je určit lineární funkci mezi proměnnými X a Y, která nejlépe popisuje vztah mezi těmito dvěma proměnnými. V lineární regresi se předpokládá, že Y lze vypočítat z nějaké kombinace vstupních proměnných. Vztah mezi vstupními proměnnými (X) a cílovými proměnnými (Y) lze zobrazit nakreslením čáry přes body v grafu. Čára představuje funkci, která nejlépe popisuje vztah mezi X a Y (například pokaždé, když se X zvýší o 3, Y se zvýší o 2). Cílem je najít optimální „regresní přímku“ nebo linii/funkci, která nejlépe odpovídá datům.
Čáry jsou typicky reprezentovány rovnicí: Y = m*X + b. X označuje závislou proměnnou, zatímco Y je nezávislá proměnná. Mezitím m je sklon přímky, jak je definováno „nárůstem“ nad „během“. Praktici strojového učení představují slavnou rovnici se sklonem trochu jinak a místo toho používají tuto rovnici:
y(x) = w0 + w1 * x
Ve výše uvedené rovnici je y cílová proměnná, zatímco „w“ jsou parametry modelu a vstup je „x“. Rovnice se tedy čte jako: „Funkce, která dává Y v závislosti na X, se rovná parametrům modelu vynásobeným vlastnostmi“. Parametry modelu se upravují během tréninku tak, aby byla co nejlépe přizpůsobena regresní přímce.
Vícenásobná lineární regrese

Foto: Cbaf přes Wikimedia Commons, Public Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Výše popsaný proces se vztahuje na jednoduchou lineární regresi nebo regresi na souborech dat, kde existuje pouze jeden prvek/nezávislá proměnná. Regresi však lze provést i s více funkcemi. V případě "vícenásobná lineární regrese“, rovnice je rozšířena o počet proměnných nalezených v datové sadě. Jinými slovy, zatímco rovnice pro pravidelnou lineární regresi je y(x) = w0 + w1 * x, rovnice pro vícenásobnou lineární regresi by byla y(x) = w0 + w1x1 plus váhy a vstupy pro různé funkce. Pokud budeme reprezentovat celkový počet vah a prvků jako w(n)x(n), mohli bychom vzorec reprezentovat takto:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Po vytvoření vzorce pro lineární regresi bude model strojového učení používat různé hodnoty pro váhy a nakreslí různé linie přizpůsobení. Pamatujte, že cílem je najít řádek, který nejlépe odpovídá datům, abyste mohli určit, která z možných kombinací vah (a tedy která možná linie) nejlépe odpovídá datům, a vysvětlit vztah mezi proměnnými.
Nákladová funkce se používá k měření toho, jak blízko jsou předpokládané hodnoty Y skutečným hodnotám Y při dané konkrétní hodnotě hmotnosti. Nákladová funkce pro lineární regresi je střední kvadratická chyba, která pouze bere průměrnou (kvadratickou) chybu mezi předpokládanou hodnotou a skutečnou hodnotou pro všechny různé datové body v datové sadě. Nákladová funkce se používá k výpočtu nákladů, které zachycují rozdíl mezi předpokládanou cílovou hodnotou a skutečnou cílovou hodnotou. Pokud je proložená čára daleko od datových bodů, náklady budou vyšší, zatímco náklady budou tím menší, čím více se čára přiblíží k zachycení skutečných vztahů mezi proměnnými. Váhy modelu se pak upravují, dokud není nalezena konfigurace závaží, která produkuje nejmenší množství chyb.










