Umělá inteligence
Směřování k reálnému čase AI lidských bytostí s renderováním Neural Lumigraph

Navzdory současné vlně zájmu o Neural Radiance Fields (NeRF), technologii schopné vytvářet AI generované 3D prostředí a objekty, tato nová přístup k technologii syntézy obrazu stále vyžaduje velké množství času na trénování a postrádá implementaci, která umožňuje reálný čas, vysoce responsivní rozhraní.
Nicméně, spolupráce mezi některými působivými názvy v průmyslu a akademii nabízí nový pohled na tuto výzvu (obecně známou jako Novel View Synthesis, nebo NVS).
Výzkumná práce, nazvaná Neural Lumigraph Rendering, tvrdí, že dosahuje zlepšení o dva řády velikosti ve srovnání se stávajícím stavem, což představuje několik kroků směrem k reálnému času CG renderingu prostřednictvím strojových učících se pipeline.

Neural Lumigraph Rendering (right) nabízí lepší rozlišení blending artifactů a lepší zpracování překrytí ve srovnání s předchozími metodami. Source.
Ačkoli kredity za článek citují pouze Stanford University a holografickou technologii společnosti Raxium (v současné době fungující v utajeném režimu), přispěvatelé zahrnují hlavního architekta strojového učení architekta ve společnosti Google, počítačového vědce ve společnosti Adobe a CTO ve společnosti StoryFile (která nedávno vytvořila titulky s AI verzí Williama Shatnera).
V souvislosti s recentní Shatnerovou publicitou, StoryFile zdá se, že využívá NLR ve svém novém procesu pro vytváření interaktivních, AI generovaných entit na základě charakteristik a narativů jednotlivých lidí.
StoryFile předpokládá použití této technologie v muzejních expozicích, online interaktivních narativech, holografických displejích, rozšířené realitě (AR) a dokumentaci dědictví – a zdá se, že také zvažuje potenciální nové aplikace NLR v pohovorech a virtuálních rande:

Navrhované použití z online videa StoryFile. Source: https://www.youtube.com/watch?v=2K9J6q5DqRc
Volumetrická kaptura pro Novel View Synthesis rozhraní a video
Zásadním principem volumetrické kaptury, napříč rozsahem článků, které se na toto téma hromadí, je myšlenka pořízení statických obrazů nebo videí subjektu a použití strojového učení k “vyplnění” pohledů, které nebyly pokryty původní sadou kamer.
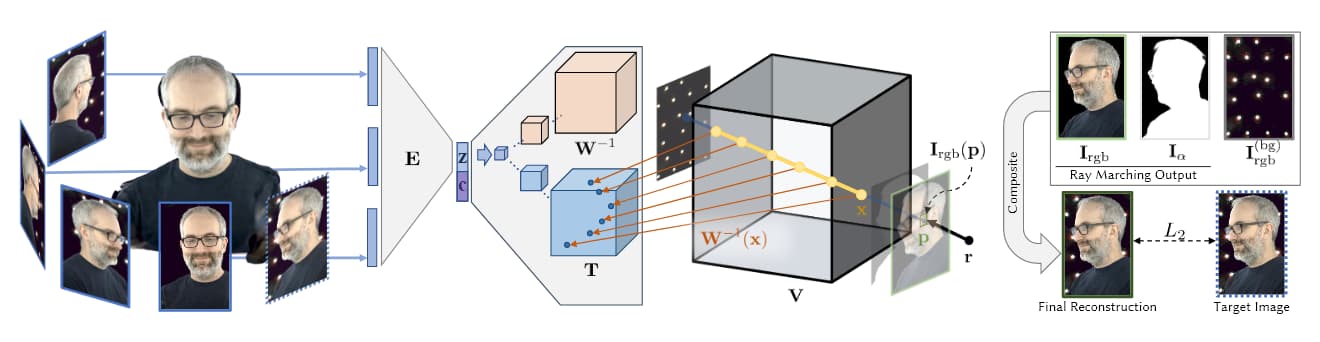
Source: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
Na obrázku výše, pocházejícím z Facebookova AI výzkumu z roku 2019 (viz níže), vidíme čtyři fáze volumetrické kaptury: multiple kamery pořizují obrazy/footage; encoder/decoder architektura (nebo jiná architektura) vypočítává a spojování relativních pohledů; ray-marching algoritmy vypočítávají voxely (nebo jiná XYZ prostorová geometrická jednotka) každého bodu v volumetrickém prostoru; a (v většině recentních článků) trénování probíhá k syntéze kompletní entity, která může být manipulována v reálném čase.
Je to právě tato často rozsáhlá a datově náročná fáze trénování, která doposud držela novel view syntézu mimo oblast reálného času nebo vysoce responsivních rozhraní.
Skutečnost, že Novel View Synthesis vytváří kompletní 3D mapu volumetrického prostoru, znamená, že je relativně triviální spojit tyto body dohromady do tradiční počítačové generované mřížky, efektivní kapturou a artikulací CGI lidské (nebo jiného relativně ohraničeného objektu) na letu.
Přístupy, které využívají NeRF, spoléhají na body cloudy a depth mapy k generování interpolací mezi řídkými body pohledů kamer:

NeRF může generovat volumetrickou hloubku prostřednictvím výpočtu depth map, spíše než generování CG mesh. Source: https://www.youtube.com/watch?v=JuH79E8rdKc
Ačkoli NeRF je schopný vypočítat mřížky, většina implementací toto nedělá, aby generovala volumetrické scény.
Naopak, přístup Implicit Differentiable Renderer (IDR), publikovaný Weizmannovým institutem věd v říjnu 2020, spočívá v využívání 3D mesh informací automaticky generovaných z kamer:

Příklady IDR kamer transformovaných do interaktivních CGI mesh. Source: https://www.youtube.com/watch?v=C55y7RhJ1fE
Zatímco NeRF postrádá IDRovu schopnost tvarové estimace, IDR nemůže dosáhnout NeRFovy kvality obrazu, a obě vyžadují rozsáhlé zdroje pro trénování a sběr (ačkoli recentní inovace v NeRF začínají řešit tuto otázku).

NLR Custom kamerový rig s 16 GoPro HERO7 a 6 centrálními Back-Bone H7PRO kamerami. Pro ‘reálný čas’ renderování, tyto pracují na minimálně 60fps. Source: https://arxiv.org/pdf/2103.11571.pdf
Místo toho, Neural Lumigraph Rendering využívá SIREN (Sinusoidal Representation Networks) k začlenění silných stránek každého přístupu do svého vlastního rámce, který je určen k generování výstupu, který je přímo použitelný v existujících reálných časových grafických pipeline.
SIREN byl využíván pro podobné implementace během posledního roku, a nyní reprezentuje populární API volání pro hobbyist Colabs v image syntéze komunit; nicméně, NLRova inovace spočívá v aplikaci SIRENů na dvou-dimenzionální multi-view image supervizi, což je problematické kvůli rozsahu, ve kterém SIREN produkuje over-fitted spíše než generalizovaný výstup.
Po extrakci CG mřížky z pole obrazů, mřížka je rasterizována prostřednictvím OpenGL, a vertex pozice mřížky jsou mapovány na příslušné pixely, po kterém je vypočítán blending různých přispívajících map.
Výsledná mřížka je více generalizovaná a reprezentativnější než NeRFova (viz obrázek níže), vyžaduje méně výpočtu, a neaplikuje nadměrné detaily do oblastí (jako je hladká obličejová kůže), které z toho nemohou mít prospěch:

Source: https://arxiv.org/pdf/2103.11571.pdf
Na negativní straně, NLR zatím nemá žádnou kapacitu pro dynamické osvětlení nebo relighting, a výstup je omezen na shadow mapy a další osvětlovací úvahy získané v době kaptury. Výzkumníci mají v úmyslu řešit tuto otázku v budoucí práci.
Navíc, článek uznává, že tvary generované NLR nejsou tak přesné jako některé alternativní přístupy, jako je Pixelwise View Selection for Unstructured Multi-View Stereo, nebo Weizmannův institut výzkumu, který je zmíněn výše.
Vzestup Volumetrické obrazové syntézy
Myšlenka vytváření 3D entit z omezené série fotografií s neuronovými sítěmi předchází NeRF, s vizionářskými články sahajícími až do roku 2007 nebo dříve. V roce 2019 Facebookův AI výzkumný odbor produkoval seminální výzkumnou práci, Neural Volumes: Learning Dynamic Renderable Volumes from Images, která poprvé ermögnila responsivní rozhraní pro syntetické lidi generované strojovým učením založeným na volumetrické kaptuře.

Facebookův výzkum z roku 2019 umožnil vytvořit responsivní uživatelské rozhraní pro volumetrickou osobu. Source: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/












