
Umělá inteligence
Nedostatky Amazon Mechanical Turk mohou ohrozit systémy generování přirozeného jazyka

Nová studie z University of Massachusetts Amherst postavila učitele angličtiny proti pracovníkům z crowdsourcingu Amazon Mechanical Turk při posuzování výstupu generování přirozeného jazyka (NLG) systémů a dospěl k závěru, že laxní normy a „hraní“ cenných úkolů mezi pracovníky AMT by mohly bránit rozvoji odvětví.
Zpráva dospívá k řadě usvědčujících závěrů, pokud jde o rozsah, v jakém by levný outsourcing otevřených úkolů NLG v „průmyslovém měřítku“ mohl vést k horším výsledkům a algoritmům v tomto sektoru.
Výzkumníci také sestavili seznam 45 článků o generování otevřeného textu, kde výzkum využíval AMT, a zjistili, že „převážná většina“ nedokázala nahlásit kritické podrobnosti o používání davové služby Amazon, což znesnadnilo reprodukci. nálezy v novinách.
Laboratoř práce
Zpráva kritizuje jak továrnu Amazon Mechanical Turk, tak (pravděpodobně omezený rozpočet) akademické projekty, které propůjčují AMT další důvěryhodnost tím, že ji používají (a citují) jako platný a konzistentní zdroj výzkumu. Autoři poznamenávají:
„Ačkoli AMT je pohodlné a cenově dostupné řešení, pozorujeme, že velké rozdíly mezi pracovníky, špatná kalibrace a kognitivně náročné úkoly mohou vést výzkumníky k zavádějícím vědeckým závěrům (např. že text psaný člověkem je „horší“ než text GPT-2 ).'
Zpráva obviňuje spíše hru než hráče, přičemž výzkumníci pozorují:
"[Davoví] pracovníci jsou často nedostatečně placeni za svou práci, což poškozuje jak kvalitu výzkumu, tak, což je důležitější, schopnost těchto davových pracovníků vydělávat si adekvátní živobytí."
Projekt papírS názvem Nebezpečí používání Mechanical Turk k vyhodnocení generování otevřeného textu, dále dochází k závěru, že „odborní hodnotitelé“, jako jsou učitelé jazyků a lingvisté, by měli být využíváni k hodnocení umělého obsahu NLG s otevřeným koncem, i když je AMT levnější.
Testovací úkoly
Při porovnávání výkonu AMT s méně časově omezenými odbornými čtenáři výzkumníci utratili 144 USD za služby AMT skutečně použité ve srovnávacích testech (ačkoli mnohem více bylo vynaloženo na „nepoužitelné“ výsledky – viz níže), což vyžadovalo náhodné „Turky“. vyhodnotit jeden z 200 textů rozdělených mezi textový obsah vytvořený člověkem a text uměle generovaný.
Úkolování profesionálních učitelů se stejnou prací stálo 187.50 $ a potvrzení jejich vynikajícího výkonu (ve srovnání s pracovníky AMT) najmutím nezávislých pracovníků Upwork, aby replikovali úkoly, stálo dalších 262.50 $.
Každý úkol se skládal ze čtyř hodnotících kritérií: gramatika ("Jak gramaticky správný je text fragmentu příběhu?"); soudržnost ("Jak dobře do sebe zapadají věty ve fragmentu příběhu?"); líbivost ("Jak moc se ti líbí ten fragment příběhu?"); a relevance ("Jak relevantní je fragment příběhu pro výzvu?").
Generování textů
K získání materiálu NLG pro testy použili vědci Facebook AI Research 2018 Generování hierarchického neuronového příběhu dataset, která obsahuje 303,358 15 anglických příběhů vytvořených uživateli na velmi populární (XNUMX milionů a více uživatelů) r/výzvy k zápisu subreddit, kde jsou příběhy předplatitelů „zasévány“ „výzvami“ s jednou větou podobným způsobem jako současné postupy v generování textu na obrázek – a samozřejmě v otevřené generaci přirozeného jazyka systémy.
200 výzev z datové sady bylo náhodně vybráno a prošlo středně velkým modelem GPT-2 pomocí Hugging-Face Transformers knihovna. Ze stejných podnětů byly získány dvě sady výsledků: diskurzivní eseje psané lidmi od uživatelů Reddit a texty generované GPT-2.
Aby se zabránilo tomu, aby stejní pracovníci AMT posuzovali stejný příběh vícekrát, byly pro každý příklad vyžádány tři rozsudky pracovníků AMT. Spolu s experimenty týkajícími se jazykových schopností pracovníků v angličtině (viz konec článku) a diskontováním výsledků od pracovníků s nízkou námahou (viz „Krátká doba“ níže) to zvýšilo celkové výdaje na AMT na přibližně 1,500 XNUMX USD.
Pro vytvoření rovných podmínek byly všechny testy prováděny v pracovní dny mezi 11.00:11 a 30:XNUMX PST.
Výsledky a závěry
Rozsáhlá studie pokrývá mnoho oblastí, ale hlavní body jsou následující:
Krátký čas
List zjistil, že oficiální průměrná doba úkolu 360 sekund uváděná Amazonem se zkrátila na pracovní dobu v reálném světě pouhých 22 sekund a střední pracovní dobu pouze 13 sekund – čtvrtinu času, který zabralo nejrychlejší Učitel angličtiny opakující úkol.
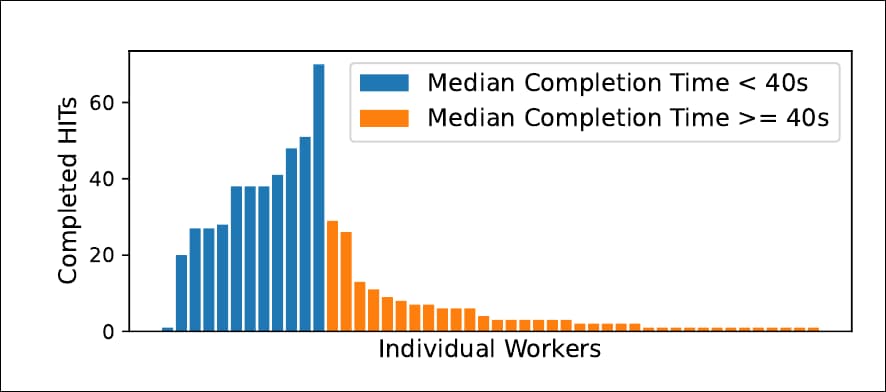
Od 2. dne studie: jednotliví pracovníci (v oranžové barvě) strávili hodnocením každého úkolu výrazně méně času než lépe placení učitelé a (později) ještě lépe placení dodavatelé Upwork. Zdroj: https://arxiv.org/pdf/2109.06835.pdf
Vzhledem k tomu, že AMT neklade žádné omezení na úkoly lidské inteligence (HIT), které může jednotlivý pracovník převzít, objevili se „velcí hiteři“ AMT s (ziskovou) reputací, protože dokončují vysoký počet úkolů na experiment. Aby se kompenzovaly přijaté shody stejným pracovníkem, výzkumníci měřili čas mezi po sobě jdoucími odeslanými shody a porovnávali čas začátku a konce každého shody. Tímto způsobem se ohlásil schodek mezi AMT WorkTimeInSeconds a do centra pozornosti se dostal skutečný čas strávený nad úkolem.
Protože takovou práci nelze provést v těchto zkrácených časových rámcích, výzkumníci to museli kompenzovat:
„Vzhledem k tomu, že není možné pečlivě přečíst příběh o délce odstavce a posoudit všechny čtyři vlastnosti za pouhých 13 sekund, měříme dopad na průměrné hodnocení při filtrování pracovníků, kteří tráví příliš málo času na HIT… Konkrétně odstraňujeme úsudky z pracovníci, jejichž střední doba je nižší než 40 s (což je nízká čára), a zjistili, že v průměru asi 42 % našich hodnocení je odfiltrováno (v rozmezí 20 % až 72 % ve všech experimentech).
Dokument tvrdí, že nesprávně hlášená skutečná pracovní doba v AMT je „hlavním problémem“, který výzkumníci využívající služby obvykle přehlížejí.
Nutné držení v ruce
Zjištění dále naznačují, že pracovníci AMT nemohou spolehlivě rozlišit mezi textem napsaným člověkem a textem napsaným strojem, pokud neuvidí oba texty vedle sebe, což by účinně ohrozilo typický scénář hodnocení (kde by měl být čtenář schopen učinit úsudek na základě jediného vzorku textu, „skutečného“ nebo uměle vytvořeného).
Příležitostné přijímání nekvalitního umělého textu
Pracovníci AMT trvale hodnotili nekvalitní umělý text založený na GPT na stejné úrovni jako kvalitnější, souvislý text napsaný lidmi, na rozdíl od učitelů angličtiny, kteří byli schopni snadno rozlišit rozdíl v kvalitě.
Žádný čas na přípravu, nulový kontext
Zadat správné nastavení mysli pro tak abstraktní úkol, jako je hodnocení autenticity, není přirozené; Učitelé angličtiny potřebovali 20 úkolů, aby zkalibrovali svou citlivost vůči hodnotícímu prostředí, zatímco pracovníci AMT obvykle nemají vůbec žádný „orientační čas“, což snižuje kvalitu jejich vstupů.
Hraní v systému
Zpráva tvrdí, že celkový čas, který pracovníci AMT stráví na jednotlivých úkolech, zvyšují pracovníci, kteří přijímají více úkolů současně a procházejí úkoly na různých kartách ve svých prohlížečích, místo aby se soustředili na jeden úkol po dobu zaznamenaného úkolu.
Země původu je důležitá
Výchozí nastavení AMT nefiltruje pracovníky podle země původu a zpráva uvádí poznámky předchozí práce což naznačuje, že pracovníci AMT používají VPN k obcházení geografických omezení a umožňují nerodilým mluvčím prezentovat se jako rodilí mluvčí angličtiny (v systému, který, možná poněkud naivně, staví na stejnou úroveň mateřský jazyk pracovníka a jeho geografickou polohu založenou na IP).
Výzkumníci tedy znovu provedli hodnotící testy na AMT s filtry omezujícími potenciální zájemce ne-Anglicky mluvící země, najít to 'pracovníci z neanglicky mluvících zemí hodnotili koherenci, relevanci a gramatiku...výrazně nižší než stejně kvalifikovaní pracovníci z anglicky mluvících zemí'.
Zpráva uzavírá:
„[Expertní] hodnotitelé, jako jsou lingvisté nebo učitelé jazyků, by měli být využíváni, kdykoli je to možné, protože již byli vyškoleni k hodnocení psaného textu a není to o moc dražší…“.
Publikováno 16. září 2021 - Aktualizováno 18. prosince 2021: Přidány štítky















