Umělá inteligence
Je DALL-E 2 pouze „lepením věcí“ bez porozumění jejich vztahům?

Nová výzkumná práce z Harvardské univerzity naznačuje, že text-to-image framework DALL-E 2 od OpenAI, který získal velkou pozornost, má značné obtíže při reprodukování i těch nejjednodušších vztahů mezi prvky, které skládá do syntetizovaných fotografií, navzdory ohromující sofistikovanosti většiny jeho výstupů.
Výzkumníci provedli uživatelskou studii se 169 účastníky, kteří byli představeni obrázky DALL-E 2 na základě nejzákladnějších lidských principů vztahové sémantiky, spolu s textovými podněty, které je vytvořily. Když se jich zeptali, zda jsou podněty a obrázky související, méně než 22 % obrázků bylo považováno za relevantní k jejich přidruženým podnětům, z hlediska velmi jednoduchých vztahů, které DALL-E 2 měl visualizovat.

Snímek z trialů provedených pro novou práci. Účastníkům bylo zadáno vybrat všechny obrázky, které odpovídají podnětu. Zdroj: https://arxiv.org/pdf/2208.00005.pdf
Výsledky také naznačují, že zdánlivá schopnost DALL-E spojovat rozdílné prvky může klesat, jak tyto prvky méně pravděpodobně vznikají v reálných trénovacích datech, která pohání systém.
Například obrázky pro podnět „dítě se dotýká misky“ získaly 87% souhlasu (tj. účastníci klikli na většinu obrázků jako relevantních k podnětu), zatímco podobně fotorealistické renderování „opice se dotýká leguána“ dosáhlo pouze 11% souhlasu:


DALL-E má potíže s vykreslením nepravděpodobné události „opice se dotýká leguána“, pravděpodobně proto, že je to neobvyklé, spíše neexistující, ve trénovacích datech.
Ve druhém příkladu DALL-E 2 často chybně určí velikost a dokonce i druh, pravděpodobně kvůli nedostatku reálných obrázků, které tuto událost zobrazují. Naopak je rozumné předpokládat, že existuje velké množství trénovacích fotografií souvisejících s dětmi a jídlem, a že tato subdoména/třída je dobře rozvinutá.
Potíže DALL-E s kombinací silně kontrastních obrazových prvků naznačují, že veřejnost je目前 tak ohromena systémem fotorealistických a široce interpretovatelných schopností, že dosud nevyvinula kritické oko pro případy, kdy systém efektivně pouze „přilepil“ jeden prvek na druhý, jako v těchto příkladech z oficiálního webu DALL-E 2:

Cut-and-paste syntéza, z oficiálních příkladů pro DALL-E 2. Zdroj: https://openai.com/dall-e-2/
Nová práce uvádí*:
‘Relační porozumění je základní složkou lidské inteligence, která se projevuje často v raném vývoji, a je vypočítávána rychle a automaticky v percepci.
‘Potíže DALL-E 2 s dokonce i základními prostorovými vztahy (jako in, on, under) naznačují, že cokoliv se naučil, dosud nenaučil se kinds of reprezentací, které umožňují lidem tak flexibilně a robustně strukturovat svět.
‘Přímá interpretace této potíže je, že systémy jako DALL-E 2 dosud nemají relační kompozicionalitu.’
Autoři navrhují, že systémy textem řízené generace obrázků, jako je série DALL-E, by mohly těžit z využití algoritmů běžných v robotice, které modelují identity a vztahy současně, kvůli potřebě agenta skutečně interagovat s prostředím, spíše než pouze fabrikovat směs rozdílných prvků.
Jedním z takových přístupů je CLIPort, který používá stejný CLIP mechanismus, který slouží jako prvek hodnocení kvality v DALL-E 2:
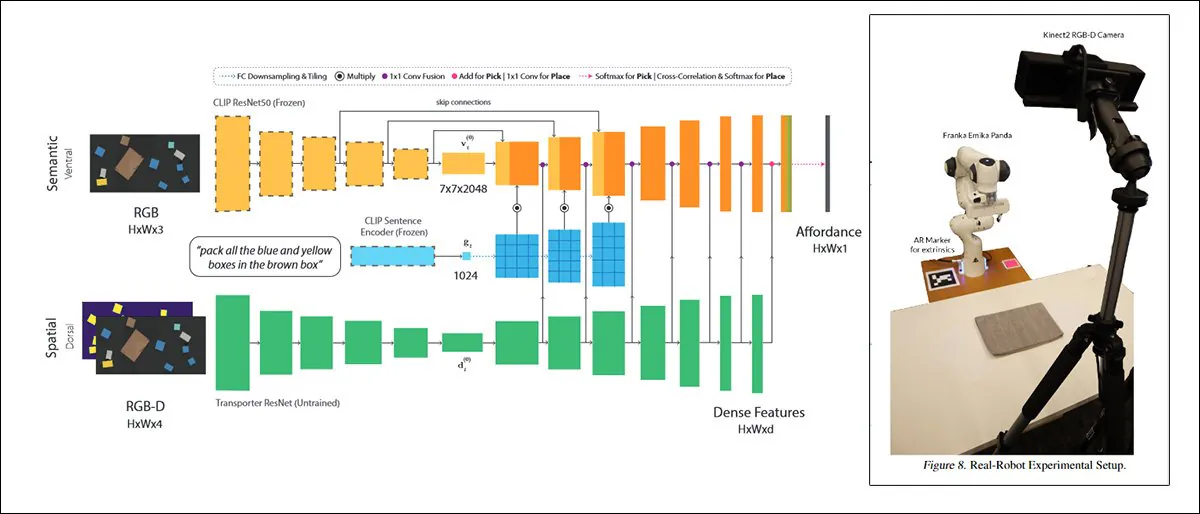
CLIPort, spolupráce z roku 2021 mezi University of Washington a NVIDIA, používá CLIP v kontextu tak praktickém, že systémy školené na něm musí nutně vyvinout porozumění fyzickým vztahům, motivátor, který chybí v DALL-E 2 a podobných „fantastických“ rámcích syntézy obrázků. Zdroj: https://arxiv.org/pdf/2109.12098.pdf
Autoři dále navrhují, že „další možný upgrade“ by mohl být pro architekturu systémů syntézy obrázků, jako je DALL-E, zahrnout násobné účinky v jediné vrstvě výpočtu, umožňující výpočet vztahů způsobem inspirovaným informačními procesními kapacitami biologických systémů.
Nová práce je nazvána Testování relačního porozumění v textem řízené generaci obrázků a pochází od Colina Conwella a Tomera D. Ullmana z Harvardského psychologického oddělení.
Mimo ranou kritiku
Komentář k „falešnému triku“ za realističností a integritou výstupu DALL-E 2, autoři uvádějí předchozí práce, které nalezly nedostatky v systémech generace obrázků stylu DALL-E.
V červnu tohoto roku, UoC Berkeley poznamenala potíže DALL-E s处理em odrazů a stínů; stejný měsíc, studie z Koreje prošetřovala „jedinečnost“ a originalitu výstupu stylu DALL-E 2 s kritickým okem; preliminární analýza obrázků DALL-E 2, krátce po spuštění, z NYU a University of Texas, nalezla různé problémy se složitostí a dalšími základními faktory v obrazech DALL-E 2; a minulý měsíc, společná práce mezi University of Illinois a MIT nabídla návrhy pro architektonická vylepšení takových systémů z hlediska složitosti.
Výzkumníci dále uvádějí, že osobnosti DALL-E, jako je Aditya Ramesh, přiznali problémy frameworku s vazbou, relativní velikostí, textem a dalšími výzvami.
Vývojáři za rivalem image syntézou systémem Imagen navrhli DrawBench, novou srovnávací systém, který měří přesnost obrázků napříč rámci s rozdílnými metrikami.
Místo toho autoři nové práce navrhují, že lepší výsledek by mohl být získán tím, že se lidské odhady – spíše než algoritmické metriky – postaví proti výsledným obrázkům, aby se stanovilo, kde leží slabiny, a co by se mohlo udělat, aby je zmírnilo.
Studie
K tomuto účelu se nová práce zakládá na psychologických principech a snaží se ustoupit od současné vlny zájmu v prompt inženýrství (což je ve skutečnosti přiznání k nedostatkům DALL-E 2, nebo jakéhokoli srovnatelného systému), aby prošetřila a potenciálně řešila omezení, která činí taková „pracovní kola“ nutná.
Práce uvádí:
‘Současná práce se zaměřuje na sadu 15 základních vztahů dříve popsáných, prozkoumaných nebo navržených v kognitivní, vývojové nebo lingvistické literatuře. Sada obsahuje jak prostorové vztahy (jako „X na Y“), tak i abstraktnější agentic vztahy (jako „X pomáhá Y“).
‘Podněty jsou záměrně jednoduché, bez atributové složitosti nebo elaborace. To znamená, že místo podnětu jako „osel a chobotnice hrají hru. Osel drží lano na jednom konci, chobotnice drží na druhém. Osel drží lano v ústech. Kočka skáče přes lano“, používáme „krabice na noži“.
‘Jednoduchost stále zachycuje širokou škálu vztahů z různých subdomén lidské psychologie a činí potenciální modelové selhání více nápadné a specifické.’
Pro svou studii autoři získali 169 účastníků z Prolific, všech z USA, s průměrným věkem 33 let, a 59% žen.
Účastníkům byly ukázány 18 obrázků uspořádaných do 3×6 mřížky s podnětem nahoře a upozorněním dole, které uvádělo, že všechny, některé nebo žádné obrázky mohly být generovány z zobrazeného podnětu, a byli požádáni, aby vybrali obrázky, které se domnívají, že jsou v tomto smyslu související.
Obrázky prezentované jednotlivcům byly založeny na lingvistické, vývojové a kognitivní literatuře, skládající se z 8 fyzických a 7 „agentic“ vztahů (což bude jasné za chvíli).
Fyzické vztahy
in, on, under, covering, near, occluded by, hanging over, a tied to.
Agentic vztahy
pushing, pulling, touching, hitting, kicking, helping, and hindering.
Všechny tyto vztahy byly získány z dříve zmíněných ne-CS oborů.
Dvanáct entit bylo takto odvozeno pro použití v podnětech, se šesti objekty a šesti agenty:
Objekty
krabice, válec, deka, miska, šálek, and nůž.
Agenti
muž, žena, dítě, robot, opice, and leguán.
(Výzkumníci přiznávají, že zahrnutí leguána, který není hlavní součástí suchého sociologického nebo psychologického výzkumu, bylo „malou odměnou“)
Pro každý vztah byly vytvořeny pět různých podnětů výběrem dvou entit pětkrát, což vedlo k 75 celkem podnětů, z nichž každý byl předložen DALL-E 2, a pro každý z nich byly použity počáteční 18 dodaných obrázků, bez jakýchkoli variací nebo druhých šancí.
Výsledky
Práce uvádí*:
‘Účastníci uváděli v průměru nízkou míru souhlasu mezi obrázky DALL-E 2 a podněty, které je generovaly, s průměrem 22,2 % [18,3, 26,6] napříč 75 rozdílnými podněty.
‘Agentic podněty, s průměrem 28,4 % [22,8, 34,2] napříč 35 podněty, generovaly vyšší souhlas než fyzické podněty, s průměrem 16,9 % [11,9, 23,0] napříč 40 podněty.’

Výsledky studie. Body v černé barvě označují všechny podněty, s každým bodem jako jednotlivým podnětem, a barva rozděluje, zda byl podnět subjektem agentic nebo fyzický (tj. objekt).
K porovnání rozdílu mezi lidským a algoritmickým vnímáním obrázků, výzkumníci provedli své renderování prostřednictvím open source ViT-L/14 CLIP-based frameworku. Průměrováním skórů nalezli „moderátní vztah“ mezi dvěma sadami výsledků, což je možná překvapivé, vzhledem k rozsahu, v jakém CLIP sám pomáhá generovat obrázky.

Výsledky srovnání CLIP (ViT-L/14) proti lidským odpovědím.
Výzkumníci navrhují, že další mechanismy v architektuře, možná v kombinaci s náhodným preponderancí (nebo nedostatkem) dat ve trénovacích datech, mohou být odpovědné za způsob, jakým CLIP může rozpoznat omezení DALL-E, aniž by mohl vždy něco udělat proti problému.
Autoři uzavírají, že DALL-E 2 má pouze nominální schopnost reprodukovat obrázky, které zahrnují relační porozumění, základní složku lidské inteligence, která se vyvíjí u nás velmi brzy.
‘Nápad, že systémy jako DALL-E 2 nemají kompozicionalitu, může být překvapující pro kohokoli, kdo viděl DALL-E 2’s ohromující odpovědi na podněty, jako je „karikatura baby daikon ředkvičky v tutu chůzi poodle“. Podněty, jako tyto, často generují rozumnou aproximaci kompozicionálního konceptu, se všemi částmi podnětu přítomnými a přítomnými na správných místech.
‘Kompozicionalita, nicméně, není pouze schopnost lepit věci вместе – i věci, které jste nikdy předtím neviděli společně. Kompozicionalita vyžaduje porozumění pravidlům, která spojují věci. Vztahy jsou taková pravidla.’
Člověk kousne T-Rex
Mínění Jako OpenAI přijímá větší počet uživatelů po nedávné beta monetizaci DALL-E 2, a od té doby, co je nyní nutné platit za většinu generací, a refundace nejsou k dispozici, mohou se nedostatky v relačním porozumění DALL-E 2 stát více zřetelnými, protože každá „neúspěšná“ спробa má finanční váhu, a refundace nejsou k dispozici.
Ti z nás, kteří dostali pozvánku trochu dříve, měli čas (a, až do nedávna, větší volnost hrát se systémem) pozorovat některé „vztahové chyby“, které DALL-E 2 může emitovat.
Například pro fanouška Jurassic Park je velmi obtížné získat dinosaura, aby pronásledoval osobu v DALL-E 2, i když koncept „pronásledování“ nezdá se být v cenzurním systému DALL-E 2, a i když dlouhá historie dinosaurů ve filmech by měla poskytnout dostatečné trénovací příklady (alespoň ve formě trailerů a propagačních snímků) pro toto jinak nemožné setkání druhů.

Typická odpověď DALL-E 2 na podnět „barevná fotografie T-Rexu, který pronásleduje muže po silnici“. Zdroj: DALL-E 2
Nalezl jsem, že obrázky výše jsou typické pro varianty podnětu „[dinosaurus] pronásleduje [člověk]“, a že žádná elaborace podnětu nemůže dostat T-Rex, aby skutečně splnil. V prvním a druhém snímku muž pronásleduje T-Rex; ve třetím se k němu blíží s nezájmem o bezpečnost; a ve čtvrtém snímku běží vedle něj. Napříč asi 10-15 pokusy o toto téma, nalezl jsem, že dinosaurus je podobně „odvrácen“.
Mohlo by to být, že jedinými trénovacími daty, které DALL-E 2 mohl přístup, byly v linii „člověk bojuje s dinosaurem“, z propagačních snímků starších filmů, jako je One Million Years B.C. (1966), a že slavný útěk Jeffa Goldbluma od krále predátorů je prostě outlier v této malé části dat.
* Mé převody inline citací autorů na odkazy.
Poprvé publikováno 4. srpna 2022.













{kind=link}