
Umělá inteligence
Jak by se mohla vyvinout stabilní difúze jako hlavní spotřebitelský produkt

Ironicky, Stabilní Diffusion, nový rámec pro syntézu obrazu s využitím umělé inteligence, který dobyl svět, není ani stabilní, ani ve skutečnosti „rozptýlený“ – alespoň ne zatím.
Celá škála možností systému je rozprostřena v proměnlivé směsici neustále se měnících nabídek od hrstky vývojářů, kteří si v rozmanitých diskusích na Discordu horečně vyměňují nejnovější informace a teorie – a drtivá většina instalačních postupů pro balíčky, které vytvářejí nebo upravují, má k „plug and play“ velmi daleko.
Spíše mají tendenci vyžadovat příkazový řádek resp BAT-řízený instalace přes GIT, Conda, Python, Miniconda a další nejnáročnější vývojové rámce – softwarové balíčky tak vzácné mezi běžnými zákazníky, že jejich instalace je často označeny od dodavatelů antivirových a antimalwarových produktů jako důkaz kompromitovaného hostitelského systému.

Pouze malý výběr fází v uličce, které v současné době vyžaduje standardní instalace Stable Diffusion. Mnoho distribucí také vyžaduje specifické verze Pythonu, které mohou kolidovat se stávajícími verzemi nainstalovanými na počítači uživatele – tomu se však lze vyhnout instalacemi založenými na Dockeru a do jisté míry i použitím prostředí Conda.
Vlákna zpráv v komunitách SFW a NSFW Stable Diffusion jsou zaplavena tipy a triky souvisejícími s hackováním skriptů Pythonu a standardními instalacemi, aby bylo možné zlepšit funkčnost nebo vyřešit časté chyby závislostí a řadu dalších problémů.
To nechává průměrného spotřebitele zajímat vytváření úžasných obrázků z textových výzev, do značné míry na milost a nemilost rostoucímu počtu monetizovaných webových rozhraní API, z nichž většina nabízí minimální počet bezplatných generací obrázků, než bude vyžadovat nákup tokenů.
Navíc téměř všechny tyto webové nabídky odmítají zobrazovat obsah NSFW (z něhož velká část se může týkat témat obecného zájmu, která nejsou pornografická, jako je například „válka“), což odlišuje Stable Diffusion od bowdlerizovaných služeb DALL-E 2 od OpenAI.
Photoshop pro stabilní difuzi
Zlákani úžasnými, pikantními nebo nadpozemskými obrázky, které denně zaplňují hashtag #stablediffusion na Twitteru, širší svět pravděpodobně čeká na... Photoshop pro stabilní difuzi – multiplatformní instalovatelná aplikace, která v sobě spojuje nejlepší a nejvýkonnější funkce architektury Stability.ai a také různé důmyslné inovace nově vznikající komunity vývojářů SD, bez plovoucích oken CLI, nejasných a neustále se měnících instalačních a aktualizačních rutin nebo chybějících funkcí.
To, co v současnosti máme ve většině schopnějších instalací, je různě elegantní webová stránka, na které se rozprostírá okno příkazového řádku bez těla a jejíž URL je port localhost:

Podobně jako aplikace pro syntézu řízené CLI, jako je FaceSwap a DeepFaceLab zaměřený na BAT, ukazuje „předinstalovaná“ instalace Stable Diffusion své kořeny v příkazovém řádku s rozhraním přístupným přes port localhost (viz horní část obrázku výše), který komunikuje s funkcí Stable Diffusion založenou na CLI.
Bezpochyby přichází efektivnější aplikace. Již existuje několik integrálních aplikací založených na Patreonu, které lze stáhnout, jako např GRisk si NMKD (viz obrázek níže) – ale žádný, který by zatím integroval celou řadu funkcí, které mohou nabídnout některé pokročilejší a méně dostupné implementace Stable Diffusion.

Rané balíčky Stable Diffusion založené na Patreonu, lehce „aplikované“. NMKD je první, který integruje výstup z CLI přímo do grafického rozhraní.
Pojďme se podívat, jak by mohla nakonec vypadat propracovanější a integrovanější implementace tohoto úžasného open source zázraku – a jakým výzvám by mohla čelit.
Právní aspekty plně financované komerční stabilní difúzní aplikace
Faktor NSFW
Zdrojový kód Stable Diffusion byl vydán pod extrémně tolerantní licence který nezakazuje komerční reimplementace a odvozená díla, která se ve velké míře staví ze zdrojového kódu.
Kromě výše uvedeného a rostoucího počtu sestavení Stable Diffusion založených na Patreonu, stejně jako rozsáhlého počtu aplikačních pluginů vyvíjených pro Obr, Kritě, Photoshop, GIMP, a Mixér (mimo jiné) neexistuje praktický důvod, proč by dobře financovaná společnost zabývající se vývojem softwaru nemohla vyvinout mnohem sofistikovanější a schopnější aplikaci Stable Diffusion. Z pohledu trhu existuje každý důvod se domnívat, že několik takových iniciativ již dobře probíhá.
Zde takové snahy okamžitě čelí dilematu, zda aplikace, stejně jako většina webových API pro Stable Diffusion, umožní nativní filtr NSFW Stable Diffusion (a fragment kódu), která se má vypnout.
„Pohřbení“ přepínače NSFW
Ačkoli licence Stability.ai s otevřeným zdrojovým kódem pro Stable Diffusion obsahuje široce interpretovatelný seznam aplikací, pro které může ne použít (pravděpodobně včetně pornografický obsah si hluboké zápasy), jediným způsobem, jak by prodejce mohl takové použití účinně zakázat, by bylo zkompilovat filtr NSFW do neprůhledného spustitelného souboru namísto parametru v souboru Python, nebo vynutit porovnání kontrolního součtu v souboru Python nebo DLL, který obsahuje direktivu NSFW, takže k vykreslení nemůže dojít, pokud uživatelé toto nastavení změní.
To by předpokládanou žádost „neutralizovalo“ podobně jako DALL-E 2 aktuálně je, což snižuje jeho komerční atraktivitu. Také by se nevyhnutelně v torrentové/hackerské komunitě pravděpodobně objevily dekompilované „upravené“ verze těchto komponent (buď původní běhové prvky Pythonu, nebo kompilované soubory DLL, jaké se nyní používají v řadě nástrojů Topaz pro vylepšení obrazu s umělou inteligencí), které by tato omezení odemkly, jednoduše nahrazením překážejících prvků a negací veškerých požadavků na kontrolní součet.
Nakonec se dodavatel může rozhodnout jednoduše zopakovat varování Stability.ai před zneužitím, které charakterizuje první spuštění mnoha současných distribucí Stable Diffusion.
Malí vývojáři s otevřeným zdrojovým kódem, kteří v současnosti tímto způsobem používají příležitostná prohlášení o vyloučení odpovědnosti, však nemají co ztratit ve srovnání se softwarovou společností, která investovala značné množství času a peněz do plnohodnotného a dostupného Stable Diffusion – což vyžaduje hlubší úvahu.
Deepfake odpovědnost
Jak máme nedávno poznamenalDatabáze LAION-aesthetics, která je součástí 4.2 miliardy obrázků, na nichž byly trénovány modely Stable Diffusion, obsahuje velké množství obrázků celebrit, což uživatelům umožňuje efektivně vytvářet deepfaky, včetně deepfake porna s celebritami.

Z našeho nedávného článku vyplynuly ze Stable Diffusion čtyři fáze Jennifer Connelly za čtyři desetiletí její kariéry.
Toto je samostatná a spornější otázka než generování (obvykle) legálního „abstraktního“ porna, které nezobrazuje „skutečné“ lidi (ačkoli takové obrázky jsou odvozeny z několika skutečných fotografií ve školicích materiálech).
Vzhledem k tomu, že stále více států a zemí USA vyvíjí nebo zavádí zákony proti deepfake pornografii, schopnost Stable Diffusion vytvářet pornografický materiál s celebritami by mohla znamenat, že komerční aplikace, která není zcela cenzurována (tj. která dokáže vytvářet pornografický materiál), by stále mohla potřebovat určitou schopnost filtrovat vnímané tváře celebrit.
Jednou z metod by bylo poskytnout vestavěný „černý seznam“ výrazů, které nebudou v uživatelském výzvě akceptovány, a které se týkají jmen celebrit a fiktivních postav, s nimiž mohou být spojovány. Pravděpodobně by bylo nutné taková nastavení zavést ve více jazycích než jen v angličtině, protože původní data obsahují i jiné jazyky. Dalším přístupem by mohlo být začlenění systémů pro rozpoznávání celebrit, jako jsou ty vyvinuté společností Clarifai.
Pro výrobce softwaru může být nutné začlenit takové metody, možná zpočátku vypnuté, což může pomoci zabránit tomu, aby plnohodnotná samostatná aplikace Stable Diffusion generovala tváře celebrit, dokud nebude přijata nová legislativa, která by mohla učinit takovou funkci nezákonnou.
Opět však platí, že takovou funkcionalitu by zainteresované strany nevyhnutelně mohly dekompilovat a zvrátit; výrobce softwaru by však v takovém případě mohl tvrdit, že jde v podstatě o nepovolený vandalismus – pokud tento druh reverzního inženýrství nebude příliš usnadněn.
Funkce, které by mohly být zahrnuty
Základní funkčnost v jakékoli distribuci Stable Diffusion by se dala očekávat od jakékoli dobře financované komerční aplikace. Patří mezi ně schopnost používat textové výzvy ke generování vhodných obrázků (převod textu na obrázek); schopnost používat náčrtky nebo jiné obrázky jako vodítko pro nově generované obrázky (obraz od obrazu); prostředky k nastavení „imaginativní“ úrovně systému; způsob, jak kompromisně zvýšit dobu vykreslování s kvalitou; a další „základní prvky“, jako je volitelná automatická archivace obrázků/promptu a rutinní volitelné zvyšování rozlišení pomocí RealESRGANa alespoň základní „korekci obličeje“ s GFPGAN or CodeFormer.
To je docela „základní instalace“. Pojďme se podívat na některé pokročilejší funkce, které se v současné době vyvíjejí nebo rozšiřují a které by mohly být začleněny do plnohodnotné „tradiční“ aplikace Stable Diffusion.
Stochastické zmrazení
Jen pokud ty znovu použít semeno z předchozího úspěšného renderu je strašně těžké přimět Stable Diffusion, aby přesně opakovala transformaci, pokud jakoukoli část výzvy nebo se zdrojový obrázek (nebo obojí) změní pro následné vykreslení.
To je problém, pokud chcete použít EbSynth vložit transformace ze Stabilní difúze do reálného videa časově koherentním způsobem – ačkoli tato technika může být velmi efektivní pro jednoduché záběry hlavy a ramen:

Omezený pohyb může z EbSynth udělat efektivní médium pro přeměnu transformací Stable Diffusion na realistické video. Zdroj: https://streamable.com/u0pgzd
EbSynth funguje tak, že extrapoluje malý výběr „změněných“ klíčových snímků do videa, které bylo vykresleno do série obrazových souborů (a které lze později znovu sestavit do videa).

V tomto příkladu z webu EbSynth byla malá hrstka snímků z videa namalována uměleckým způsobem. EbSynth používá tyto snímky jako průvodce stylem, aby podobně upravil celé video tak, aby odpovídalo vymalovanému stylu. Zdroj: https://www.youtube.com/embed/eghGQtQhY38
V níže uvedeném příkladu, kde se (skutečná) blondýnka instruktorka jógy vlevo téměř vůbec nepohne, má Stable Diffusion stále potíže s udržením konzistentního obličeje, protože tři obrazy transformované jako „klíčové snímky“ nejsou zcela identické, i když všechny sdílejí stejnou číselnou hodnotu.

Zde, dokonce i se stejnou výzvou a zárodkem ve všech třech transformacích a velmi málo změn mezi zdrojovými snímky, se svaly těla liší velikostí a tvarem, ale co je důležitější, obličej je nekonzistentní, což brání časové konzistenci v potenciálním vykreslení EbSynth.
Ačkoli je níže uvedené video SD/EbSynth velmi nápadité, kde se prsty uživatele proměnily v (v uvedeném pořadí) chodící pár nohavic v kalhotách a kachnu, nekonzistence kalhot typicky znázorňuje problém, který má Stable Diffusion s udržováním konzistence napříč různými klíčovými snímky, a to i v případě, že jsou si zdrojové snímky podobné a seed je konzistentní.

Prsty muže se pomocí Stable Diffusion a EbSynth promění v chodícího muže a kachnu. Zdroj: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
Uživatel, který vytvořil toto video komentáři že kachní transformace, pravděpodobně účinnější z těchto dvou, i když méně nápadná a originální, vyžadovala pouze jeden transformovaný klíčový snímek, zatímco bylo nutné vykreslit 50 snímků Stable Diffusion, aby se vytvořily vycházkové kalhoty, které vykazují více času. nedůslednost. Uživatel také poznamenal, že dosažení konzistence pro každý z 50 klíčových snímků trvalo pět pokusů.
Proto by bylo velkým přínosem pro skutečně komplexní aplikaci Stable Diffusion poskytovat funkcionalitu, která v maximální míře zachovává charakteristiky napříč klíčovými snímky.
Jednou z možností je, aby aplikace umožnila uživateli „zmrazit“ stochastické kódování transformace v každém snímku, čehož lze v současnosti dosáhnout pouze ruční úpravou zdrojového kódu. Jak ukazuje níže uvedený příklad, napomáhá to časové konzistenci, i když to problém rozhodně neřeší:

Jeden uživatel Redditu přeměnil záběry z webové kamery na různé slavné lidi nejen tím, že zachoval semeno (což může udělat jakákoli implementace Stable Diffusion), ale zajistil, že parametr stochastic_encode() byl v každé transformaci identický. Toho bylo dosaženo úpravou kódu, ale mohl se snadno stát uživatelsky dostupným přepínačem. Je však zřejmé, že neřeší všechny časové problémy. Zdroj: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
Cloudová textová inverze
Lepším řešením pro vyvolání časově konzistentních postav a objektů je jejich „upečení“ do Textová inverze – soubor o velikosti 5 kB, který lze trénovat během několika hodin na základě pouhých pěti anotovaných obrázků, které pak může vyvolat speciální '*' pohotový, umožňující například trvalý výskyt nových postav pro zahrnutí do vyprávění.

Obrázky spojené s příslušnými značkami lze převést na diskrétní entity pomocí textové inverze a shromáždit je bez dvojznačnosti a ve správném kontextu a stylu pomocí speciálních tokenových slov. Zdroj: https://huggingface.co/docs/diffusers/training/text_inversion
Textové inverze jsou doplňkové soubory k velmi rozsáhlému a plně trénovanému modelu, který používá Stable Diffusion, a jsou efektivně „včleněny“ do procesu vyvolání/promptingu, aby mohly účastnit se ve scénách odvozených z modelu a těžit z obrovské databáze znalostí modelu o objektech, stylech, prostředích a interakcích.
Nicméně, ačkoli trénování textové inverze netrvá dlouho, vyžaduje velké množství VRAM; podle různých aktuálních návodů někde mezi 12, 20 a dokonce 40 GB.
Protože je nepravděpodobné, že by většina příležitostných uživatelů měla k dispozici tento druh GPU heftu, již se objevují cloudové služby, které tuto operaci zvládnou, včetně verze Hugging Face. I když existují Implementace Google Colab které mohou vytvářet textové inverze pro Stable Diffusion, požadované VRAM a časové požadavky to mohou zkomplikovat pro uživatele Colab na volné úrovni.
Pro potenciálně plnohodnotnou a dobře investovanou (instalovanou) aplikaci Stable Diffusion se přenos tohoto náročného úkolu na cloudové servery společnosti jeví jako zřejmá strategie monetizace (za předpokladu, že levná nebo bezplatná aplikace Stable Diffusion je prostoupena takovou nesvobodnou funkcionalitou, což se zdá pravděpodobné u mnoha možných aplikací, které z této technologie v příštích 6-9 měsících vyjdou).
Navíc by poměrně složitý proces anotace a formátování odeslaných obrázků a textu mohl těžit z automatizace v integrovaném prostředí. Potenciální „návykový faktor“ vytváření jedinečných prvků, které mohou prozkoumávat a interagovat s rozsáhlými světy Stable Diffusion, by se mohl zdát potenciálně kompulzivní, a to jak pro běžné nadšence, tak pro mladší uživatele.
Všestranné rychlé vážení
Existuje mnoho současných implementací, které umožňují uživateli přiřadit větší důraz části dlouhé textové výzvy, ale instrumentálnost se mezi nimi značně liší a je často neohrabaná nebo neintuitivní.
Velmi oblíbená Stable Diffusion vidlice od AUTOMATIC1111, například může snížit nebo zvýšit hodnotu slova výzvy tak, že jej uzavře do jednoduchých nebo více závorek (pro snížení důrazu) nebo hranatých závorek pro větší důraz.

Hranaté závorky a/nebo kulaté závorky mohou v této verzi vah promptů Stabilní difúze proměnit vaši snídani, ale v každém případě je to noční můra s cholesterolem.
Jiné iterace Stable Diffusion používají pro zdůraznění vykřičníky, zatímco nejuniverzálnější umožňují uživatelům přiřadit váhu každému slovu ve výzvě prostřednictvím GUI.
Systém by měl také umožňovat negativní promptní váhy – nejen pro fanoušci hororu, ale proto, že v latentním prostoru Stabilní difuze může být méně alarmujících a více poučných záhad, než kolik dokáže vyjádřit naše omezené používání jazyka.
Malba
Krátce po senzačním open-sourcingu Stable Diffusion se OpenAI snažila – z velké části marně – získat zpět část svého DALL-E 2 hromu. oznamovat „outpainting“, který umožňuje uživateli rozšířit obraz za jeho hranice pomocí sémantické logiky a vizuální koherence.
Od té doby tomu tak přirozeně bylo realizován v různých formách pro stabilní difúzi, stejně jako v Kritěa určitě by měl být zahrnut do komplexní verze Stable Diffusion ve stylu Photoshopu.
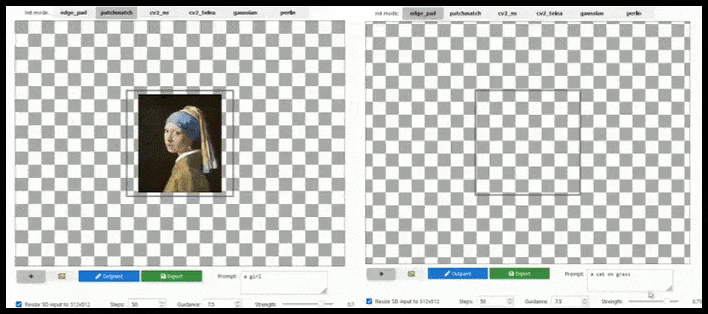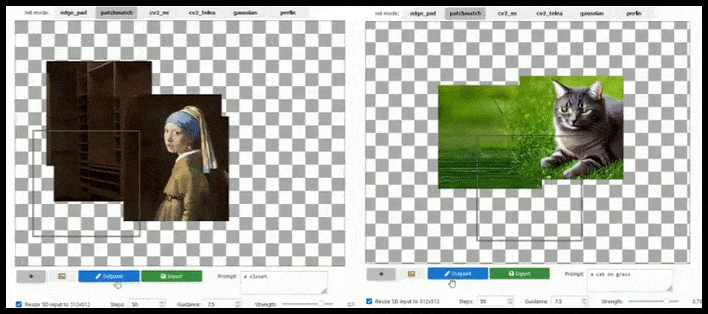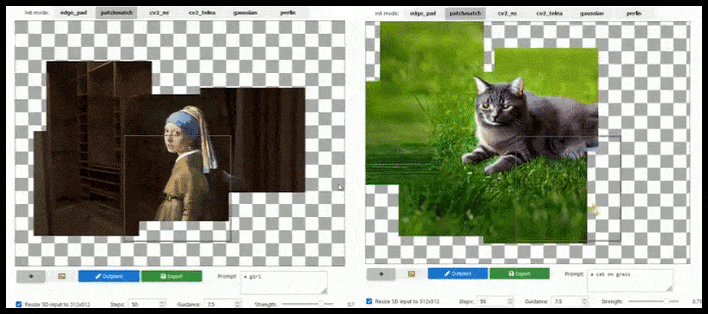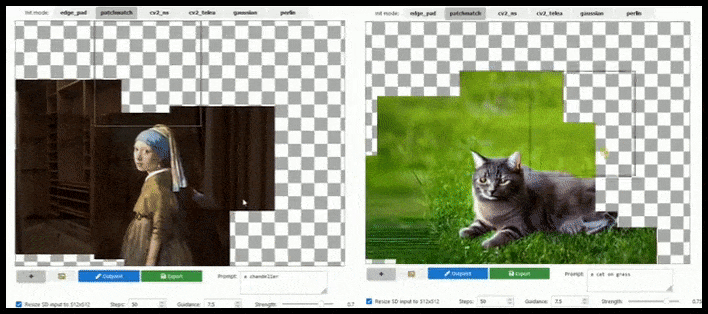
Rozšíření založené na dlaždicích může rozšířit standardní render 512 × 512 téměř nekonečně, pokud to výzvy, existující obrázek a sémantická logika umožňují. Zdroj: https://github.com/lkwq007/stablediffusion-infinity
Protože je Stabilní difúze trénována na obrázcích o rozměrech 512x512px (a z řady dalších důvodů), často odřezává hlavy (nebo jiné důležité části těla) lidských objektů, a to i v případech, kdy výzva jasně uvádí „důraz na hlavu“ atd.

Typické příklady „dekapitace“ ze stabilní difúze; ale přemalování by mohlo George vrátit do obrazu.
Jakákoli implementace překreslování typu znázorněného na animovaném obrázku výše (který je založen výhradně na unixových knihovnách, ale měl by být schopen replikace ve Windows) by měl být také použit jako náprava na jedno kliknutí/výzvu.
V současné době řada uživatelů rozšiřuje plátno „dekapitovaných“ vyobrazení směrem nahoru, zhruba vyplňuje oblast hlavy a pomocí img2img dokončuje nepovedený render.
Efektivní maskování, které rozumí kontextu
Maskování může být v Stable Diffusion v závislosti na dané forku nebo verzi velmi problematická záležitost. Často se stává, že i když je vůbec možné nakreslit soudržnou masku, zadaná oblast se nakonec vymaluje obsahem, který nezohledňuje celý kontext obrázku.
Při jedné příležitosti jsem zamaskoval rohovky obrázku obličeje a poskytl výzvu 'modré oči' jako maska namalovaná na plátně – jen abych zjistil, že se dívám skrz dvě vystřižené lidské oči na vzdálený obraz nadpozemsky vypadajícího vlka. Asi mám štěstí, že to nebyl Frank Sinatra.
Sémantické úpravy jsou také možné pomocí identifikaci hluku která vytvořila obraz na prvním místě, což uživateli umožňuje řešit konkrétní strukturální prvky v renderu, aniž by zasahovalo do zbytku obrazu:

Změna jednoho prvku na obrázku bez tradičního maskování a bez změny sousedního obsahu, identifikací šumu, který jako první vytvořil obrázek, a adresováním jeho částí, které přispěly k cílové oblasti. Zdroj: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Tato metoda je založena na Vzorkovač K-Diffusion.
Sémantické filtry pro fyziologické nesmysly
Jak jsme již zmínili, Stabilní difúze může často přidávat nebo odebírat končetiny, a to především kvůli problémům s daty a nedostatkům v anotacích, které doprovázejí obrázky, na kterých byla metoda trénována.

Stejně jako ten zbloudilý kluk, co na skupinové fotce ve škole vyplazil jazyk, ani biologické zvěrstva Stable Diffusion nejsou vždy hned zřejmá a možná jste si své nejnovější mistrovské dílo umělé inteligence stihli zveřejnit na Instagramu, než jste si všimli přidaných rukou nebo roztavených končetin.
Je tak obtížné opravit tyto druhy chyb, že by bylo užitečné, kdyby aplikace Stable Diffusion v plné velikosti obsahovala nějaký druh anatomického rozpoznávacího systému, který by využíval sémantickou segmentaci k výpočtu, zda příchozí obrázek vykazuje vážné anatomické nedostatky (jako na obrázku výše). ) a před předložením uživateli jej zahodí ve prospěch nového vykreslení.

Samozřejmě můžete chtít vykreslit bohyni Kali nebo doktora Chobotnice nebo dokonce zachránit nedotčenou část obrázku postiženého končetinami, takže tato funkce by měla být volitelným přepínačem.
Pokud by uživatelé mohli tolerovat aspekt telemetrie, taková selhání by mohla být dokonce přenášena anonymně v kolektivním úsilí federativního učení, které může budoucím modelům pomoci zlepšit jejich chápání anatomické logiky.
Automatické vylepšení obličeje na bázi LAION
Jak jsem poznamenal ve svém předchozí pohled Ze tří věcí, které by Stable Diffusion mohl v budoucnu řešit, by nemělo být ponecháno pouze na jakékoli verzi GFPGAN, aby se pokoušela „vylepšit“ vykreslené obličeje v prvních renderech.
„Vylepšení“ GFPGANu jsou strašně generická, často podkopávají identitu zobrazené osoby a působí výhradně na obličej, který byl obvykle vykreslen špatně, protože mu nebylo věnováno více času na zpracování ani pozornosti než jakékoli jiné části obrazu.
Profesionální program pro Stable Diffusion by proto měl být schopen rozpoznat obličej (se standardní a relativně lehkou knihovnou, jako je YOLO), využít plný výkon GPU k jeho opětovnému vykreslení a buď smíchat vylepšený obličej s původním renderem v plném kontextu, nebo jej uložit samostatně pro ruční opětovné složení. V současné době je to poměrně „praktická“ operace.
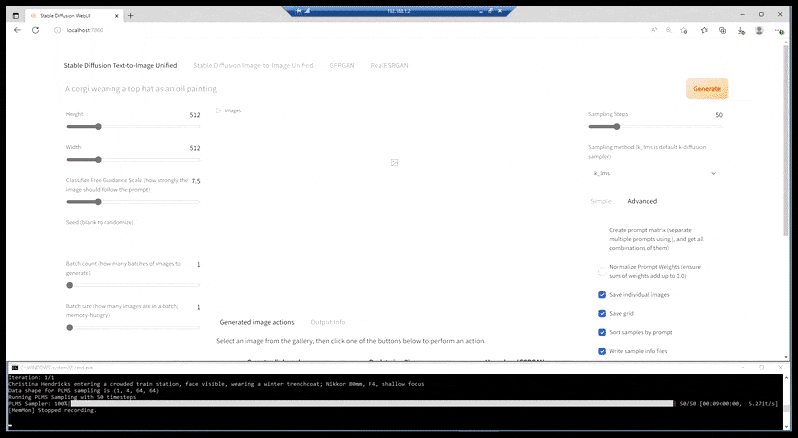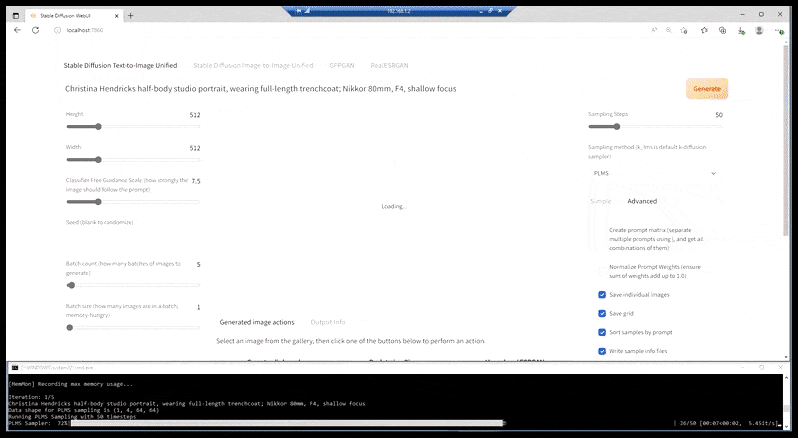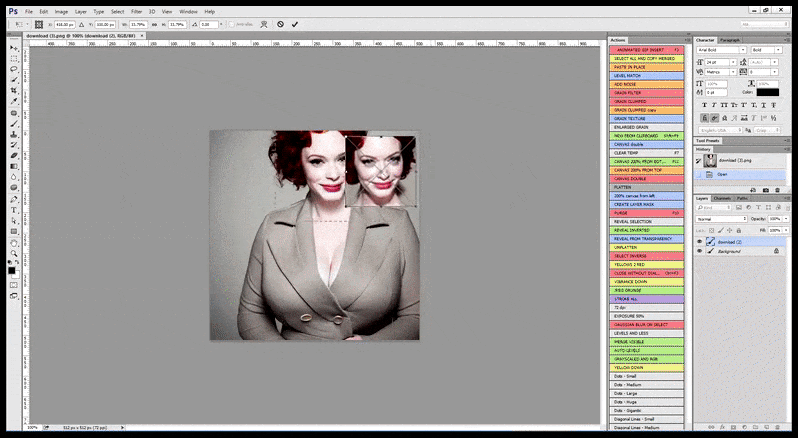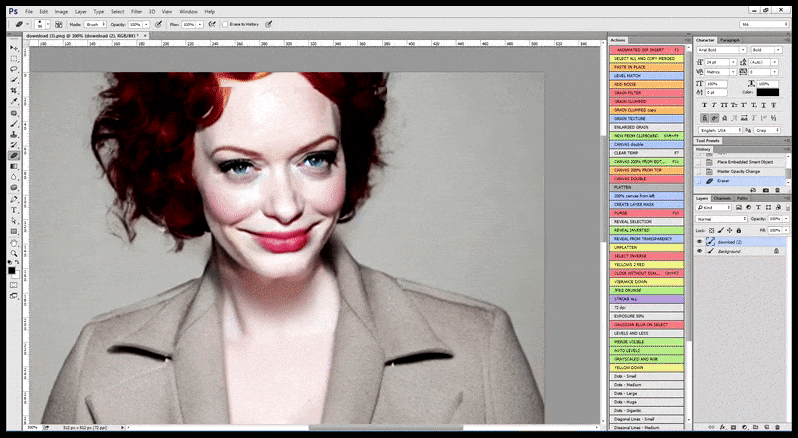
V případech, kdy byl Stable Diffusion natrénován na dostatečném počtu obrázků celebrity, je možné zaměřit celou kapacitu GPU na následné vykreslení pouze obličeje vykresleného obrázku, což je obvykle znatelné zlepšení – a na rozdíl od GFPGAN čerpá informace z dat vytrénovaných pomocí LAION, spíše než aby pouze upravoval vykreslené pixely.
Vyhledávání LAION v aplikaci
Od doby, kdy si uživatelé začali uvědomovat, že vyhledávání konceptů, lidí a témat v databázi LAION by mohlo pomoci lépe využít Stable Diffusion, bylo vytvořeno několik online průzkumníků LAION, včetně haveibeentrained.com.

Vyhledávací funkce na haveibeentrained.com umožňuje uživatelům prozkoumávat obrázky, které pohánějí systém Stable Diffusion, a zjišťovat, zda objekty, osoby nebo nápady, které by mohli ze systému vyvolat, pravděpodobně byly do něj natrénovány. Takové systémy jsou také užitečné pro objevování sousedících entit, jako je například způsob seskupení celebrit nebo „další nápad“, který navazuje na ten aktuální. Zdroj: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Ačkoli takové webové databáze často odhalují některé značky, které obrázky doprovázejí, proces zobecnění který se odehrává během trénování modelu, znamená, že je nepravděpodobné, že by mohl být nějaký konkrétní obrázek vyvolán pomocí jeho tagu jako výzvy.
Kromě toho odstranění „stop slova“ a praxe stemmingu a lemmatizace ve zpracování přirozeného jazyka znamená, že mnoho zobrazených frází bylo rozděleno nebo vynecháno předtím, než byly trénovány na stabilní difúzi.
Způsob, jakým se estetické seskupení v těchto rozhraních propojují, však může koncového uživatele hodně naučit o logice (nebo pravděpodobně o „osobnosti“) Stabilní difúze a ukázat se jako pomůcka pro lepší tvorbu obrazu.
Proč investovat do čističky vzduchu?
Existuje mnoho dalších funkcí, které bych rád viděl v plně nativní desktopové implementaci Stable Diffusion, jako je nativní analýza obrazu založená na CLIP, která obrací standardní proces Stable Diffusion a umožňuje uživateli vyvolat fráze a slova, která by systém přirozeně spojoval se zdrojovým obrázkem nebo renderem.
Navíc by bylo vítaným doplňkem skutečné škálování založené na dlaždicích, protože ESRGAN je téměř stejně neomalený nástroj jako GFPGAN. Naštěstí plány na integraci txt2imghd implementací GOBIG se to rychle stává realitou napříč distribucemi a zdá se, že je to jasná volba pro desktopovou iteraci.
Některé další oblíbené požadavky z komunit Discord mě zajímají méně, například integrované slovníky výzev a použitelné seznamy umělců a stylů, i když logickým doplňkem by se zdál zápisník v aplikaci nebo přizpůsobitelný lexikon frází.
Stejně tak současná omezení animace zaměřené na člověka ve Stable Diffusion, i když byla zahájena CogVideo a různými dalšími projekty, zůstává neuvěřitelně rodící se a vydána na milost a nemilost předchozímu výzkumu dočasných priorit týkajících se autentického lidského pohybu.
Prozatím je Stable Diffusion video striktní psychedelic, ačkoli může mít mnohem světlejší blízkou budoucnost v deepfake loutkářství, prostřednictvím EbSynth a dalších relativně začínajících iniciativ převodu textu na video (a stojí za zmínku nedostatek syntetizovaných nebo „změněných“ lidí v Runwayově nejnovější propagační video).
Další cennou funkcí by bylo transparentní propouštění z Photoshopu, které je mimo jiné v editoru textur Cinema4D již dávno zavedeno. Díky tomu lze snadno přesouvat obrázky mezi aplikacemi a každou aplikaci používat k provádění transformací, ve kterých vyniká.
A konečně, a to je možná nejdůležitější, úplný desktopový program Stable Diffusion by měl být schopen nejen snadno přepínat mezi kontrolními body (tj. verzemi základního modelu, který pohání systém), ale měl by být také schopen aktualizovat na zakázku vytvořené textové inverze, které fungovaly s předchozími oficiálními verzemi modelu, ale jinak mohou být porušeny pozdějšími verzemi modelu (jak vývojáři na oficiálním Discordu naznačili, že by tomu tak mohlo být).
Je ironií, že organizace, která má nejlepší pozici pro vytvoření tak výkonné a integrované matice nástrojů pro Stable Diffusion, Adobe, se tak silně spojila s Iniciativa pro autenticitu obsahu že by se to mohlo jevit jako zpětný PR krok společnosti – pokud by to ovšem neochromilo generativní schopnosti Stable Diffusion stejně důkladně, jako to udělala OpenAI s DALL-E 2, a místo toho by to prezentovalo jako přirozený vývoj jejích značných podílů v oblasti fotobanky.
Poprvé publikováno 15. září 2022.











