
Andersonův úhel
Metoda forenzních dat pro novou generaci Deepfakes

Ačkoli se deepfaking soukromých osob stal a rostoucí obavy veřejnosti a stále více je zakázáno v různých regionech, skutečně prokázat, že uživatelsky vytvořený model – například model umožňující porno pomsty – byl speciálně trénován na obrázcích konkrétní osoby, zůstává extrémně náročné.
Abychom uvedli problém do kontextu: klíčovým prvkem deepfake útoku je nepravdivé tvrzení, že obrázek nebo video zobrazuje konkrétní osobu. Prosté prohlášení, že někdo ve videu je identita #A, spíše než jen podobný dost na to, aby způsobil škodua v tomto scénáři není nutná žádná AI.
Pokud však útočník generuje obrázky nebo videa AI pomocí modelů natrénovaných na datech skutečných osob, sociální média a systémy pro rozpoznávání obličejů vyhledávačů automaticky propojí falešný obsah s obětí – aniž by vyžadovala jména v příspěvcích nebo metadatech. Spojení zajišťují samotné vizuály generované AI.
Čím zřetelnější je vzhled osoby, tím nevyhnutelnější se to stává, dokud se vymyšlený obsah neobjeví ve vyhledávání obrázků a nakonec dosáhne oběti.
Z očí do očí
Nejběžnějším způsobem šíření modelů zaměřených na identitu je v současnosti průchozí Adaptace nízkého hodnocení (LoRA), kde uživatel trénuje malý počet snímků po dobu několika hodin proti hmotnosti mnohem většího modelu základů, jako je např. Stabilní difúze (většinou u statických obrázků) popř Hunyuan Video, pro deepfakes videa.
Nejběžnější cíle LoRA, včetně nové plemeno z video-založených LoRA, jsou ženské celebrity, jejichž sláva je vystavuje tomuto druhu zacházení s menší veřejnou kritikou než v případě „neznámých“ obětí, a to kvůli předpokladu, že na taková odvozená díla se vztahuje „fair use“ (alespoň v USA a Evropě).

Ženské celebrity dominují seznamům LoRA a Dreambooth na portálu civit.ai. Nejpopulárnější taková LoRA má v současné době více než 66,000 XNUMX stažení, což je značné vzhledem k tomu, že toto používání AI zůstává považováno za „okrajovou“ činnost.
Neexistuje žádné takové veřejné fórum pro oběti deepfakingu, které nepatří mezi celebrity, které se v médiích vynoří pouze tehdy, když dojde k trestnímu stíhání, nebo se oběti vyjádří v populárních médiích.
V obou scénářích však modely použité k falšování cílových identit „destilovaly“ svá trénovací data tak úplně do latentní prostor modelu, že je obtížné identifikovat použité zdrojové obrázky.
Je-li to byly To by umožnilo stíhání těch, kteří sdílejí LoRA, protože to nejen prokazuje záměr hluboce předstírat konkrétní identitu (tj. identitu konkrétní „neznámé“ osoby, i když je pachatel během procesu pomluvy nikdy nejmenuje), ale také vystavuje uživatele, který video nahrál, případným poplatkům za porušení autorských práv.
Ten by byl užitečný v jurisdikcích, kde právní regulace technologií deepfaking chybí nebo zaostává.
Přeexponované
Cílem trénování základního modelu, jako je multigigabajtový základní model, který by si uživatel mohl stáhnout z Hugging Face, je, aby se model stal dobřeobecněa tažný. To zahrnuje trénování na dostatečném počtu různých snímků as příslušným nastavením a ukončení trénování před tím, než model „přepasuje“ na data.
An přetažený model viděl data během tréninkového procesu tolikrát (nadměrně), že bude mít tendenci reprodukovat obrázky, které jsou velmi podobné, a tím odhalit zdroj tréninkových dat.

Identita „Ann Graham Lotz“ může být téměř dokonale reprodukována v modelu Stable Diffusion V1.5. Rekonstrukce je téměř totožná s trénovacími daty (vlevo na obrázku výše). Zdroj: https://arxiv.org/pdf/2301.13188
Modely s přebytečnou výbavou však jejich tvůrci obecně spíše vyřazují, než distribuují, protože jsou v každém případě nevhodné pro daný účel. Jedná se tedy o nepravděpodobný forenzní „neočekávaný“. Princip každopádně platí spíše pro nákladná a velkoobjemová školení základových modelů, kde více verzí stejného obrázku, který se vloudil do obrovské zdrojové datové sady, může usnadnit vyvolání určitých tréninkových obrázků (viz obrázek a příklad výše).
V případě modelů LoRA a Dreambooth je to trochu jinak (i když Dreambooth vyšel z módy kvůli velkým velikostem souborů). Zde uživatel vybere velmi omezený počet různých snímků předmětu a použije je k trénování LoRA.

Vlevo výstup z Hunyuan Video LoRA. Vpravo údaje, které umožnily podobnost (obrázky použité se svolením zobrazené osoby).
LoRA bude mít často natrénované spouštěcí slovo, jako např [jméno celebrity]. Velmi často se však specificky vyškolený subjekt objeví v generovaném výstupu i bez takových výzev, protože i dobře vyvážená (tj. nepřepasovaná) LoRA je poněkud „fixovaná“ na materiálu, na kterém byla trénována, a bude mít tendenci jej zahrnout do jakéhokoli výstupu.
Tato predispozice v kombinaci s omezeným počtem snímků, které jsou optimální pro soubor dat LoRA, vystavuje model forenzní analýze, jak uvidíme.
Odmaskování dat
Těmito záležitostmi se zabývá nový dokument z Dánska, který nabízí metodologii pro identifikaci zdrojových obrázků (nebo skupin zdrojových obrázků) v černé skříňce. Útok na odvození členství (MIA). Tato technika alespoň zčásti zahrnuje použití vlastních modelů, které jsou navrženy tak, aby pomohly odhalit zdrojová data generováním jejich vlastních „deepfakes“:

Příklady „falešných“ obrázků generovaných novým přístupem na stále se zvyšujících úrovních navádění bez klasifikátorů (CFG) až do bodu zničení. Zdroj: https://arxiv.org/pdf/2502.11619
Ačkoli práceS názvem Útoky na odvození členství pro snímky obličeje proti jemně vyladěným modelům latentní difúze, je nejzajímavějším příspěvkem do literatury týkající se tohoto konkrétního tématu, je to také nepřístupný a stručně napsaný článek, který vyžaduje značné dekódování. Proto zde pokryjeme alespoň základní principy projektu a výběr dosažených výsledků.
Ve skutečnosti, pokud někdo doladí model umělé inteligence na vašem obličeji, metoda autorů to může dokázat hledáním zřejmých známek zapamatování v obrázcích generovaných modelem.
V první řadě je cílový model umělé inteligence doladěn na datové sadě obrázků obličejů, takže je pravděpodobnější, že bude ve svých výstupech reprodukovat detaily z těchto obrázků. Následně je trénován režim útoku klasifikátoru pomocí obrázků generovaných umělou inteligencí z cílového modelu jako „pozitivních“ (podezřelí členové trénovací sady) a dalších obrázků z jiné datové sady jako „negativních“ (nečlenové).
Tím, že se naučí jemné rozdíly mezi těmito skupinami, dokáže model útoku předpovědět, zda daný obrázek byl součástí původního dolaďovacího souboru dat.
Útok je nejúčinnější v případech, kdy byl model AI značně vyladěn, což znamená, že čím více je model specializovaný, tím snazší je zjistit, zda byly použity určité obrázky. To obecně platí pro LoRA určené k obnovení celebrit nebo soukromých osob.
Autoři také zjistili, že přidání viditelných vodoznaků do tréninkových obrázků stále usnadňuje detekci – i když skryté vodoznaky tolik nepomáhají.
Působivé je, že přístup je testován v prostředí black-box, což znamená, že funguje bez přístupu k interním detailům modelu, pouze k jeho výstupům.
Jak autoři připouštějí, metoda, ke které se dospělo, je výpočetně náročná; hodnota této práce je však v tom, že naznačuje směr dalšího výzkumu a dokazuje, že data lze realisticky extrahovat s přijatelnou tolerancí; proto, vzhledem ke své klíčové povaze, nemusí v této fázi běžet na chytrém telefonu.
Metoda/data
Ve studii bylo použito několik datových sad z Technické univerzity v Dánsku (DTU, hostitelské instituce pro tři výzkumníky, kteří se zabývají touto prací), a to pro doladění cílového modelu a pro trénování a testování útočného režimu.
Použité datové sady byly odvozeny z Orbit DTU:
DseenDTU Základní sada obrázků.
DDTU Obrázky seškrábané z DTU Orbit.
DseenDTU Oddíl DDTU používaný k doladění cílového modelu.
DunseenDTU Oddíl DDTU, který nebyl použit k doladění žádného modelu generování obrazu a místo toho byl použit k testování nebo trénování modelu útoku.
wmDseenDTU Oddíl DDTU s viditelnými vodoznaky používaný k doladění cílového modelu.
hwmDseenDTU Oddíl DDTU se skrytými vodoznaky používaný k doladění cílového modelu.
DgenDTU Obrázky generované a Model latentní difúze (LDM), který byl jemně doladěn na obrazové sadě DseenDTU.
Datové sady používané k doladění cílového modelu se skládají z párů obrázek-text s titulkem BLIP titulkovací model (možná ne náhodou jeden z nejoblíbenějších necenzurovaných modelů v neformální komunitě umělé inteligence).
BLIP byl nastaven tak, aby předcházel frázi 'portrétní snímek DTU' ke každému popisu.
Kromě toho bylo v testech použito několik datových sad z Aalborgské univerzity (AAU), všechny odvozené z Korpus AU VBN:
DAAU Obrázky seškrábané z AAU vbn.
DseenAAU Rozdělení DAAU používané k doladění cílového modelu.
DunseenAAU Oddíl DAAU, který se nepoužívá k doladění jakéhokoli modelu generování obrazu, ale spíše se používá k testování nebo trénování modelu útoku.
DgenAAU Obrázky generované LDM jemně vyladěné na sadě obrázků DseenAAU.
Ekvivalent k dřívějším sadám, fráze 'aau portrét' byl použit. To zajistilo, že všechny štítky v datové sadě DTU budou odpovídat formátu 'portrétní snímek (…) z DTU', posílení základních charakteristik datové sady během jemného ladění.
Zkoušky
Bylo provedeno několik experimentů, aby se vyhodnotilo, jak dobře si útoky na odvození členství vedly proti cílovému modelu. Každý test měl za cíl zjistit, zda bylo možné provést úspěšný útok v rámci schématu zobrazeného níže, kde je cílový model jemně doladěn na obrazové datové sadě, která byla získána bez oprávnění.

Schéma pro přístup.
S jemně vyladěným modelem dotazovaným pro generování výstupních obrázků jsou tyto obrázky použity jako pozitivní příklady pro trénování modelu útoku, zatímco další nesouvisející obrázky jsou zahrnuty jako negativní příklady.
Model útoku je trénován pomocí učení pod dohledem a poté se testuje na nových snímcích, aby se zjistilo, zda byly původně součástí datové sady použité k doladění cílového modelu. Pro vyhodnocení přesnosti útoku je 15 % testovacích dat odložit pro validaci.
Vzhledem k tomu, že cílový model je doladěn na známé datové sadě, je skutečný stav členství každého obrazu stanoven již při vytváření trénovacích dat pro model útoku. Toto řízené nastavení umožňuje jasné posouzení toho, jak efektivně dokáže model útoku rozlišit mezi obrázky, které byly součástí dolaďovací datové sady, a těmi, které nebyly.
Pro tyto testy byl použit Stable Diffusion V1.5. Ačkoli se tento poměrně starý model ve výzkumu často objevuje kvůli potřebě důsledného testování a rozsáhlému souboru předchozích prací, který jej používá, je to vhodný případ použití; V1.5 zůstala populární pro tvorbu LoRA v komunitě fandů Stable Diffusion po dlouhou dobu, a to i přes několik vydání následujících verzí a dokonce i přes příchod Proudění – protože model je zcela necenzurovaný.
Útočný model výzkumníků byl založen na Resnet-18, přičemž předtrénované váhy modelu byly zachovány. Poslední vrstva ResNet-18 s 1000 neurony byla nahrazena plně zapojený vrstva se dvěma neurony. Výcvik pryč byl kategorický křížová entropieA Adam optimalizátor byl použit.
Pro každý test byl model útoku trénován pětkrát s použitím různých náhodná semena vypočítat 95% intervaly spolehlivosti pro klíčové metriky. Nulový výstřel klasifikace s CLIP model byl použit jako základní linie.
(Upozorňujeme, že původní tabulka primárních výsledků v článku je stručná a neobvykle obtížně srozumitelná. Proto jsem ji níže přeformuloval uživatelsky přívětivějším způsobem. Kliknutím na obrázek ji zobrazíte v lepším rozlišení)
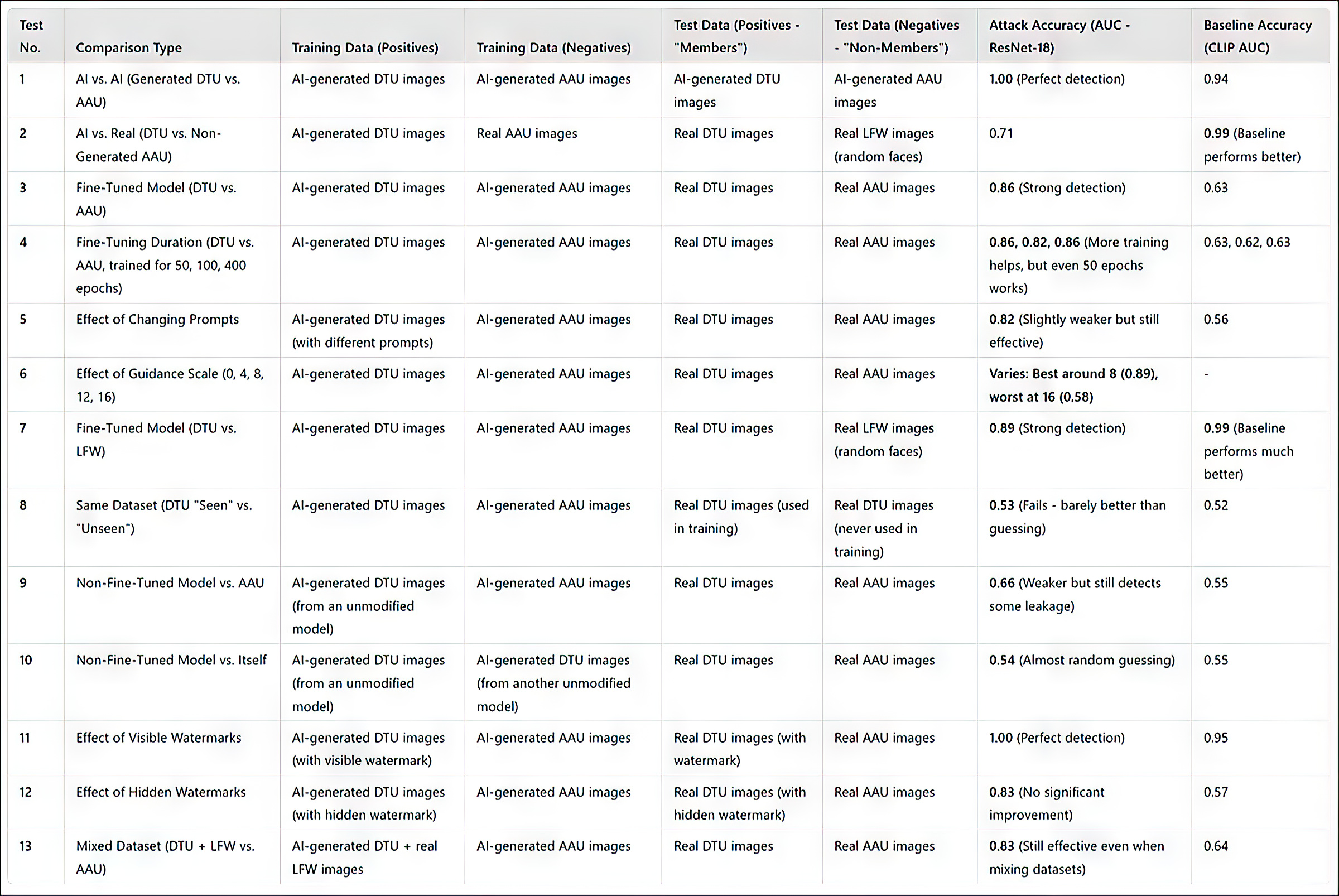
Souhrn výsledků všech testů. Kliknutím na obrázek zobrazíte vyšší rozlišení
Metoda útoku výzkumníků se ukázala jako nejúčinnější při cílení na jemně vyladěné modely, zejména ty trénované na konkrétní sadě obrázků, jako je například obličej jednotlivce. Útok sice dokáže určit, zda byla použita datová sada, ale má potíže s identifikací jednotlivých obrázků v rámci této datové sady.
V praxi to nemusí být nutně překážkou pro forenzní použití takového přístupu; i když má relativně malou hodnotu v prokázání, že v modelu byla použita známá datová sada, jako je ImageNet, útočník na soukromou osobu (ne celebritu) bude mít obvykle mnohem menší výběr zdrojových dat a bude muset plně využít dostupné datové skupiny, jako jsou alba na sociálních sítích a další online sbírky. Ty efektivně vytvářejí „hash“, který lze odhalit popsanými metodami.
Článek uvádí, že dalším způsobem, jak zlepšit přesnost, je používat obrázky generované umělou inteligencí jako „nečleny“, spíše než spoléhat se pouze na skutečné obrázky. Tím se zabrání uměle navyšování míry úspěšnosti, které by jinak mohlo zkreslit výsledky.
Autoři poznamenávají, že dalším faktorem, který významně ovlivňuje detekci, je vodoznak. Když tréninkové obrázky obsahují viditelné vodoznaky, útok se stává vysoce účinným, zatímco skryté vodoznaky nenabízejí žádnou nebo žádnou výhodu.

Obrázek úplně vpravo ukazuje skutečný „skrytý“ vodoznak použitý v testech.
A konečně, svou roli hraje také úroveň vedení při generování textu na obrázek, přičemž ideální vyvážení je na stupnici vedení kolem 8. I když není použita žádná přímá výzva, má vyladěný model stále tendenci produkovat výstupy, které se podobají jeho trénovacím datům, což posiluje efektivitu útoku.
Proč investovat do čističky vzduchu?
Je škoda, že tento zajímavý článek byl napsán tak nepřístupným způsobem, protože by měl zajímat ochránce soukromí i náhodné výzkumníky AI.
Ačkoli se útoky na odvození členství mohou ukázat jako zajímavý a plodný forenzní nástroj, pro tento výzkumný proud je možná důležitější vyvinout použitelné široké principy, aby se zabránilo tomu, že skončí ve stejné hře, jaká se obecně objevila při detekci deepfake, když vydání novějšího modelu nepříznivě ovlivní detekci a podobné forenzní systémy.
Protože v tomto novém výzkumu existují určité důkazy o vyčištěném principu vedení na vyšší úrovni, můžeme doufat, že v tomto směru uvidíme více práce.
Poprvé publikováno v pátek 21. února 2025











