人工智能
使用 AI 在视频片段中改变情绪

来自希腊和英国的研究人员开发了一种新型的深度学习方法,用于改变视频片段中的人物表情和情绪,同时保持唇部运动的真实性,这是之前的尝试无法做到的。

从附件文章末尾的视频中,演员阿尔·帕西诺的表情被 NED 微妙地改变,基于定义个体面部表情的高级语义概念和相关情绪。右侧的“参考驱动”方法取自源视频的解释情绪,并将其应用于整个视频序列。 来源:https://www.youtube.com/watch?v=Li6W8pRDMJQ
这一特定领域属于日益增长的“深度伪造情绪”类别,其中原始演讲者的身份保持不变,但他们的表情和微表情被改变。随着这一人工智能技术的成熟,它为电影和电视制作提供了可能,使演员的表情进行微妙的改变——同时也开启了一个全新的“情绪改变”视频深度伪造类别。
改变面部
公众人物的面部表情,例如政治人物,都是经过精心策划的;2016年,希拉里·克林顿的面部表情曾经受到媒体的密切关注,因为它们可能对她的选举前景产生负面影响;面部表情也是FBI感兴趣的主题;它们也是工作面试中的关键指标,使得(遥远的)实时“表情控制”滤镜的发展成为求职者在Zoom上通过预筛的理想选择。
2005年,英国的一项研究表明,面部外貌会影响投票决定,而2019年《华盛顿邮报》的一篇文章探讨了“脱离上下文”的视频片段分享,这目前是虚假新闻支持者能够改变公众人物看起来的行为、反应或感受的最接近的方法。
向神经表情操控
目前,操控面部情绪的状态相当初级,因为它涉及处理解耦高级概念(例如悲伤、愤怒、幸福、微笑)和实际视频内容。虽然传统的深度伪造架构似乎很好地实现了这种解耦,但在不同身份之间镜像情绪仍需要两个训练面部集包含每个身份的匹配表情。

用于训练深度伪造的数据集中的面部图像示例。目前,您只能通过在深度伪造神经网络中创建特定于ID的表情<>表达路径来操控某人的面部表情。2017年时代的深度伪造软件没有对“微笑”的内在、语义理解——它只是映射和匹配两个主题之间感知的面部几何变化。
理想的结果是能够识别出主题B(例如)如何微笑,并简单地在架构中创建一个“微笑”开关,而不需要将其映射到主题A微笑的等效图像。
新论文的标题为神经情绪导演:语音保留的语义控制面部表情在“野外”视频中,来自希腊国家技术大学电气和计算机工程学院、希腊基础研究和技术研究所计算机科学研究所以及英国埃克塞特大学工程、数学和物理科学学院的研究人员。
该团队开发了一个名为神经情绪导演(NED)的框架,包括一个基于3D的表情转换网络,3D-Based Emotion Manipulator。
NED接收一系列表达参数并将其转换为目标域。它是训练在无对齐数据上的,这意味着不需要训练具有每个身份对应面部表情的数据集。
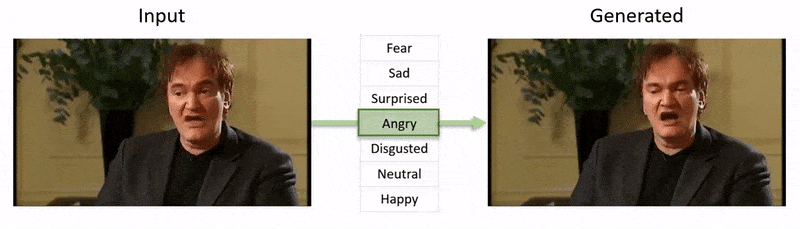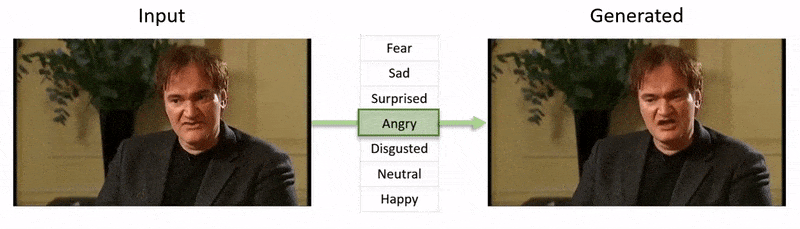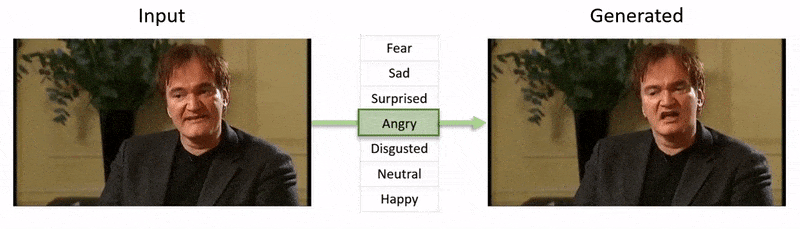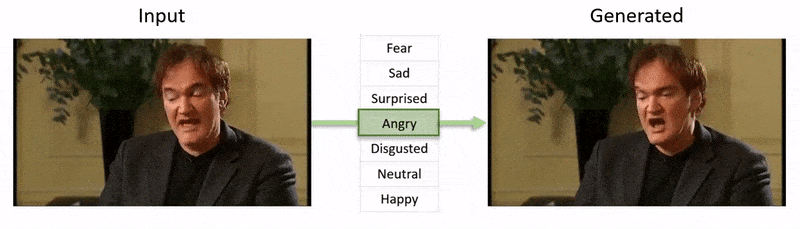
文章末尾的视频展示了NED对YouTube数据集视频片段施加的情绪状态测试。
作者声称NED是第一个用于在随机和不可预测的情况下“指导”演员的基于视频的方法,并且已经在NED的项目页面上提供了代码。
方法和架构
该系统是训练在两个大型视频数据集上的,这些数据集已被注释为“情绪”标签。
输出是通过视频面部渲染器实现的,该渲染器使用传统的面部图像合成技术(包括面部分割、面部特征对齐和混合)将所需的情绪渲染到视频中,只有面部区域被合成,然后叠加到原始视频上。

NED管道的架构。 来源:https://arxiv.org/pdf/2112.00585.pdf
最初,系统获取3D面部恢复并在输入帧上施加面部特征对齐,以识别表情。之后,这些恢复的表情参数被传递到基于3D的表情操控器,并通过语义标签(例如“幸福”)或参考文件计算出风格向量。
参考文件是一段视频,描绘出特定的识别表情/情绪,然后将其施加到目标视频的整个过程中,替换原始表情。

情绪转移管道的阶段,展示了从YouTube视频中采样的各种演员。
最终生成的3D面部形状然后与归一化平均面部坐标(NMFC)和眼部图像(上图中的红点)连接,并传递到神经渲染器,执行最终的操控。
结果
研究人员进行了广泛的研究,包括用户和消融研究,以评估该方法与先前工作的有效性,并发现NED在大多数类别中优于当前的最先进技术。

论文作者预见,未来这项工作的后续实现和类似工具将主要在电视和电影行业中发挥作用,声明:
“我们的方法为神经渲染技术的有用应用开启了大量新的可能性,范围从电影后期制作和视频游戏到照片级别的情绪化化身。”
这是该领域的早期工作,但也是首次尝试使用视频而不是静态图像进行面部重演。虽然视频本质上是快速连续播放的许多静态图像,但时间考虑使得以前的情绪转移应用不那么有效。在附件视频和论文中的示例中,作者包括NED输出与其他最近方法的可视化比较。

更多详细的比较和NED的更多示例可以在下面的完整视频中找到:
2021年12月3日18:30 GMT+2 – 在论文作者之一的要求下,对“参考文件”进行了更正,我错误地将其描述为静态照片(而实际上它是一个视频片段)。此外,对希腊基础研究和技术研究所计算机科学研究所的名称进行了更正。
2021年12月3日20:50 GMT+2 – 在论文作者之一的要求下,对上述机构的名称进行了进一步更正。












