人工智能
Deepfake 探测器追求新领域:潜在扩散模型和 GAN

检讨 最近,自 2017 年底以来,深度伪造检测研究社区几乎完全专注于 自动编码器基于 的框架在当时首次亮相,引起了公众的敬畏(以及 沮丧),已经开始对不那么停滞的架构产生取证兴趣,包括 潜在扩散 模型如 达尔-E 2 和 稳定扩散,以及生成对抗网络(GAN)的输出。 例如,六月,加州大学伯克利分校 发表了结果 其研究开发了用于当时占主导地位的 DALL-E 2 输出的探测器。
推动这种日益增长的兴趣的似乎是 2022 年潜在扩散模型的能力和可用性的突然进化跳跃,闭源和访问受限 释放 春季推出 DALL-E 2,夏末推出轰动一时的 开源 stable.ai 的稳定扩散。
GAN 也已被 长期研究的 在这方面,尽管程度不那么强烈,因为 非常困难 使用它们对人们进行令人信服且精心制作的视频娱乐; 至少,与迄今为止备受推崇的自动编码器包相比,例如 换脸 和 深度人脸实验室 – 以及后者的直播表弟, 深脸直播.
移动图片
无论哪种情况,刺激因素似乎都是后续发展冲刺的前景。 电影 合成。 2022 月伊始,也就是 XNUMX 年的主要会议季,其特点是突然涌现出大量意想不到的解决方案,解决了各种长期存在的视频合成问题:Facebook 刚刚推出 发布样品 谷歌研究中心很快就宣布了其新的图像到视频 T2V 架构,能够输出 高分辨率镜头 (尽管仅通过 7 层升级器网络)。
如果你相信这种事情是三连的,请考虑一下 stable.ai 神秘的承诺,即“视频即将到来”到 Stable Diffusion,显然是在今年晚些时候,而 Stable Diffusion 联合开发商 Runway 已经 做出了类似的承诺,尽管尚不清楚它们是否指的是同一个系统。 这 不和谐消息 Stability 首席执行官 Emad Mostaque 也承诺 “音频、视频[和] 3D”.
突然推出的几项新产品会带来什么 音频生成框架 (一些基于潜在扩散),以及一个可以生成的新扩散模型 真实的角色动作,GAN 和扩散器等“静态”框架最终将取代它们的支持地位 附属物 外部动画框架开始获得真正的关注。
简而言之,基于自动编码器的视频深度伪造的世界似乎很可能陷入困境,它只能有效地替代 脸部的中央部分到明年这个时候,新一代基于扩散的深度伪造技术可能会黯然失色,这些技术是流行的开源方法,有可能不仅可以真实地伪造整个身体,还可以伪造整个场景。
出于这个原因,也许反深度伪造研究社区开始认真对待图像合成,并意识到它可能比仅仅生成图像有更多目的 伪造的 LinkedIn 个人资料照片; 如果它们所有棘手的潜在空间都能以时间运动的形式完成的话 作为一个非常出色的纹理渲染器,这实际上可能已经足够了。
“银翼杀手”
最新的两篇论文分别涉及潜在扩散和基于 GAN 的深度伪造检测,分别是: DE-FAKE:文本到图像扩散模型生成的假图像的检测和归因,CISPA 亥姆霍兹信息安全中心和 Salesforce 之间的合作; 和 《银翼杀手》:针对合成(AI 生成)StyleGAN 面孔的快速对策,来自麻省理工学院林肯实验室的 Adam Dorian Wong。
在解释其新方法之前,后一篇论文花了一些时间来研究之前确定图像是否由 GAN 生成的方法(该论文专门讨论了 NVIDIA 的 StyleGAN 系列)。
“Brady Bunch”方法——也许是一种 无意义的参考 对于那些在 1970 世纪 1990 年代没有看电视或错过 XNUMX 年代电影改编的人 – 根据 GAN 面部特定部分肯定占据的固定位置来识别 GAN 伪造的内容,因为这些内容具有死记硬背和模板化的性质“生产过程”。

SANS 研究所在 2022 年的一次网络广播中提出了“Brady Bunch”方法:基于 GAN 的面部生成器将对某些面部特征进行不太可能的均匀放置,在某些情况下掩盖照片的来源。 资料来源:https://arxiv.org/ftp/arxiv/papers/2210/2210.06587.pdf
另一个有用的已知迹象是 StyleGAN 经常无法在必要时渲染多个面孔(下面第一张图),并且缺乏配件协调方面的天赋(下面中间图),并且倾向于使用发际线作为即兴创作的开始帽子(下面第三张图片)。

研究人员关注的第三种方法是 照片叠加 (其中的一个例子可以在 我们八月的文章 关于精神健康疾病的人工智能辅助诊断),它使用组合“图像混合”软件(例如CombineZ系列)将多个图像连接成单个图像,通常揭示结构中潜在的共性——这是合成的潜在迹象。

新论文中提出的架构的标题是(可能违背所有 SEO 建议) “银翼杀手”,参考 Voight-Kampff检验 这决定了科幻系列中的对手是否是“假的”。
该管道由两个阶段组成,第一个阶段是 PapersPlease 分析器,它可以评估从已知的 GAN-face 网站(例如 thispersondoesnotexist.com 或 generated.photos)抓取的数据。

尽管可以在 GitHub 上检查代码的简化版本(见下文),但除了 OpenCV 和 DLIB 用于勾画和检测收集到的材料中的面部。
第二个模块是 我们之间 探测器。 该系统旨在搜索照片中协调的眼睛位置,这是 StyleGAN 面部输出的一个持久特征,以上面详述的“Brady Bunch”场景为代表。 Ours 由标准的 68 个地标探测器提供支持。

通过智能行为理解组 (IBUG) 进行面部点注释,其面部标志绘图代码用于《银翼杀手》软件包中。
Ours 依赖于基于来自 PapersPlease 的已知“Brady 群”坐标的预先训练的地标,并且旨在用于基于 StyleGAN 的人脸图像的实时、面向网络的样本。
作者认为,《银翼杀手》是一种即插即用的解决方案,适用于那些缺乏资源来开发内部解决方案来进行此处处理的深度造假检测的公司或组织,并且是一种“为开发时间争取时间的权宜之计”。更持久的对策”。
事实上,在如此不稳定且快速增长的安全领域,定制的产品并不多 or 现成的云供应商解决方案,资源不足的公司目前可以放心地求助于这些解决方案。
尽管《银翼杀手》在对抗中表现不佳 戴眼镜的 对于 StyleGAN 伪造者来说,这是类似系统中相对常见的问题,这些系统期望能够将眼睛轮廓评估为核心参考点,在这种情况下会变得模糊。
《银翼杀手》的缩减版已经 发布 在 GitHub 上开源。 存在功能更丰富的专有版本,它可以处理多张照片,而不是开源存储库的每次操作处理单张照片。 他表示,如果时间允许,作者打算最终将 GitHub 版本升级到相同标准。 他还承认 StyleGAN 很可能会超越其已知或当前的弱点,并且该软件同样需要同步开发。
防伪
DE-FAKE 架构不仅旨在实现对文本到图像扩散模型生成的图像的“通用检测”,而且提供一种识别文本到图像的方法。 这 潜在扩散(LD)模型产生图像。
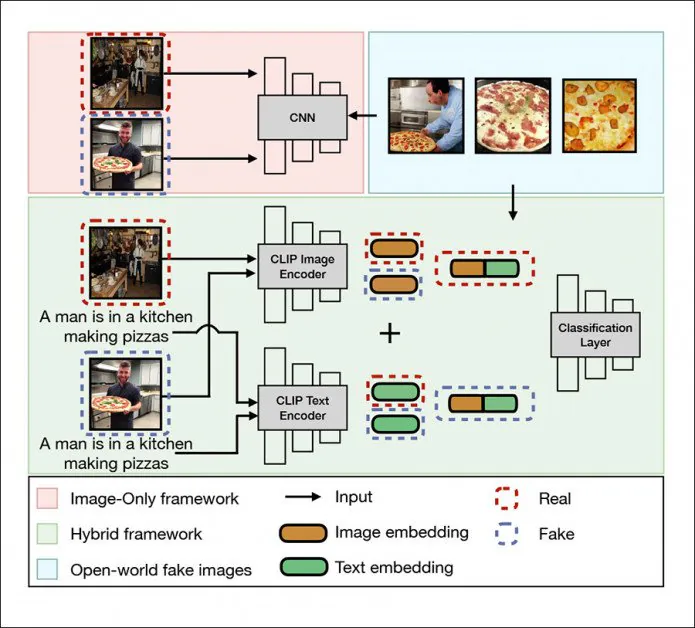
DE-FAKE 中的通用检测框架解决本地图像、混合框架(绿色)和开放世界图像(蓝色)的问题。 资料来源:http://export.arxiv.org/pdf/2210.06998
老实说,目前这是一项相当容易的任务,因为所有流行的 LD 模型(封闭的或开源的)都具有显着的显着特征。
此外,大多数人都有一些共同的弱点,例如有砍头的倾向,因为 任意方式 非方形网络抓取图像被摄取到为 DALL-E 2、Stable Diffusion 和 MidJourney 等系统提供动力的海量数据集中:

与所有计算机视觉模型一样,潜在扩散模型需要正方形格式的输入;但是为 LAION5B 数据集提供支持的聚合网络抓取并没有提供“豪华的额外功能”,例如识别和关注面部(或其他任何东西)的能力,并且相当残酷地截断图像而不是填充它们(这将保留整个源)图像,但分辨率较低)。一旦接受训练,这些“作物”就会标准化,并且经常出现在潜在扩散系统(例如稳定扩散)的输出中。 来源:https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac 和稳定扩散。
DE-FAKE 的目的是与算法无关,这是自动编码器反深度造假研究人员长期以来所追求的目标,而且目前对于 LD 系统来说,这是一个可以实现的目标。
该架构使用 OpenAI 的对比语言-图像预训练(CLIP)多模态库——稳定扩散的一个基本要素,并迅速成为新一波图像/视频合成系统的核心——作为从“伪造”LD图像中提取嵌入并根据观察到的模式和类别训练分类器的一种方法。
在更“黑匣子”的场景中,保存有关生成过程信息的 PNG 块早已通过上传过程和其他原因被剥离,研究人员使用 Salesforce BLIP框架 (也是一个组件 最后一个 稳定扩散的分布)来“盲目地”轮询图像以获取创建它们的提示的可能语义结构。

研究人员使用 Stable Diffusion、Latent Diffusion(本身是一个离散产品)、GLIDE 和 DALL-E 2 来利用 MSCOCO 和 Flickr30k 填充训练和测试数据集。
通常我们会对研究人员针对新框架的实验结果进行相当广泛的研究; 但事实上,DE-FAKE 的发现似乎更适合作为后续迭代和类似项目的未来基准,而不是作为项目成功的有意义的衡量标准,考虑到其运行的不稳定环境以及它所使用的系统论文试验中的竞争对手已经近三年了——从图像合成场景真正萌芽的时候开始。

最左边的两张图像:“受到挑战”的先前框架,起源于 2019 年,可以预见的是,在测试的四个 LD 系统中,与 DE-FAKE(最右边的两张图像)相比,表现较差。
该团队的结果是绝对积极的,原因有两个:没有任何先前的工作可以与之比较(并且根本没有提供公平的比较,即涵盖自稳定扩散开源以来仅十二周的比较)。
其次,如上所述,尽管 LD 图像合成领域正在以指数速度发展,但当前产品的输出内容通过其自身的结构性(且非常可预测的)缺陷和怪癖有效地给自己打上了水印——其中许多缺陷和怪癖都可能得到纠正,至少在稳定扩散的情况下,通过发布性能更好的 1.5 检查点(即为系统提供动力的 4GB 训练模型)。
同时,Stability已经表示对于系统的V2和V3有明确的路线图。 考虑到过去三个月的头条新闻,OpenAI 和图像合成领域其他竞争者的任何企业迟钝都可能已经消失,这意味着我们可以预期在图像合成领域也会有类似的快速进展。闭源图像合成空间。
首次发布于 14 年 2022 月 XNUMX 日。















