Штучний інтелект
Створення мовної моделі в стилі GPT для однієї конкретної задачі

Дослідники з Китаю розробили економічний метод створення систем обробки природної мови (NLP) у стилі GPT-3, уникаючи дедалі заборонних витрат часу та грошей на навчання на великих обсягах даних — тенденції, яка в іншому випадку загрожує зрештою віддати цей сектор штучного інтелекту в руки гравців на кшталт FAANG та великих інвесторів. Запропонована структура називається Task-Driven Language Modeling (TLM). Замість навчання величезної та складної моделі на величезному корпусі з мільярдів слів і тисяч міток та класів, TLM натомість тренує набагато меншу модель, яка фактично включає запит безпосередньо всередину моделі.

Ліворуч — типовий гіпермасштабний підхід до мовних моделей великого обсягу; праворуч — оптимізований метод TLM для дослідження великого мовного корпусу за темою або питанням. Джерело: https://arxiv.org/pdf/2111.04130.pdf
Фактично створюється унікальний алгоритм або модель NLP, щоб відповісти на одне конкретне питання, замість створення величезної та громіздкої загальної мовної моделі, яка може відповідати на ширший спектр питань. Під час тестування TLM дослідники виявили, що новий підхід досягає результатів, подібних або кращих, ніж попередньо навчені мовні моделі (Pretrained Language Models), такі як RoBERTa-Large, та гіпермасштабні системи NLP, такі як GPT-3 від OpenAI, трильйонпараметрова модель Switch Transformer від Google, HyperClover з Кореї, Jurassic 1 від AI21 Labs та Megatron-Turing NLG 530B від Microsoft. У випробуваннях TLM на восьми класифікаційних наборах даних у чотирьох доменах автори також виявили, що система зменшує необхідні для навчання FLOP (операції з плаваючою комою за секунду) на два порядки. Дослідники сподіваються, що TLM зможе «демократизувати» сектор, який стає все більш елітарним, з NLP-моделями настільки великими, що їх нереально встановити локально, і які, як у випадку з GPT-3, перебувають за дорогими API з обмеженим доступом від OpenAI та, тепер, Microsoft Azure. Автори заявляють, що скорочення часу навчання на два порядки зменшує вартість навчання з понад 1000 GPU протягом одного дня до всього лише 8 GPU протягом 48 годин. Новий звіт має назву NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework і належить трьом дослідникам з Університету Цинхуа в Пекіні та досліднику з китайської компанії з розробки штучного інтелекту Recurrent AI, Inc.
Недоступні відповіді
Вартість навчання ефективних універсальних мовних моделей все частіше характеризується як потенційна «теплова межа» того, наскільки продуктивні та точні NLP можуть поширитися в культурі.
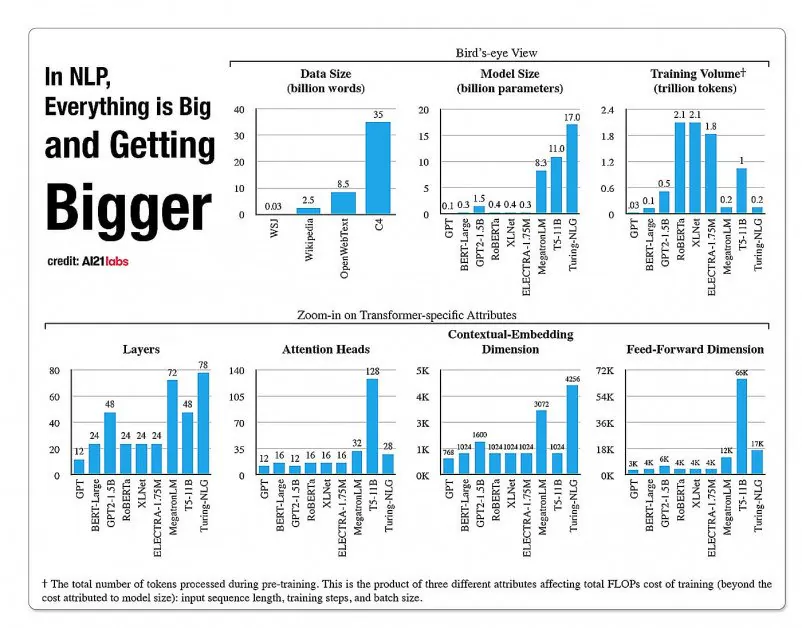
Статистика зростання аспектів у архітектурах NLP-моделей із звіту A121 Labs за 2020 рік. Джерело: https://arxiv.org/pdf/2004.08900.pdf
У 2019 році дослідник підрахував, що навчання моделі XLNet (яка, за повідомленнями того часу, перевершувала BERT у задачах NLP) коштує 61 440 доларів США протягом 2,5 днів на 512 ядрах на 64 пристроях, тоді як навчання GPT-3 оцінюється в 12 мільйонів доларів — у 200 разів дорожче за навчання її попередника, GPT-2 (хоча нещодавні переоцінки стверджують, що зараз її можна навчити всього за 4 600 000 доларів на найдешевших хмарних GPU).
Підмножини даних на основі потреб запиту
Натомість нова запропонована архітектура прагне отримати точні класифікації, мітки та узагальнення, використовуючи запит як своєрідний фільтр для визначення підмножини інформації з великої мовної бази даних, яка буде навчатися разом із запитом, щоб надавати відповіді на обмежену тему. Автори заявляють:
‘TLM мотивована двома ключовими ідеями. По-перше, люди опановують задачу, використовуючи лише невелику частину світових знань (наприклад, студентам потрібно переглянути лише кілька розділів серед усіх книг у світі, щоб підготуватися до іспиту).
Ми припускаємо, що у великому корпусі для конкретного завдання є багато надлишковості. По-друге, навчання на контрольованих розмічених даних набагато ефективніше для подальшої продуктивності, ніж оптимізація цілі мовного моделювання на нерозмічених даних. Виходячи з цих мотивацій, TLM використовує дані завдання як запити для отримання крихітної підмножини загального корпусу. Після цього відбувається спільна оптимізація цілі контрольованого завдання та цілі мовного моделювання з використанням як отриманих даних, так і даних завдання.’
Окрім того, що робить високоефективне навчання NLP-моделей доступним, автори бачать низку переваг у використанні орієнтованих на завдання NLP-моделей. По-перше, дослідники можуть отримати більшу гнучкість завдяки спеціальним стратегіям для довжини послідовності, токенізації, налаштування гіперпараметрів та представлення даних. Дослідники також передбачають розвиток гібридних майбутніх систем, які балансують між обмеженим попереднім навчанням PLM (чого не передбачається в поточній реалізації) та більшою універсальністю та узагальненням проти часу навчання. Вони вважають цю систему кроком уперед у розвитку внутрішньодоменних методів узагальнення з нульовим зразком (zero-shot).
Тестування та результати
TLM було протестовано на завданнях класифікації у восьми задачах у чотирьох доменах — біомедична наука, новини, огляди та інформатика. Завдання були розділені на категорії з високими та низькими ресурсами. Завдання з високими ресурсами включали понад 5000 даних завдань, такі як AGNews та RCT, серед інших; завдання з низькими ресурсами включали ChemProt та ACL-ARC, а також набір даних для виявлення новин HyperPartisan. Дослідники розробили два навчальні набори під назвами Corpus-BERT та Corpus-RoBERTa, останній у десять разів більший за перший. Експерименти порівнювали загальні попередньо навчені мовні моделі BERT (від Google) та RoBERTA (від Facebook) з новою архітектурою. У статті зазначається, що хоча TLM є загальним методом і має бути більш обмеженим за сферою застосування та придатністю, ніж ширші та більш об’ємні сучасні моделі, він здатний працювати близько до методів тонкого налаштування з адаптацією до домену.

Результати порівняння продуктивності TLM з наборами на основі BERT та RoBERTa. У результатах вказано середній показник F1 для трьох різних масштабів навчання, а також кількість параметрів, загальні обчислення для навчання (FLOPs) та розмір навчального корпусу.
Автори роблять висновок, що TLM здатна досягати результатів, порівнянних або кращих за PLM, із суттєвим зменшенням необхідних FLOPs та вимагаючи лише 1/16 навчального корпусу. У середньому та великому масштабі TLM, очевидно, може покращити продуктивність на 0,59 та 0,24 пункту в середньому, одночасно зменшуючи розмір навчальних даних на два порядки.
‘Ці результати підтверджують, що TLM є високоточною та набагато ефективнішою, ніж PLM. Більше того, TLM отримує більше переваг у ефективності в більшому масштабі. Це вказує на те, що PLM більшого масштабу, можливо, навчалися зберігати більш загальні знання, які не є корисними для конкретного завдання.’












