Штучний інтелект
Auto-GPT та GPT-Engineer: Повний огляд провідних агентів штучного інтелекту сьогодні

При порівнянні ChatGPT з автономними штучними агентами, такими як Auto-GPT і GPT-Engineer, виникає суттєва різниця у процесі прийняття рішень. Хоча ChatGPT потребує активної участі людини для керування розмовою, надаючи керівництво на основі запитів користувача, процес планування в основному залежить від втручання людини.
Генеративні моделі штучного інтелекту типу трансформерів є найновішими технологіями, що рухають ці автономні штучні агенти. Ці трансформери тренуються на великих наборах даних, що дозволяє їм імітувати складне мислення та прийняття рішень.
Відкриті джерела автономних агентів: Auto-GPT і GPT-Engineer
Багато з цих автономних штучних агентів походять від відкритих ініціатив, очолюваних інновативними особами, які трансформують традиційні робочі процеси. Натомість ніж просто пропонувати поради, агенти, такі як Auto-GPT, можуть самостійно виконувати завдання, від онлайн-шопінгу до створення базових застосунків. Інтерпретатор коду OpenAI спрямований на вдосконалення ChatGPT від простого пропонування ідей до активного вирішення проблем за допомогою цих ідей.
Обидва Auto-GPT і GPT-Engineer оснащені можливостями GPT 3.5 і GPT-4. Вони розуміють логіку коду, поєднують кілька файлів та прискорюють процес розробки.
Саме серце функціональності Auto-GPT лежить в його штучних агентах. Ці агенти програмуються для виконання конкретних завдань, від буденних, таких як планування, до більш складних завдань, які вимагають стратегічного прийняття рішень. Однак ці штучні агенти діють в межах, встановлених користувачами. Контролюючи їхній доступ через API, користувачі можуть визначити глибину та сферу дій штучного інтелекту.
Наприклад, якщо завдання полягає в створенні веб-застосунку для чату, інтегрованого з ChatGPT, Auto-GPT автономно розбиває мету на виконувані кроки, такі як створення HTML-інтерфейсу або написання Python-бекенду. Хоча застосунок автономно генерує ці запити, користувачі все ще можуть контролювати та змінювати їх. Як показав творець AutoGPT @SigGravitas, він здатний створити та виконати тестову програму на основі Python.
https://twitter.com/SigGravitas/status/1642181498278408193
Хоча нижче наведена діаграма описує більш загальну архітектуру автономного штучного агента, вона надає цінний погляд на процеси, що відбуваються за сценою.

Архітектура автономного штучного агента
Процес ініціюється шляхом верифікації ключа API OpenAI та ініціалізації різних параметрів, включаючи короткочасну пам’ять та вміст бази даних. Як тільки ключові дані передаються агенту, модель взаємодіє з GPT3.5/GPT4 для отримання відповіді. Ця відповідь потім перетворюється у формат JSON, який агент інтерпретує для виконання різних функцій, таких як проведення онлайн-пошуків, читання чи запис файлів або навіть виконання коду. Auto-GPT використовує попередньо тренований модель для зберігання цих відповідей у базі даних, а майбутні взаємодії використовують цю збережену інформацію для посилання.
Цикл продовжується до тих пір, поки завдання не буде визнано завершеним.
Керівництво з налаштування Auto-GPT і GPT-Engineer
Налаштування інструментів нового покоління, таких як GPT-Engineer і Auto-GPT, може оптимізувати ваш процес розробки. Нижче наведено структуроване керівництво, яке допоможе вам встановити та налаштувати обидва інструменти.
Auto-GPT
Налаштування Auto-GPT може видатися складним, але з правильними кроками воно стає простим. Це керівництво охоплює процедуру налаштування Auto-GPT та надає уявлення про його різноманітні сценарії.
1. Передумови:
- Середовище Python: Перевірте, чи встановлено у вас Python 3.8 або пізніше. Ви можете отримати Python з офіційного сайту.
- Якщо ви плануєте клонувати репозиторії, встановіть Git.
- Ключ API OpenAI: Для взаємодії з OpenAI потрібен ключ API. Отримайте ключ з вашого облікового запису OpenAI

Генерація ключа API Open AI
Варіанти пам’яті: Пам’ять служить механізмом зберігання для AutoGPT для доступу до необхідних даних для його операцій. AutoGPT використовує як короткочасну, так і довгочасну пам’ять. Pinecone, Milvus, Redis та інші є деякими варіантами, які доступні.
2. Налаштування робочого простору:
- Створіть віртуальне середовище:
python3 -m venv myenv - Активуйте середовище:
- MacOS або Linux:
source myenv/bin/activate
- MacOS або Linux:
3. Встановлення:
- Клонуйте репозиторій Auto-GPT (перевірте, чи встановлено у вас Git):
git clone https://github.com/Significant-Gravitas/Auto-GPT.git - Щоб працювати з версією 0.2.2 Auto-GPT, вам потрібно перейти до цієї конкретної версії:
git checkout stable-0.2.2 - Перейдіть до завантаженого репозиторію:
cd Auto-GPT - Встановіть необхідні залежності:
pip install -r requirements.txt
4. Налаштування:
- Знайдіть
.env.templateу головному каталозі/Auto-GPT. Дублікат і перейменуйте його у.env - Відкрийте
.envі встановіть свій ключ API OpenAI поруч зOPENAI_API_KEY= - Аналогічно, для використання пам’яті типу Pinecone оновіть файл
.envз вашим ключем API Pinecone та регіоном.
5. Командні інструкції:
Auto-GPT пропонує багаті командні аргументи для налаштування його поведінки:
- Загальне використання:
- Показати допомогу:
python -m autogpt --help - Налаштування налаштувань штучного інтелекту:
python -m autogpt --ai-settings <filename> - Вказівка пам’яті:
python -m autogpt --use-memory <memory-backend>
- Показати допомогу:

AutoGPT в командному рядку
6. Запуск Auto-GPT:
Як тільки налаштування завершено, ініціюйте Auto-GPT за допомогою:
- Linux або Mac:
./run.sh start - Windows:
.run.bat
Інтеграція з Docker (Рекомендований підхід до налаштування)
Для тих, хто хоче контейнеризувати Auto-GPT, Docker пропонує оптимізований підхід. Однак варто бути обережним, оскільки первинна налаштування Docker може бути трохи складною. Перейдіть до посібника з установки Docker для отримання допомоги.
Продовжуйте, слідуючи крокам нижче для зміни ключа API OpenAI. Перевірте, чи працює Docker на фоні. Тепер перейдіть до головного каталогу AutoGPT і слідуйте нижче вказаним крокам у вашому терміналі
- Збудуйте зображення Docker:
docker build -t autogpt . - Тепер запустіть:
docker run -it --env-file=./.env -v$PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt
З docker-compose:
- Запустіть:
docker-compose run --build --rm auto-gpt - Для додаткової налаштування ви можете інтегрувати додаткові аргументи. Наприклад, для запуску з –gpt3only і –continuous:
docker-compose run --rm auto-gpt --gpt3only--continuous - Враховуючи розширені автономні можливості Auto-GPT у генерації контенту з великих наборів даних, існує потенційний ризик того, що він ненавмисно отримає доступ до шкідливих веб-джерел.
Для мінімізації ризиків працюйте з Auto-GPT у віртуальному контейнері, наприклад, Docker. Це забезпечує, що будь-який потенційно шкідливий контент залишається у віртуальному просторі, залишаючи ваші зовнішні файли та систему неушкодженими. Альтернативно, Windows Sandbox є варіантом, хоча він скидається після кожної сесії, не зберігаючи свій стан.
Для безпеки завжди виконуйте Auto-GPT у віртуальному середовищі, забезпечуючи, щоб ваша система залишилася ізольованою від несподіваних виводів.
Враховуючи все це, все ще існує можливість, що ви не зможете отримати бажані результати. Користувачі Auto-GPT повідомили про постійні проблеми при спробі записати у файл, часто зустрічаючи невдачі через проблемні назви файлів. Ось одна така помилка: Auto-GPT (реліз 0.2.2) не додає текст після помилки "write_to_file повернув: Помилка: Файл вже оновлено
Різні рішення для вирішення цієї проблеми обговорюються на відповідній сторінці проблем GitHub для посилання.
GPT-Engineer
Потік роботи GPT-Engineer:
- Визначення запиту: Створіть детальний опис вашого проекту, використовуючи природну мову.
- Генерація коду: На основі вашого запиту GPT-Engineer починає працювати, генеруючи кодові фрагменти, функції або навіть повні застосунки.
- Удосконалення та оптимізація: Після генерації коду завжди існує можливість для покращення. Розробники можуть змінити згенерований код, щоб задовольнити конкретні вимоги, забезпечуючи високу якість.
Процес налаштування GPT-Engineer був скорочений до легкого для слідування керівництва. Ось крок за кроком:
1. Підготовка середовища: Перед тим, як почати, переконайтеся, що у вас готовий каталог проекту. Відкрийте термінал і запустіть нижче вказану команду
- Створіть новий каталог з назвою ‘website’:
mkdir website- Перейдіть до каталогу:
cd website
2. Клонуйте репозиторій: git clone https://github.com/AntonOsika/gpt-engineer.git .
3. Перейдіть та встановіть залежності: Як тільки клоновано, перейдіть до каталогу cd gpt-engineer та встановіть всі необхідні залежності make install
4. Активуйте віртуальне середовище: залежно від вашої операційної системи, активуйте створене віртуальне середовище.
- Для macOS/Linux:
source venv/bin/activate
- Для Windows, це трохи відрізняється через налаштування ключа API:
set OPENAI_API_KEY=[your api key]
5. Налаштування – налаштування ключа API: Для взаємодії з OpenAI вам потрібен ключ API. Якщо у вас його ще немає, зареєструйтесь на платформі OpenAI, а потім:
- Для macOS/Linux:
export OPENAI_API_KEY=[your api key]
- Для Windows (як згадувалося раніше):
set OPENAI_API_KEY=[your api key]
6. Ініціалізація проекту та генерація коду: Чудеса GPT-Engineer починаються з файлу main_prompt, який знаходиться у папці projects.
- Якщо ви хочете розпочати новий проект:
cp -r projects/example/ projects/website
Тут замініть ‘website’ на назву вашого проекту.
- Відкрийте файл
main_prompt, використовуючи редактор тексту на ваш вибір, і напишіть вимоги вашого проекту.

- Як тільки ви задоволені запитом, запустіть:
gpt-engineer projects/website
Ваш згенерований код буде розміщено у каталозі workspace всередині папки проекту.
7. Після генерації: Хоча GPT-Engineer потужний, він не завжди досконалий. Перегляньте згенерований код, внесіть будь-які ручні зміни, якщо це потрібно, і переконайтеся, що все працює гладко.
Приклад запуску
Запит:
“Я хочу розробити базовий застосунок Streamlit на Python, який візуалізує дані користувача через інтерактивні графіки. Застосунок повинен дозволяти користувачам завантажувати файл CSV, вибирати тип графіка (наприклад, стовпчиковий, круговий, лінійний) і динамічно візуалізувати дані. Він може використовувати бібліотеки типу Pandas для маніпуляції даними та Plotly для візуалізації.”
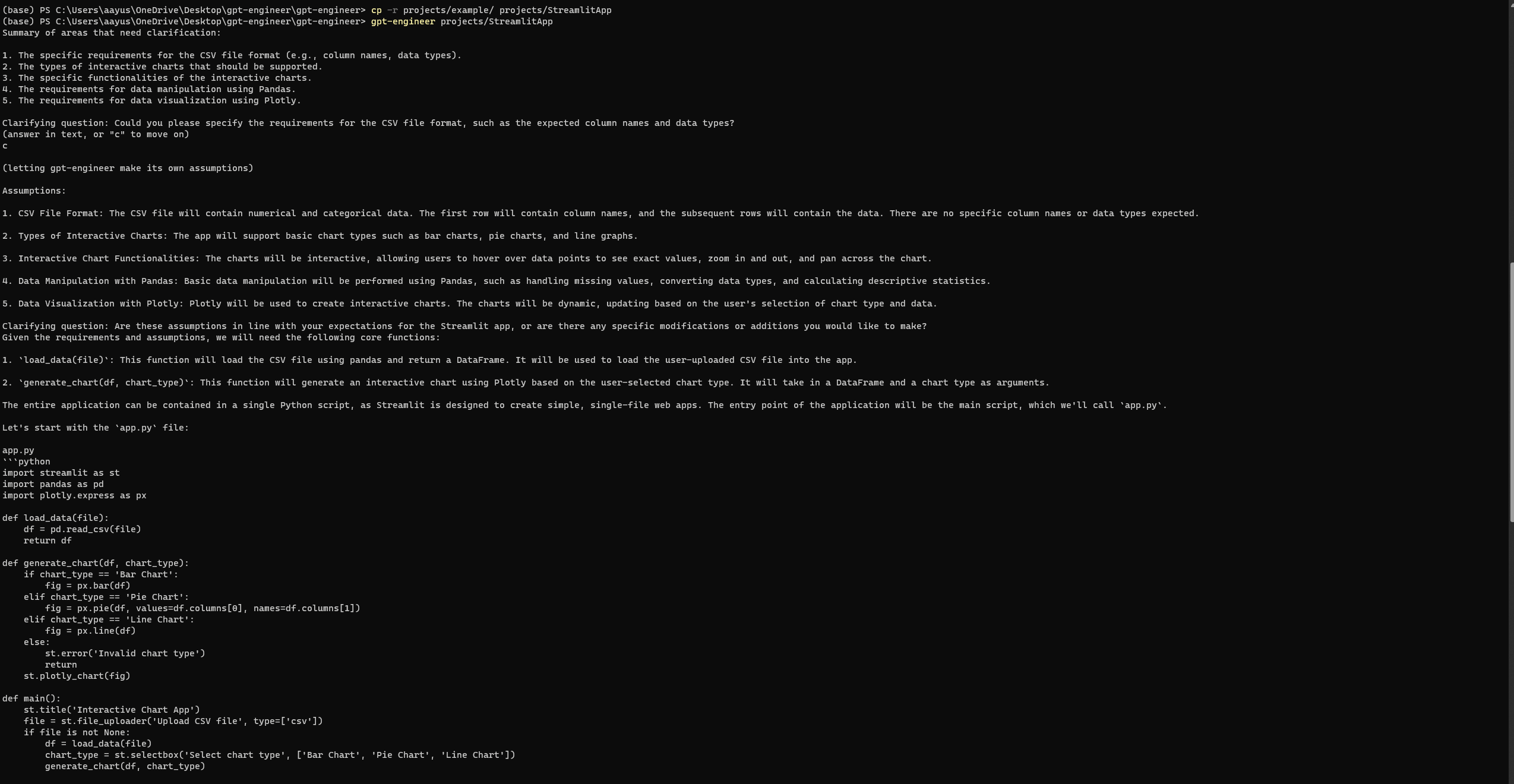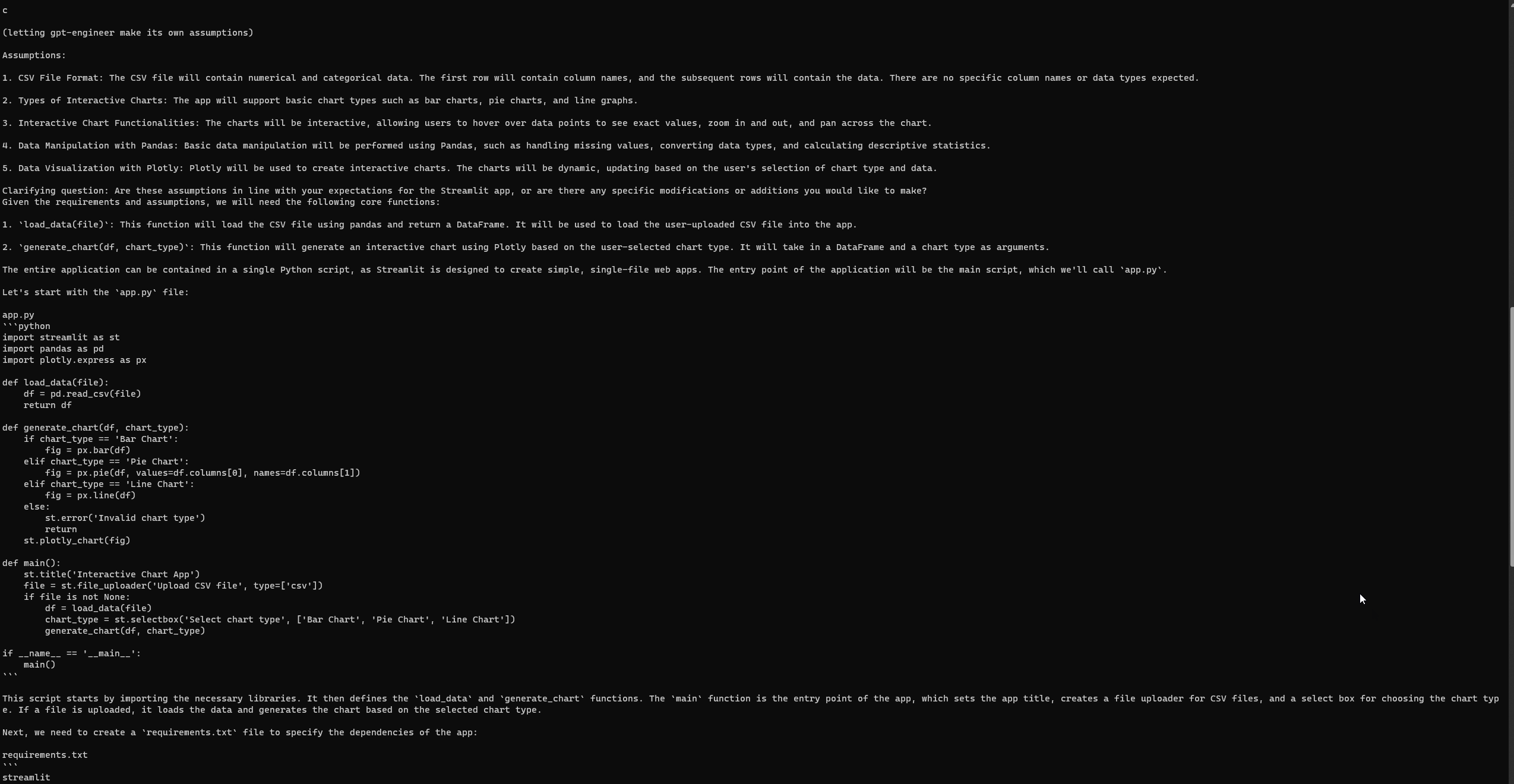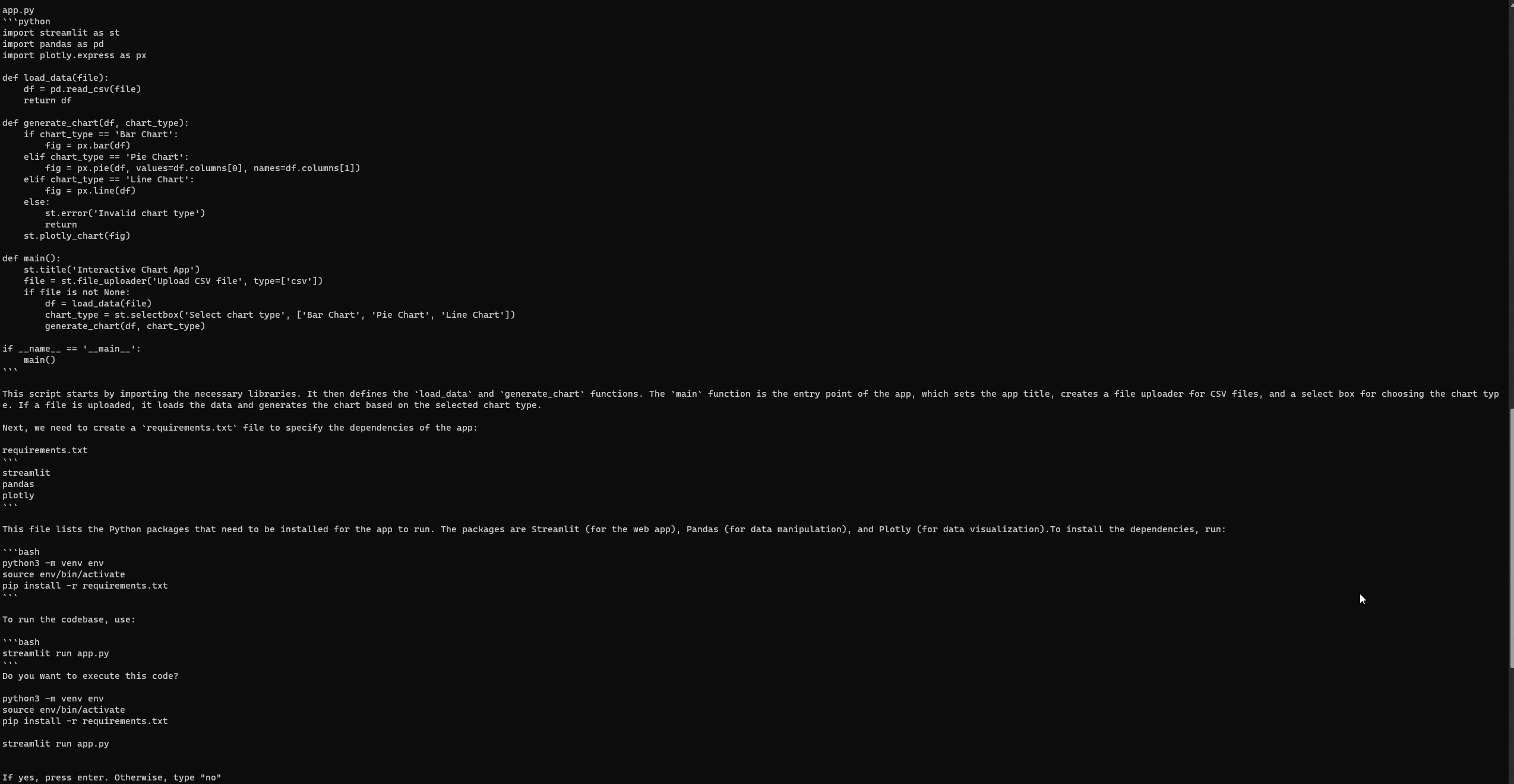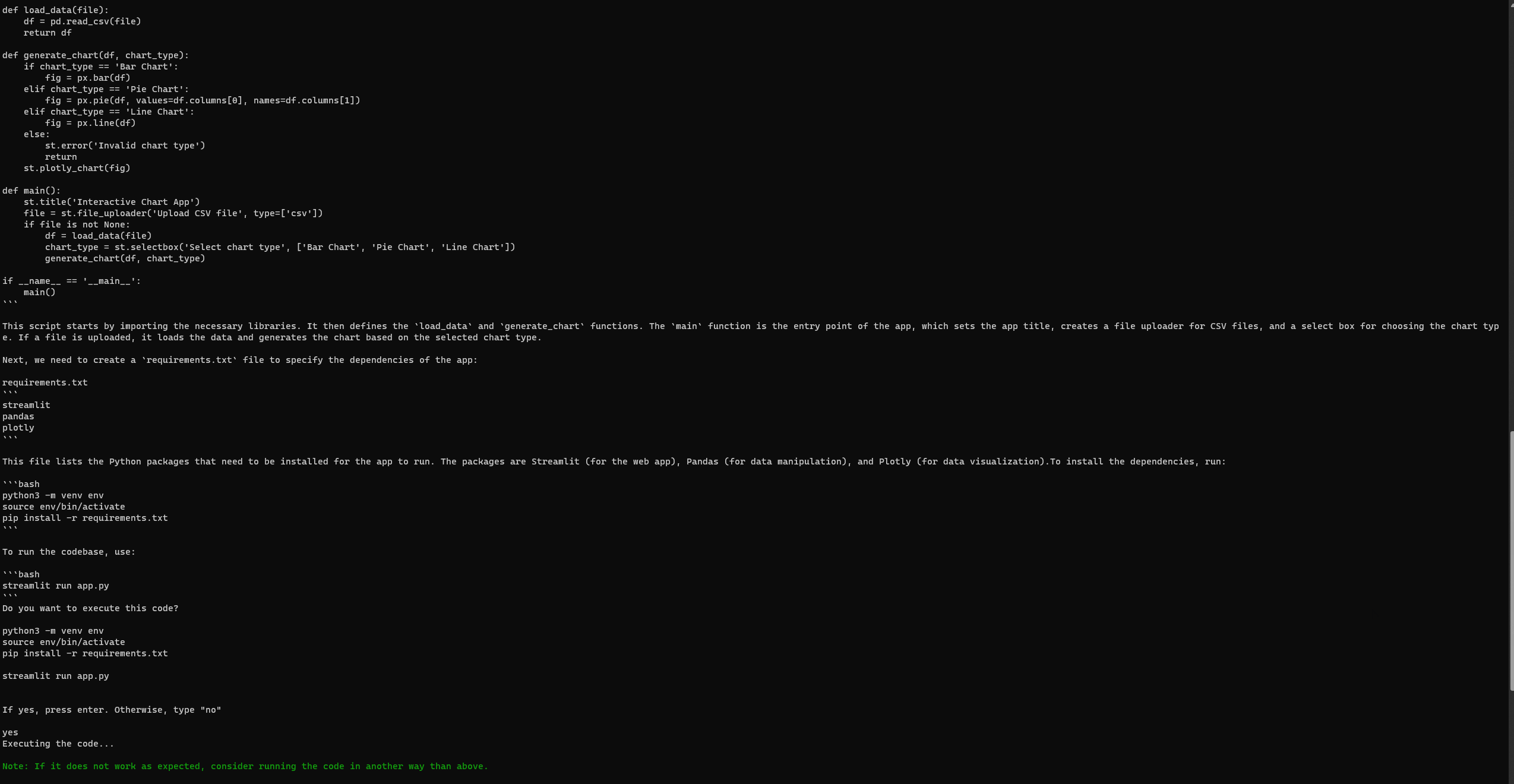
Налаштування та запуск GPT-Engineer
Подібно до Auto-GPT, GPT-Engineer іноді може зустріти помилки навіть після повного налаштування. Однак на моєму третьому спробі я успішно отримав доступ до наступної сторінки Streamlit. Перегляньте будь-які помилки на офіційній сторінці проблем GPT-Engineer.

Застосунок Streamlit, згенерований за допомогою GPT-Engineer
Поточні обмеження штучних агентів
Операційні витрати
Одне завдання, виконане Auto-GPT, може включати численні кроки. Насамперед, кожен з цих кроків може бути оплачений окремо, збільшуючи витрати. Auto-GPT може потрапити у повторювані цикли, не доставляючи обіцяних результатів. Такі випадки підкріплюють його надійність і підірвуть інвестиції.
Уявіть, що ви хочете створити короткий есе за допомогою Auto-GPT. Ідеальна довжина есе становить 8 тисяч символів, але під час створення моделі занурюється у численні проміжні кроки для завершення контенту. Якщо ви використовуєте GPT-4 з довжиною контексту 8 тисяч символів, то для введення ви будете оплачені 0,03 долари. А для виводу вартість становитиме 0,06 долари. Тепер припустимо, що модель потрапляє у непередбачуваний цикл, повторюючи певні частини кілька разів. Не тільки процес ставає довшим, але кожне повторення також додається до вартості.
Для захисту від цього:
- Встановіть ліміт використання на сторінці облікового запису OpenAI та лімітів:
- Твердий ліміт: Обмежує використання після встановленого порогу.
- М’який ліміт: Надсилає вам повідомлення про досягнення порогу.
Обмеження функціональності
Можливості Auto-GPT, як зображено в його вихідному коді, мають певні межі. Його стратегії вирішення проблем керуються його внутрішніми функціями та доступністю, наданою API GPT-4. Для глибоких обговорень та можливих рішень зверніться до: Обговорення Auto-GPT.
Вплив штучного інтелекту на ринок праці
Динаміка між штучним інтелектом і ринком праці постійно змінюється і докладно описується в цьому дослідному папері. Ключовий висновок полягає в тому, що хоча технологічний прогрес часто приносить користь кваліфікованим працівникам, він створює ризики для тих, хто зайнятий рутинними завданнями. Насправді технологічні досягнення можуть замінити певні завдання, але одночасно відкривають шлях для різноманітних, праці інтенсивних завдань.

Оцінюється, що близько 80% американських працівників можуть виявити, що ЛЛМ (моделі мови) впливають на близько 10% їхніх щоденних завдань. Ця статистика підкреслює злиття штучного інтелекту та людських ролей.
Двогранна роль штучного інтелекту на робочому місці:
- Позитивні аспекти: Штучний інтелект може автоматизувати багато завдань, від служби підтримки клієнтів до фінансових порад, надаючи полегшення малим підприємствам, які не мають коштів для окремих команд.
- Обставини: Перевага автоматизації піднімає брови щодо потенційних втрат робочих місць, особливо в галузях, де участь людини є важливою, наприклад, у підтримці клієнтів. Разом з цим існує етична проблема, пов’язана з доступом штучного інтелекту до конфіденційних даних. Це вимагає сильної інфраструктури, що забезпечує прозорість, підзвітність та етичне використання штучного інтелекту.
Висновок
Чисто, інструменти, такі як ChatGPT, Auto-GPT і GPT-Engineer, стоять на передовому краї зміни взаємодії між технологіями та їхніми користувачами. З корінням в відкритих рухах, ці штучні агенти втілюють можливості машинної автономії, оптимізуючи завдання від планування до розробки програмного забезпечення.
Як ми рухаємося у майбутнє, де штучний інтелект інтегрується глибше у нашу щоденну діяльність, баланс між прийняттям можливостей штучного інтелекту та захистом людських ролей стає важливим. На ширшому спектрі динаміка штучного інтелекту та ринку праці малює подвійний образ можливостей зростання та викликів, вимагаючи свідомої інтеграції технологічної етики та прозорості.












