
Етика
Сучасні методи штучного інтелекту можуть створити нове покоління авторських тролів

Нова дослідницька співпраця між Huawei та академічними колами свідчить про те, що велика частина найважливіших поточних досліджень у галузі штучного інтелекту та машинного навчання може бути піддана судовому розгляду, як тільки вона стане комерційно помітною, оскільки набори даних, які роблять прориви можливими, поширюються з недійсними. ліцензії, які не відповідають оригінальним умовам загальнодоступних доменів, з яких було отримано дані.
По суті, це має два майже неминучі можливі результати: дуже успішні комерціалізовані алгоритми штучного інтелекту, які, як відомо, використовували такі набори даних, стануть майбутніми мішенями опортуністичних патентних тролів, чиї авторські права не поважалися під час збирання їхніх даних; і що організації та окремі особи зможуть використовувати ті самі правові вразливості, щоб протестувати проти розгортання або розповсюдження технологій машинного навчання, які вони вважають небажаними.
Команда папір має титул Чи можу я використовувати цей загальнодоступний набір даних для створення комерційного програмного забезпечення ШІ? Швидше за все ні, і є результатом співпраці між Huawei Canada і Huawei China, а також Йоркським університетом у Великій Британії та Університетом Вікторії в Канаді.
П’ять із шести (популярних) наборів даних із відкритим вихідним кодом, які не можна використовувати на законних підставах
Для дослідження автори попросили департаменти Huawei вибрати найбільш бажані набори даних з відкритим кодом, які вони хотіли б використовувати в комерційних проектах, і вибрали шість найбільш затребуваних наборів даних із відповідей: ЦИФАР-10 (підмножина 80 мільйонів маленьких зображень набір даних, оскільки вилучено для «принизливих термінів» і «образливих зображень», хоча їх похідні поширюються); IMAGEnet; Міські пейзажі (який містить виключно оригінальний матеріал); FFHQ; VGGFace2 та MSCOCO.
Щоб проаналізувати, чи були вибрані набори даних придатними для законного використання в комерційних проектах, автори розробили новий конвеєр для відстеження ланцюга ліцензій, наскільки це було можливо для кожного набору, хоча їм часто доводилося вдаватися до записів веб-архіву, щоб знаходити ліцензії з доменів, термін дії яких закінчився, і в деяких випадках доводилося «вгадувати» статус ліцензії з найближчої доступної інформації.
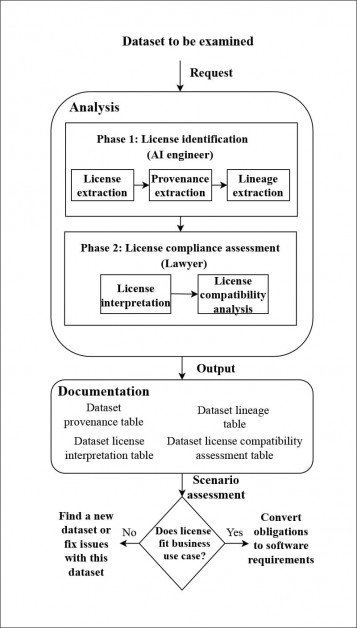
Архітектура для системи відстеження походження, розроблена авторами. Джерело: https://arxiv.org/pdf/2111.02374.pdf
Автори виявили, що ліцензії на п’ять із шести наборів даних "містить ризики, пов'язані принаймні з одним комерційним контекстом використання":
«[Ми] помічаємо, що, окрім MS COCO, жодна з досліджених ліцензій не дає фахівцям права комерціалізувати модель ШІ, навчену на даних або навіть на результатах навченої моделі ШІ. Такий результат також ефективно заважає практикам навіть використовувати попередньо навчені моделі, навчені на цих наборах даних. Загальнодоступні набори даних і попередньо навчені на них моделі ШІ є широко використовується в комерційних цілях.' *
Крім того, автори зазначають, що три з шести досліджених наборів даних можуть додатково призвести до порушення ліцензії на комерційні продукти, якщо набір даних буде змінено, оскільки це дозволяє лише MS-COCO. Проте збільшення даних, а також підмножини та супернабори впливових наборів даних є звичайною практикою.
У випадку CIFAR-10 оригінальні компілятори взагалі не створили жодної звичайної форми ліцензії, лише вимагаючи, щоб проекти, які використовують набір даних, включали цитату до оригінальної статті, яка супроводжувала випуск набору даних, створюючи подальшу перешкоду для встановлення правовий статус даних.
Крім того, лише набір даних CityScapes містить матеріал, створений винятково авторами набору даних, а не «підібраний» (зібраний) із мережевих джерел, за допомогою CIFAR-10 та ImageNet із використанням кількох джерел, кожне з яких потребує дослідження. і простежити назад, щоб встановити будь-який механізм авторського права (або навіть значущу відмову від відповідальності).
No Way Out
Існує три фактори, на які комерційні компанії штучного інтелекту, здається, покладаються, щоб захистити себе від судових процесів навколо продуктів, які вільно та без дозволу використовували захищений авторським правом вміст із наборів даних для навчання алгоритмів штучного інтелекту. Жоден із них не забезпечує значного (або будь-якого) надійного довгострокового захисту:
1: Національне законодавство Laissez Faire
Хоча уряди в усьому світі змушені пом’якшити закони щодо збирання даних, щоб не відступати в гонці за продуктивний штучний інтелект (який покладається на великі обсяги реальних даних, для яких регулярне дотримання авторських прав і ліцензування було б нереальним), лише Сполучені Штати пропонують повноцінний імунітет у цьому відношенні згідно з Доктрина добросовісного використання – політика, яка була ратифікована в 2015 році з висновок Гільдії авторів проти Google, Inc., яка підтвердила, що пошуковий гігант міг вільно завантажувати захищений авторським правом матеріал для свого проекту Google Books, не будучи звинуваченим у порушенні.
Якщо політика Доктрини добросовісного використання коли-небудь зміниться (тобто у відповідь на іншу знакову справу, пов’язану з достатньо владними організаціями чи корпораціями), це, ймовірно, вважатиметься апріорний держава з точки зору використання поточних баз даних, що порушують авторські права, захисту попереднього використання; але не постійний використання та розвиток систем, які були включені через матеріал, захищений авторським правом, без угоди.
Це ставить поточний захист Доктрини добросовісного використання на дуже тимчасову основу, і в цьому сценарії потенційно може знадобитися припинення роботи встановлених комерціалізованих алгоритмів машинного навчання у випадках, коли їхнє походження було дозволено захищеним авторським правом матеріалом – навіть у випадках, коли моделі вагами зараз мають справу виключно з дозволеним вмістом, але пройшли підготовку щодо незаконно скопійованого вмісту (і зробили його корисним).
За межами США, як зазначають автори в новій статті, політика, як правило, менш м’яка. Велика Британія та Канада відшкодовують лише використання даних, захищених авторським правом, у некомерційних цілях, тоді як Закон ЄС про інтелектуальний аналіз тексту та даних (який не був повністю скасований останні пропозиції для більш формального регулювання штучного інтелекту) також виключає комерційне використання систем штучного інтелекту, які не відповідають вимогам авторського права на вихідні дані.
Ці останні домовленості означають, що організація може досягти великих результатів з даними інших людей, аж до того, щоб заробити на цьому гроші, але не включно. На цьому етапі продукт або стане юридично викритим, або потрібно буде укласти домовленості буквально з мільйонами власників авторських прав, багатьох із яких зараз неможливо відстежити через мінливий характер Інтернету – неможлива та недосяжна перспектива.
2: Застереження Emptor
У випадках, коли організації-порушники сподіваються відкласти провину, у новому документі також зазначено, що багато ліцензій на найпопулярніші набори даних з відкритим кодом автоматично захищають себе від будь-яких претензій щодо порушення авторських прав:
«Наприклад, ліцензія ImageNet прямо вимагає від практиків відшкодовувати команду ImageNet від будь-яких претензій, пов’язаних із використанням набору даних. Набори даних FFHQ, VGGFace2 і MS COCO вимагають, щоб набір даних, якщо він розповсюджується чи змінювався, надавався за тією самою ліцензією».
По суті, це змушує тих, хто використовує набори даних FOSS, брати на себе провину за використання матеріалів, захищених авторським правом, перед обличчям можливого судового розгляду (хоча це не обов’язково захищає оригінальних компіляторів у випадку, коли наявна атмосфера «безпечної гавані»).
3: Відшкодування через невідомість
Спільний характер спільноти машинного навчання робить досить складним використання корпоративного окультизму для приховування присутності алгоритмів, які отримали вигоду від наборів даних, що порушують авторські права. Довгострокові комерційні проекти часто починаються у відкритих середовищах FOSS, де використання наборів даних є справою запису, на GitHub та інших загальнодоступних форумах, або де походження проекту було опубліковано в препринтах або рецензованих статтях.
Навіть там, де це не так, інверсія моделі is все більш здібним виявлення типових характеристик наборів даних (або навіть явно виводити деякі з вихідних матеріалів), або надає докази самі по собі, або достатню підозру щодо порушення, щоб отримати доступ за рішенням суду до історії розробки алгоритму та деталей наборів даних, які використовувалися в цій розробці.
Висновок
У документі зображено хаотичне та спеціальне використання захищеного авторським правом матеріалу, отриманого без дозволу, а також низку ліцензійних ланцюжків, які, логічно випливаючи з початкового джерела даних, вимагали б переговорів із тисячами власників авторських прав, чия робота була представлена під егідою сайтів із різноманітними умовами ліцензування, багато з яких виключають похідні комерційні роботи.
Автори роблять висновок:
«Загальнодоступні набори даних широко використовуються для створення комерційного програмного забезпечення ШІ. Це можна зробити, якщо [і] лише якщо ліцензія, пов’язана із загальнодоступним набором даних, надає право на це. Проте непросто перевірити права та обов’язки, передбачені ліцензією, пов’язаною з загальнодоступними наборами даних. Тому що інколи ліцензія або незрозуміла, або потенційно недійсна».
Ще одна нова робота під назвою Створення юридичних наборів даних, опублікований 2 листопада Центром обчислювального права Сінгапурського університету менеджменту, також наголошується на тому, що дослідники даних повинні визнати, що ера «дикого заходу» спеціального збору даних добігає кінця, і відображає рекомендації Huawei документ для прийняття більш суворих звичок і методологій, щоб гарантувати, що використання набору даних не наражає проект на юридичні наслідки, оскільки культура змінюється з часом, і оскільки поточна глобальна академічна діяльність у секторі машинного навчання прагне отримати комерційну віддачу від років інвестицій . Автор зауважує*:
«Кількість законодавчих актів, що впливають на набори даних ML, буде зростати на тлі занепокоєння, яке викликає чинне законодавство недостатньо гарантії. Проект ОВД [Закон ЄС про штучний інтелект], якщо і коли буде прийнято, суттєво змінить ландшафт ШІ та управління даними; інші юрисдикції можуть наслідувати цей приклад із своїми власними законами. '
* Моє перетворення вбудованих цитат на гіперпосилання















