
АИ 101
Шта је смањење димензионалности?
Шта је смањење димензионалности?
Смањење димензионалности је процес који се користи за смањење димензионалности скупа података, узимајући многе карактеристике и представљајући их као мање карактеристика. На пример, смањење димензионалности се може користити за смањење скупа података од двадесет функција на само неколико карактеристика. Редукција димензионалности се обично користи у учење без надзора задатака за аутоматско креирање класа од многих функција. У циљу бољег разумевања зашто и како се користи редукција димензионалности, погледаћемо проблеме повезане са подацима високих димензија и најпопуларније методе смањења димензионалности.
Више димензија доводи до претеривања
Димензионалност се односи на број карактеристика/колона унутар скупа података.
Често се претпоставља да је у машинском учењу више функција боље, јер ствара тачнији модел. Међутим, више функција не значи нужно бољи модел.
Карактеристике скупа података могу увелико варирати у погледу тога колико су корисне за модел, при чему су многе карактеристике од мале важности. Поред тога, што више функција скуп података садржи, потребно је више узорака да би се осигурало да су различите комбинације карактеристика добро представљене у подацима. Због тога се број узорака повећава пропорционално са бројем карактеристика. Више узорака и више карактеристика значи да модел мора да буде сложенији, а како модели постају сложенији, они постају осетљивији на прекомерно прилагођавање. Модел превише добро учи обрасце у подацима о обуци и не успева да генерализује податке ван узорка.
Смањење димензионалности скупа података има неколико предности. Као што је поменуто, једноставнији модели су мање склони преоптерећењу, јер модел мора да прави мање претпоставки о томе како су карактеристике повезане једна са другом. Поред тога, мање димензија значи да је потребна мања рачунарска снага за обуку алгоритама. Слично, потребно је мање простора за складиштење за скуп података који има мању димензију. Смањење димензионалности скупа података такође вам може омогућити да користите алгоритме који нису погодни за скупове података са много функција.
Уобичајене методе смањења димензија
Смањење димензионалности може бити избором карактеристика или инжењерингом карактеристика. Избор карактеристика је место где инжењер идентификује најрелевантније карактеристике скупа података, док инжењеринг карактеристика је процес стварања нових карактеристика комбиновањем или трансформацијом других карактеристика.
Избор карактеристика и инжењеринг се могу обавити програмски или ручно. Када се ручно бирају и конструишу карактеристике, визуализација података ради откривања корелација између карактеристика и класа је типична. Спровођење смањења димензионалности на овај начин може бити прилично дуготрајно и стога неки од најчешћих начина смањења димензионалности укључују коришћење алгоритама доступних у библиотекама као што је Сцикит-леарн за Питхон. Ови уобичајени алгоритми за смањење димензионалности укључују: анализу главних компоненти (ПЦА), декомпозицију сингуларне вредности (СВД) и линеарну дискриминантну анализу (ЛДА).
Алгоритми који се користе у смањењу димензионалности за задатке учења без надзора су обично ПЦА и СВД, док су они који се користе за смањење димензионалности надгледаног учења типично ЛДА и ПЦА. У случају модела учења под надзором, новогенерисане карактеристике се само уносе у класификатор машинског учења. Имајте на уму да су употребе описане овде само општи случајеви употребе, а не једини услови у којима се ове технике могу користити. Горе описани алгоритми за смањење димензионалности су једноставно статистичке методе и користе се изван модела машинског учења.
Главни анализа компоненти

Фотографија: Матрица са идентификованим главним компонентама
Анализа главне компоненте (ПЦА) је статистичка метода која анализира карактеристике/карактеристике скупа података и сумира карактеристике које су најутицајније. Карактеристике скупа података се комбинују заједно у репрезентације које одржавају већину карактеристика података, али су распоређене на мање димензија. О овоме можете размишљати као о „гњечењу“ података са више димензија на приказ са само неколико димензија.
Као пример ситуације у којој би ПЦА могао бити користан, размислите о различитим начинима на које се може описати вино. Иако је могуће описати вино користећи многе врло специфичне карактеристике као што су нивои ЦО2, нивои аерације, итд., такве специфичне карактеристике могу бити релативно бескорисне када покушавате да идентификујете одређену врсту вина. Уместо тога, било би мудрије идентификовати тип на основу општијих карактеристика као што су укус, боја и старост. ПЦА се може користити за комбиновање специфичнијих карактеристика и креирање функција које су општије, корисније и мање је вероватно да ће изазвати преоптерећење.
ПЦА се спроводи тако што се утврђује како улазне карактеристике варирају од средње вредности једна у односу на другу, утврђујући да ли постоје везе између карактеристика. Да би се ово урадило, креира се коваријантна матрица, успостављајући матрицу састављену од коваријанси у односу на могуће парове карактеристика скупа података. Ово се користи за одређивање корелације између варијабли, при чему негативна коваријанса указује на инверзну корелацију и позитивну корелацију која указује на позитивну корелацију.
Главне (најутицајније) компоненте скупа података се креирају креирањем линеарних комбинација почетних варијабли, што се ради уз помоћ концепата линеарне алгебре тзв. сопствених вредности и сопствених вектора. Комбинације су креиране тако да главне компоненте нису у корелацији једна са другом. Већина информација садржаних у почетним варијаблама је компримована у првих неколико главних компоненти, што значи да су креиране нове карактеристике (главне компоненте) које садрже информације из оригиналног скупа података у мањем димензионалном простору.
Декомпозиција сингуларне вредности
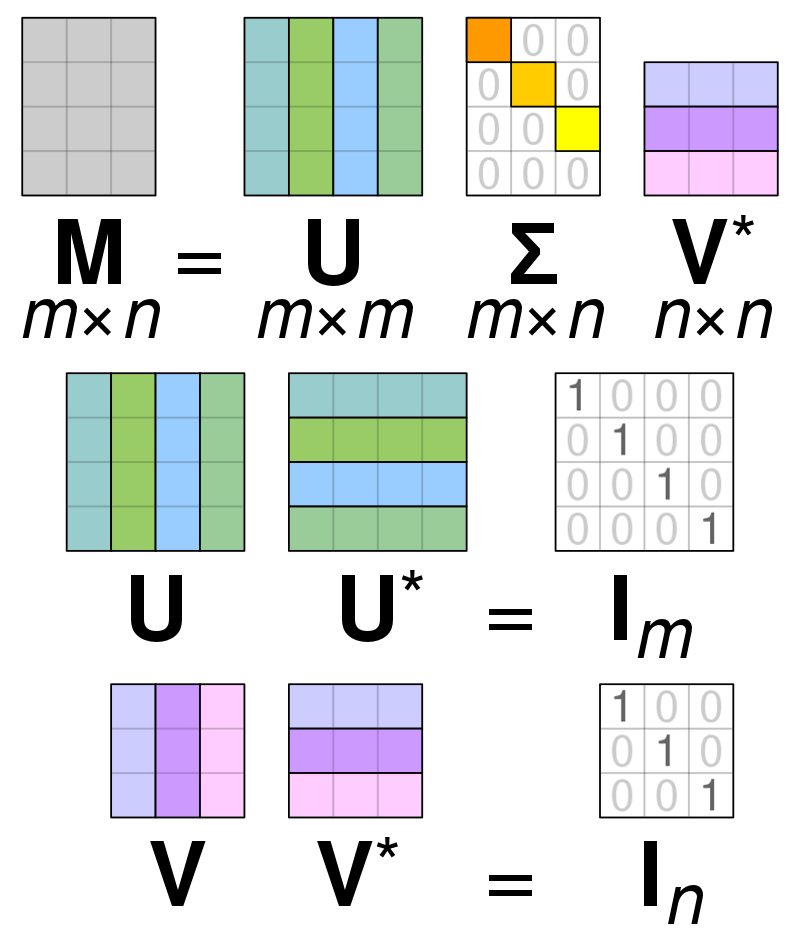
Фотографија: Аутор Цмглее – Сопствени рад, ЦЦ БИ-СА 4.0, хттпс://цоммонс.викимедиа.орг/в/индек.пхп?цурид=67853297
Декомпозиција сингуларне вредности (СВД) is користи се за поједностављење вредности унутар матрице, сводећи матрицу на њене саставне делове и олакшавајући прорачуне са том матрицом. СВД се може користити и за матрице реалне вредности и за комплексне матрице, али за потребе овог објашњења, испитаће се како декомпоновати матрицу стварних вредности.
Претпоставимо да имамо матрицу састављену од података стварне вредности и наш циљ је да смањимо број колона/карактера унутар матрице, слично циљу ПЦА. Као и ПЦА, СВД ће компримовати димензионалност матрице уз очување што је могуће веће варијабилности матрице. Ако желимо да радимо на матрици А, можемо да представимо матрицу А као три друге матрице које се зову У, Д и В. Матрица А се састоји од оригиналних к * и елемената док се матрица У састоји од елемената Кс * Кс (то је ортогонална матрица). Матрица В је другачија ортогонална матрица која садржи и * и елемената. Матрица Д садржи елементе к * и и то је дијагонална матрица.
Да бисмо декомпоновали вредности за матрицу А, морамо да конвертујемо оригиналне вредности сингуларне матрице у вредности дијагонале које се налазе унутар нове матрице. Када се ради са ортогоналним матрицама, њихова својства се не мењају ако се помноже другим бројевима. Према томе, можемо апроксимирати матрицу А користећи предност ове особине. Када помножимо ортогоналне матрице заједно са транспозицијом матрице В, резултат је еквивалентна матрица нашој оригиналној А.
Када се матрица а разложи на матрице У, Д и В, оне садрже податке који се налазе у матрици А. Међутим, крајње леве колоне матрице ће садржати већину података. Можемо узети само ових првих неколико колона и имати репрезентацију матрице А која има далеко мање димензија и већину података унутар А.
Линеарна дискриминантна анализа

Лево: Матрица пре ЛДА, Десно: Оса после ЛДА, сада одвојива
Линеарна дискриминантна анализа (ЛДА) је процес који узима податке из вишедимензионалног графа и поново пројектује на линеарни граф. Ово можете замислити размишљајући о дводимензионалном графикону испуњеном тачкама података које припадају две различите класе. Претпоставимо да су тачке разбацане унаоколо тако да се не може повући линија која ће уредно одвојити две различите класе. Да би се решила ова ситуација, тачке које се налазе на 2Д графу могу се свести на 1Д график (линија). Ова линија ће имати све тачке података распоређене по њој и надамо се да се може поделити на два дела која представљају најбоље могуће раздвајање података.
Приликом спровођења ЛДА постоје два основна циља. Први циљ је минимизирање варијансе за класе, док је други циљ максимизирање удаљености између средњих вредности две класе. Ови циљеви се постижу креирањем нове осе која ће постојати у 2Д графикону. Новостворена осовина делује да одвоји две класе на основу претходно описаних циљева. Након што је оса креирана, тачке пронађене на 2Д графу се постављају дуж осе.
Потребна су три корака за померање оригиналних тачака на нову позицију дуж нове осе. У првом кораку, растојање између појединачних класа (варијанса између класа) се користи за израчунавање одвојивости класа. У другом кораку израчунава се варијанса унутар различитих класа, одређивањем растојања између узорка и средње вредности за дотичну класу. У последњем кораку, ствара се нижедимензионални простор који максимизира варијансу између класа.
ЛДА техника постиже најбоље резултате када су средства за циљне класе удаљена једно од другог. ЛДА не може ефикасно да одвоји класе линеарном осом ако се средства за дистрибуције преклапају.










