
АИ 101
Шта је линеарна регресија?
Шта је линеарна регресија?
Линеарна регресија је алгоритам који се користи за предвиђање или визуелизацију а однос између две различите карактеристике/варијабле. У задацима линеарне регресије, постоје две врсте варијабли које се испитују: тхе зависна варијабла и независна варијабла. Независна променљива је променљива која стоји сама за себе, на коју друга променљива не утиче. Како се независна променљива прилагођава, нивои зависне варијабле ће флуктуирати. Зависна варијабла је променљива која се проучава, и то је оно за шта регресиони модел решава/покушава да предвиди. У задацима линеарне регресије, свако посматрање/инстанца се састоји од вредности зависне променљиве и вредности независне променљиве.
То је било брзо објашњење линеарне регресије, али хајде да се уверимо да ћемо боље разумети линеарну регресију тако што ћемо погледати њен пример и испитати формулу коју она користи.
Разумевање линеарне регресије
Претпоставимо да имамо скуп података који покрива величине чврстих дискова и цену тих чврстих дискова.
Претпоставимо да се скуп података који имамо састоји од две различите карактеристике: количине меморије и цене. Што више меморије купимо за рачунар, цена куповине расте. Ако бисмо исцртали појединачне тачке података на дијаграму расипања, могли бисмо добити графикон који изгледа отприлике овако:

Тачан однос меморије и цене може да варира између произвођача и модела чврстог диска, али генерално, тренд података је онај који почиње у доњем левом углу (где су чврсти дискови и јефтинији и имају мањи капацитет) и прелази на горњи десни (где су дискови скупљи и имају већи капацитет).
Ако бисмо имали количину меморије на Кс-оси и цену на И-оси, линија која обухвата однос између Кс и И променљивих почела би у доњем левом углу и водила би се у горњем десном углу.
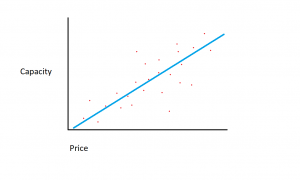
Функција регресионог модела је да одреди линеарну функцију између променљивих Кс и И која најбоље описује однос између две променљиве. У линеарној регресији, претпоставља се да се И може израчунати из неке комбинације улазних променљивих. Однос између улазних варијабли (Кс) и циљних варијабли (И) може се приказати цртањем линије кроз тачке на графикону. Линија представља функцију која најбоље описује однос између Кс и И (на пример, сваки пут када се Кс повећа за 3, И се повећа за 2). Циљ је пронаћи оптималну „лињу регресије“ или линију/функцију која најбоље одговара подацима.
Линије су типично представљене једначином: И = м*Кс + б. Кс се односи на зависну променљиву док је И независна варијабла. У међувремену, м је нагиб линије, како је дефинисано „успоном“ преко „трчања“. Практичари машинског учења представљају познату једначину нагибне линије мало другачије, користећи ову једначину:
и(к) = в0 + в1 * к
У горњој једначини, и је циљна променљива, док су „в“ параметри модела, а улаз је „к“. Дакле, једначина се чита као: „Функција која даје И, у зависности од Кс, једнака је параметрима модела помноженим карактеристикама“. Параметри модела се прилагођавају током тренинга да би се добила најприкладнија линија регресије.
Вишеструка линеарна регресија

Фотографија: Цбаф преко Викимедиа Цоммонс, јавни домен (хттпс://цоммонс.викимедиа.орг/вики/Филе:2д_мултипле_линеар_регрессион.гиф)
Горе описани процес се примењује на једноставну линеарну регресију или регресију на скупове података где постоји само једна карактеристика/независна променљива. Међутим, регресија се такође може урадити са више функција. У случају "вишеструка линеарна регресија“, једначина је проширена бројем варијабли које се налазе унутар скупа података. Другим речима, док је једначина за редовну линеарну регресију и(к) = в0 + в1 * к, једначина за вишеструку линеарну регресију би била и(к) = в0 + в1к1 плус тежине и инпути за различите карактеристике. Ако укупан број тежина и карактеристика представимо као в(н)к(н), онда бисмо формулу могли да представимо овако:
и(к) = в0 + в1к1 + в2к2 + … + в(н)к(н)
Након успостављања формуле за линеарну регресију, модел машинског учења ће користити различите вредности за тежине, цртајући различите линије уклапања. Запамтите да је циљ пронаћи линију која најбоље одговара подацима како бисте утврдили која од могућих комбинација тежине (а самим тим и која могућа линија) најбоље одговара подацима и објасни однос између варијабли.
Функција трошкова се користи за мерење колико су претпостављене вредности И блиске стварним вредностима И када им је дата одређена вредност тежине. Функција трошкова за линеарну регресију је средња квадратна грешка, која само узима просечну (квадратску) грешку између предвиђене вредности и праве вредности за све различите тачке података у скупу података. Функција трошкова се користи за израчунавање трошкова, која обухвата разлику између предвиђене циљне вредности и праве циљне вредности. Ако је линија уклапања удаљена од тачака података, цена ће бити већа, док ће цена бити све мања што се линија приближава хватању правих односа између варијабли. Тежине модела се затим прилагођавају док се не пронађе конфигурација тежине која производи најмању количину грешке.










