Искусственный интеллект
В сторону реального времени AI людей с помощью рендеринга Neural Lumigraph

Несмотря на текущую волну интереса к Neural Radiance Fields (NeRF), технологии, способной создавать AI-генерируемые 3D-окружения и объекты, этот новый подход к технологии синтеза изображений все еще требует большого количества времени обучения и не имеет реализации, которая позволяет создавать интерфейсы реального времени, высокоотзывчивые.
Однако сотрудничество между некоторыми впечатляющими именами в промышленности и академии предлагает новый взгляд на эту проблему (известную как Novel View Synthesis, или NVS).
Исследовательская работа, озаглавленная Neural Lumigraph Rendering, утверждает, что достигла улучшения состояния дел на два порядка, представляя несколько шагов к реальному времени CG-рендерингу через машинные обучающие трубопроводы.

Neural Lumigraph Rendering (справа) предлагает лучшее разрешение артефактов смешивания и улучшенное обработка окуляции по сравнению с предыдущими методами. Source.
Хотя упоминания о работе цитируют только Стэнфордский университет и компанию Raxium (в настоящее время работающую в режиме скрытности), в качестве участников упоминаются главный архитектор машинного обучения в Google, компьютерный ученый в Adobe и технический директор в StoryFile (которая недавно попала в заголовки с AI-версией Уильяма Шетнера).
В отношении недавнего Шетнера, StoryFile, кажется, использует NLR в своей новой процедуре создания интерактивных, AI-генерируемых сущностей на основе характеристик и нарративов отдельных людей.
StoryFile предвидит использование этой технологии в музейных экспозициях, интерактивных нарративах, голографических дисплеях, дополненной реальности (AR) и документации наследия – и также, кажется, рассматривает потенциальные новые применения NLR в интервью при приеме на работу и виртуальных свиданиях:

Предлагаемые применения из онлайн-видео StoryFile. Source: https://www.youtube.com/watch?v=2K9J6q5DqRc
Волюметрическая запись для интерфейсов Novel View Synthesis и видео
Принцип волюметрической записи, в ряде работ, которые накапливаются на эту тему, является идеей взять статические изображения или видео объекта и использовать машинное обучение для “заполнения” точек зрения, которые не были покрыты исходным массивом камер.
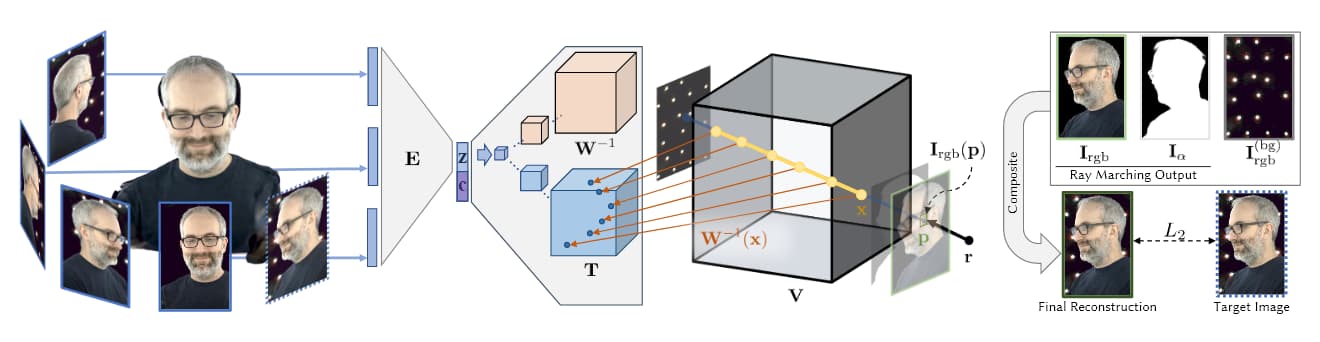
Source: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
На изображении выше, взятом из исследования AI Facebook 2019 года (см. ниже), мы видим четыре этапа волюметрической записи: несколько камер получают изображения/видео; архитектура кодирования/декодирования (или другие архитектуры) рассчитывают и объединяют относительность точек зрения; алгоритмы маршрутизации лучей рассчитывают воксели (или другие XYZ пространственные геометрические единицы) каждой точки в волюметрическом пространстве; и (в большинстве недавних работ) происходит обучение для синтеза полной сущности, которую можно манипулировать в реальном времени.
Это часто обширная и трудоемкая фаза обучения, которая, до сих пор, держала Novel View Synthesis вне области реального времени или высокоотзывчивого захвата.
Тот факт, что Novel View Synthesis создает полную 3D-карту волюметрического пространства, означает, что относительно просто склеить эти точки вместе в традиционную компьютерную сетку, эффективно захватывая и артикулируя CGI-человека (или любой другой относительно ограниченный объект) на лету.
Подходы, которые используют NeRF, полагаются на облака точек и карты глубины для генерации интерполяций между разреженными точками зрения устройств захвата:

NeRF может генерировать волюметрическую глубину путем расчета карт глубины, а не генерации CG-сеток. Source: https://www.youtube.com/watch?v=JuH79E8rdKc
Хотя NeRF способен рассчитывать сетки, большинство реализаций не используют это для генерации волюметрических сцен.
Напротив, подход Implicit Differentiable Renderer (IDR), опубликованный Институтом Вейцмана в октябре 2020 года, основан на использовании 3D-сеточной информации, автоматически сгенерированной из массивов захвата:

Примеры IDR-захватов, превращенных в интерактивные CGI-сетки. Source: https://www.youtube.com/watch?v=C55y7RhJ1fE
Хотя NeRF не имеет возможности IDR для оценки формы, IDR не может сравниться с NeRF по качеству изображения, и оба требуют обширных ресурсов для обучения и сбора (хотя недавние инновации в NeRF начинают решать эту проблему).

Пользовательская камера NLR с 16 камерами GoPro HERO7 и 6 центральными камерами Back-Bone H7PRO. Для рендеринга в реальном времени они работают с минимальной частотой 60 кадров в секунду. Source: https://arxiv.org/pdf/2103.11571.pdf
Вместо этого Neural Lumigraph Rendering использует SIREN (Синусоидальные представления сетей), чтобы объединить сильные стороны каждого подхода в своей собственной рамке, которая предназначена для генерации вывода, который можно直接 использовать в существующих трубопроводах реального времени графики.
SIREN использовался для podobных реализаций в течение последнего года и теперь представляет собой популярный API-запрос для хобби-Colabs в сообществах синтеза изображений; однако инновация NLR заключается в применении SIREN к двумерному многообразному изображению надзора, что проблематично из-за степени, в которой SIREN производит переобученные, а не обобщенные выводы.
После того, как CG-сетка извлекается из массива изображений, сетка растеризуется через OpenGL, и позиции вершин сетки сопоставляются с соответствующими пикселями, после чего рассчитывается смешивание различных вкладывающих карт.
Результирующая сетка более обобщена и представительна, чем у NeRF (см. изображение ниже), требует меньше расчетов и не применяет чрезмерные детали к областям (таким как гладкая кожа лица), которые не могут извлечь выгоду из этого:

Source: https://arxiv.org/pdf/2103.11571.pdf
С отрицательной стороны, NLR пока не имеет возможности для динамического освещения или переосвещения, и вывод ограничен теневыми картами и другими соображениями освещения, полученными во время захвата. Исследователи намерены решить эту проблему в будущей работе.
Кроме того, работа признает, что формы, сгенерированные NLR, не так точны, как некоторые альтернативные подходы, такие как Pixelwise View Selection for Unstructured Multi-View Stereo, или исследование Института Вейцмана, упомянутое ранее.
Восхождение волюметрического синтеза изображений
Идея создания 3D-сущностей из ограниченной серии фотографий с помощью нейронных сетей предшествует NeRF, с видными работами, восходящими к 2007 году или ранее. В 2019 году исследовательский отдел AI Facebook произвел фундаментальную исследовательскую работу, Neural Volumes: Learning Dynamic Renderable Volumes from Images, которая впервые позволила создавать интерактивные интерфейсы для синтетических людей, сгенерированных машинным обучением на основе волюметрического захвата.

Исследование Facebook 2019 года позволило создать интерактивный интерфейс для волюметрического человека. Source: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/












