Искусственный интеллект
Революционизация здравоохранения: Изучение влияния и будущего крупномасштабных языковых моделей в медицине

Интеграция и применение крупномасштабных языковых моделей (LLM) в медицине и здравоохранении стали темой значительного интереса и развития.
Как отмечено на конференции Healthcare Information Management and Systems Society и других заметных мероприятиях, компании như Google возглавляют движение по изучению потенциала генеративного ИИ в здравоохранении. Их инициативы, такие как Med-PaLM 2, подчеркивают эволюционирующий ландшафт решений для здравоохранения на основе ИИ, особенно в таких областях, как диагностика, уход за пациентами и административная эффективность.
Med-PaLM 2 от Google, пионерская LLM в области здравоохранения, продемонстрировала впечатляющие возможности, в частности, достигнув уровня “эксперта” в вопросах, подобных экзамену на медицинскую лицензию в США. Эта модель и другие подобные ей обещают революционизировать способ, которым медицинские специалисты получают доступ и используют информацию, потенциально повышая точность диагностики и эффективность ухода за пациентами.
Однако наряду с этими достижениями были высказаны опасения по поводу практичности и безопасности этих технологий в клинических условиях. Например, зависимость от обширных источников данных интернета для обучения моделей, хотя и полезна в некоторых контекстах, не всегда может быть подходящей или надежной для медицинских целей. Как Нигам Шах, PhD, MBBS, главный ученый-дата для Stanford Health Care, подчеркивает, что важными вопросами являются вопросы о производительности этих моделей в реальных медицинских условиях и их фактическом влиянии на уход за пациентами и эффективность здравоохранения.
Точка зрения доктора Шаха подчеркивает необходимость более целевой подхода к использованию LLM в медицине. Вместо моделей общего назначения, обученных на широких данных интернета, он предлагает более сосредоточенную стратегию, при которой модели обучаются на конкретных, актуальных медицинских данных. Этот подход напоминает обучение медицинского интерна – предоставление им конкретных задач, наблюдение за их работой и постепенное предоставление большей автономии по мере демонстрации компетентности.
В соответствии с этим, разработка Meditron исследователями EPFL представляет интересное достижение в этой области. Meditron, открытая LLM, специально разработанная для медицинских применений, представляет собой значительный шаг вперед. Обученная на отобранных медицинских данных из авторитетных источников, таких как PubMed и клинические рекомендации, Meditron предлагает более сосредоточенный и потенциально более надежный инструмент для медицинских практиков. Его открытая природа не только способствует прозрачности и сотрудничеству, но также позволяет проводить непрерывное улучшение и тестирование более широким исследовательским сообществом.

MEDITRON-70B-achieves-an-accuracy-of-70.2-on-USMLE-style-questions-in-the-MedQA-4-options-dataset
Разработка инструментов, таких как Meditron, Med-PaLM 2 и других, отражает растущее признание уникальных требований сектора здравоохранения в отношении применений ИИ. Акцент на обучении этих моделей на актуальных, высококачественных медицинских данных и обеспечении их безопасности и надежности в клинических условиях является очень важным.
Кроме того, включение разнообразных наборов данных, таких как те, которые получены из гуманитарных контекстов, chẳng hạn как Международный комитет Красного Креста, демонстрирует чувствительность к различным потребностям и проблемам в глобальном здравоохранении. Этот подход соответствует более широкой миссии многих исследовательских центров ИИ, которые стремятся создавать инструменты ИИ, которые являются не только технологически продвинутыми, но и социально ответственными и полезными.
Статья под названием “Крупномасштабные языковые модели кодируют клинические знания“, недавно опубликованная в Nature, исследует, как крупномасштабные языковые модели (LLM) могут быть эффективно использованы в клинических условиях. Исследование представляет новаторские идеи и методологии, проливая свет на возможности и ограничения LLM в медицинской области.
Медицинская область характеризуется своей сложностью, с огромным количеством симптомов, заболеваний и методов лечения, которые постоянно эволюционируют. LLM должны не только понимать эту сложность, но и идти в ногу с последними медицинскими знаниями и рекомендациями.
Ядро этого исследования вращается вокруг новой кураторской базы под названием MultiMedQA. Эта база объединяет шесть существующих наборов данных для медицинского вопрос-ответа с новым набором данных, HealthSearchQA, который состоит из медицинских вопросов, часто ищущихся в интернете. Этот комплексный подход направлен на оценку LLM по различным измерениям, включая фактичность, понимание, рассуждение, возможный вред и предвзятость, тем самым решая ограничения предыдущих автоматических оценок, которые полагались на ограниченные базы.
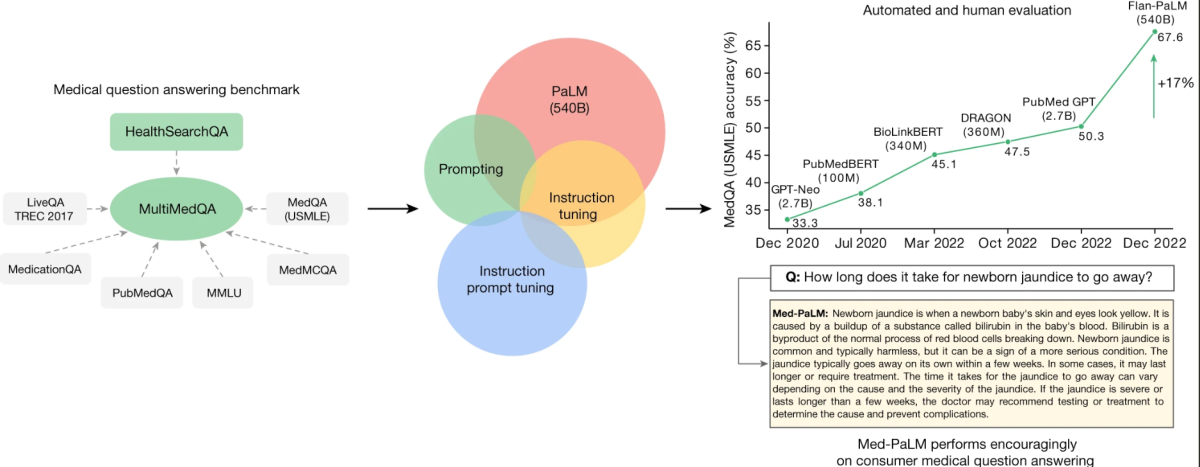
MultiMedQA, база для ответов на медицинские вопросы, охватывающую медицинский экзамен
Ключом к этому исследованию является оценка модели Pathways Language Model (PaLM), крупномасштабной LLM с 540 миллиардами параметров, и ее варианта, настроенного на инструкции, Flan-PaLM, на MultiMedQA. Заметно, что Flan-PaLM достигает лучшей точности на всех множественных выборах внутри MultiMedQA, включая точность 67,6% на MedQA, который состоит из вопросов, подобных экзамену на медицинскую лицензию в США. Это выступление отмечает значительное улучшение по сравнению с предыдущими моделями, превосходя предыдущий уровень более чем на 17%.
MedQA
Набор данных MedQA3 включает вопросы, стилизованные под USMLE, каждый с четырьмя или пятью вариантами ответа. Он включает набор разработки с 11 450 вопросами и тестовый набор, состоящий из 1 273 вопросов.
Формат: вопрос и ответ (Q + A), множественный выбор, открытая область.
Пример вопроса: 65-летний мужчина с гипертонией приходит к врачу для планового медицинского осмотра. Текущие лекарства включают атенолол, лизиноприл и аторвастатин. Его пульс составляет 86 мин-1, дыхание - 18 мин-1, а кровяное давление - 145/95 мм рт. ст. Кардиологический осмотр выявляет эндодиастолический шум. Какое из следующего является наиболее вероятной причиной этого физического осмотра?
Ответы (правильный ответ в жирном шрифте): (A) Снижение комплаенсности левого желудочка, (B) Миксоматозная дегенерация митрального клапана (C) Воспаление перикарда (D) Расширение аортального корня (E) Утолщение листков митрального клапана.
Исследование также выявляет критические пробелы в производительности модели, особенно в ответах на вопросы потребителей. Чтобы решить эти проблемы, исследователи вводят метод, известный как настройка инструктивного промпта. Этот метод эффективно выравнивает LLM с новыми областями, используя несколько примеров, в результате чего создается Med-PaLM. Модель Med-PaLM, хотя и показывает обнадеживающие результаты и демонстрирует улучшение в понимании, воспоминании знаний и рассуждении, все еще отстает от показателей клиницистов.
Заметным аспектом этого исследования является подробная оценка человека. Этот каркас оценивает ответы моделей на соответствие научному консенсусу и потенциальным вредным последствиям. Например, хотя только 61,9% ответов Flan-PaLM в длинной форме соответствовали научному консенсусу, эта цифра возросла до 92,6% для Med-PaLM, что сопоставимо с ответами, сгенерированными клиницистами. Аналогично, потенциал для вредных последствий был значительно снижен в ответах Med-PaLM по сравнению с Flan-PaLM.
Оценка человека ответов Med-PaLM подчеркнула ее профессионализм в нескольких областях, соответствуя тесно с ответами, сгенерированными клиницистами. Это подчеркивает потенциал Med-PaLM в качестве поддерживающего инструмента в клинических условиях.
Исследование, обсуждаемое выше, углубляется в тонкости улучшения крупномасштабных языковых моделей (LLM) для медицинских применений. Техники и наблюдения из этого исследования могут быть обобщены для улучшения возможностей LLM в различных областях. Давайте исследуем эти ключевые аспекты:
Настройка инструкции улучшает производительность
- Обобщенная применимость: Настройка инструкции, которая включает в себя тонкую настройку LLM с конкретными инструкциями или рекомендациями, показала значительное улучшение производительности в различных областях. Этот метод может быть применен к другим областям, таким как юридическая, финансовая или образовательная, для улучшения точности и актуальности выходных данных LLM.
Масштабирование размера модели
- Более широкие последствия: Наблюдение, что увеличение размера модели улучшает производительность, не ограничивается ответами на медицинские вопросы. Более крупные модели, с большим количеством параметров, имеют возможность обрабатывать и генерировать более тонкие и сложные ответы. Это масштабирование может быть полезным в областях, таких как обслуживание клиентов, творческое письмо и техническая поддержка, где нюансированное понимание и генерация ответов являются важными.
Цепочка мысли (COT) промптинг
- Использование в различных областях: Использование COT промптинга, хотя и не всегда улучшает производительность в медицинских наборах данных, может быть ценным в других областях, где требуется сложное решение проблем. Например, в технической поддержке или сложных сценариях принятия решений COT промптинг может направлять LLM, чтобы они обрабатывали информацию шаг за шагом, что приводит к более точным и обоснованным выходным данным.
Самосогласованность для повышения точности
- Более широкое применение: Техника самосогласованности, при которой генерируются несколько выходных данных и выбирается наиболее последовательный ответ, может значительно повысить производительность в различных областях. В областях, таких как финансы или право, где точность имеет первостепенное значение, этот метод может быть использован для перекрестной проверки сгенерированных выходных данных для повышения надежности.
Неопределенность и селективное предсказание
- Пересечение областей: Передача оценок неопределенности имеет решающее значение в областях, где дезинформация может иметь серьезные последствия, такие как здравоохранение и право. Использование возможности LLM выражать неопределенность и селективно откладывать предсказания, когда уверенность низка, может быть важным инструментом в этих областях для предотвращения распространения неточной информации.
Реальное применение этих моделей выходит за рамки ответов на вопросы. Они могут быть использованы для образования пациентов, помощи в диагностических процессах и даже в обучении медицинских студентов. Однако их развертывание должно быть тщательно управляемо, чтобы избежать зависимости от ИИ без надлежащего человеческого надзора.
По мере эволюции медицинских знаний LLM также должны адаптироваться и учиться. Это требует механизмов для непрерывного обучения и обновления, гарантируя, что модели остаются актуальными и точными с течением времени.












