Искусственный интеллект
Модельные маршрутизаторы и ловушка обратной связи: как ИИ учится на себе
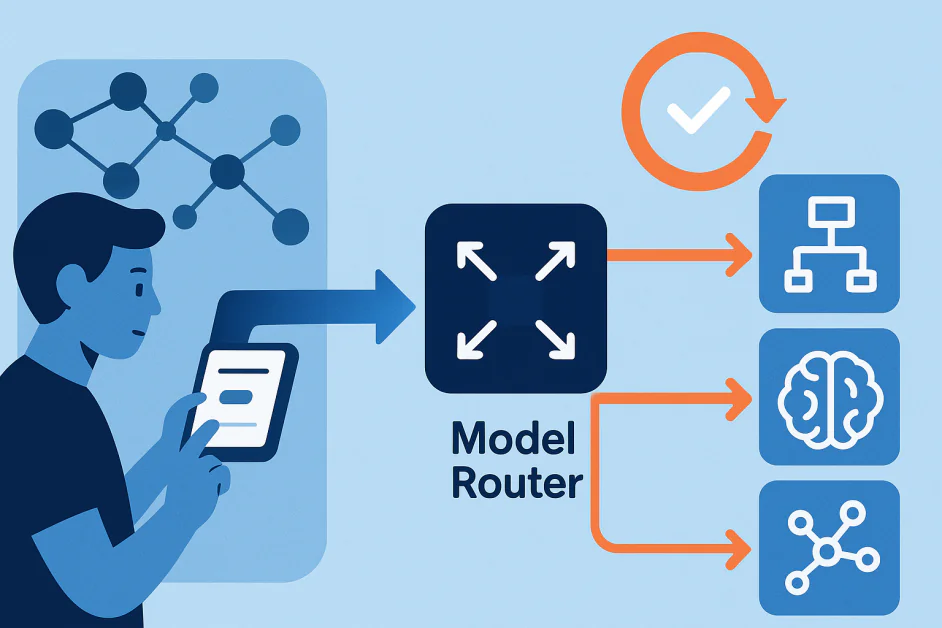
Современные системы ИИ больше не строятся вокруг единой модели, которая обрабатывает каждую задачу. Вместо этого они полагаются на коллекции моделей, каждая из которых предназначена для конкретных целей. В центре этой схемы находится модельный маршрутизатор, компонент, который интерпретирует запрос пользователя и решает, какая модель должна его обработать. Например, в системах như OpenAI’s GPT-5, маршрутизатор может отправить простой запрос на легковесную модель для скорости, а сложные задачи рассуждения маршрутизировать в более продвинутую модель.
Маршрутизаторы не только управляют трафиком. Они учатся на поведении пользователей, таком как когда люди переключаются между моделями или предпочитают определенные ответы. Это создает цикл: маршрутизатор назначает запрос, модель производит ответ, реакции пользователей предоставляют обратную связь, и маршрутизатор обновляет свои решения. Когда эти циклы работают тихо на заднем плане, они могут образовывать скрытые петли обратной связи. Такие петли могут усиливать предвзятость, укреплять ошибочные закономерности или постепенно снижать производительность способами, которые трудно обнаружить.
Эта статья рассматривает, как работают модельные маршрутизаторы, как возникают петли обратной связи и какие риски они представляют, когда системы ИИ продолжают эволюционировать.
Понимание модельных маршрутизаторов в ИИ
Модельный маршрутизатор является решающим слоем в многомодельной системе ИИ. Его роль заключается в определении, какая модель лучше всего подходит для задачи. Выбор зависит от факторов, таких как сложность запроса, намерение пользователя, контекст и компромиссы между стоимостью, точностью и скоростью.
В отличие от систем, которые следуют фиксированным правилам, большинство модельных маршрутизаторов являются системами машинного обучения сами по себе. Они обучаются на реальных сигналах и адаптируются со временем. Они могут учиться на поведении пользователей, таком как переключение между моделями, оценка ответов или перефразировка запросов, а также на автоматических оценках, которые измеряют качество вывода.
Эта адаптивность делает маршрутизаторы мощными, но также и рискованными. Они повышают эффективность и обеспечивают лучший опыт пользователя, но те же процессы обратной связи, которые уточняют их решения, также могут создавать петли обратной связи. Со временем эти петли могут повлиять не только на стратегии маршрутизации, но и на то, как вся система ИИ ведет себя.
Как образуются петли обратной связи
Петля обратной связи возникает, когда вывод системы влияет на данные, которые она позже учит. Простой пример – система рекомендаций: если вы кликаете на спортивное видео, система показывает вам больше спортивных материалов, что формирует то, что вы смотрите дальше. Со временем система укрепляет свои собственные закономерности. Другой пример, чтобы понять петлю обратной связи, – предсказательная полиция. Алгоритм может прогнозировать более высокую преступность в определенных районах, что может привести к более частым патрулям. Увеличенные патрули обнаруживают больше инцидентов, которые затем подтверждают прогноз алгоритма. Система выглядит точной, но данные искажены ее собственным влиянием. Петли обратной связи могут быть прямыми или скрытыми. Прямые петли легко распознаваемы, такие как система рекомендаций, которая переобучается на своих собственных предложениях. Скрытые петли более тонкие, потому что они возникают, когда разные части системы косвенно влияют друг на друга.
Модельные маршрутизаторы могут создавать подобные петли. Решение маршрутизатора формирует, какая модель производит ответ. Этот ответ формирует поведение пользователя, которое становится обратной связью для маршрутизатора. Со временем маршрутизатор может начать укреплять закономерности, которые работали в прошлом, а не постоянно выбирать лучшую модель. Эти петли трудно обнаружить и могут тихо толкать системы ИИ в непредвиденные направления.
Почему петли обратной связи в маршрутизаторах рискованны
Хотя петли обратной связи помогают маршрутизаторам улучшать сопоставление задач, они также несут риски, которые могут исказить поведение системы. Одним из рисков является укрепление первоначальных предвзятостей. Если маршрутизатор повторно отправляет определенный тип запроса в Модель А, большинство обратной связи будет поступать от вывода Модели А. Маршрутизатор может затем предположить, что Модель А всегда лучшая, отодвигая Модель Б, даже если она могла бы иногда работать лучше. Это неравное использование может стать самоукрепляющим. Модели, которые хорошо работают на маршрутизированных задачах, привлекают больше запросов, которые укрепляют их сильные стороны. Менее используемые модели получают меньше шансов улучшиться, создавая дисбаланс и снижая разнообразие.
Предвзятости также могут поступать от моделей оценки, используемых для оценки правильности. Если “судейская” модель имеет слепые пятна, ее предвзятости передаются напрямую маршрутизатору, который затем оптимизируется для ценностей судьи, а не для реальных потребностей пользователей. Поведение пользователя добавляет еще один уровень сложности. Если маршрутизатор склонен возвращать определенные стили ответов, пользователи могут адаптировать свои запросы, чтобы соответствовать этим закономерностям, еще больше укрепляя их. Со временем это может сузить как поведение пользователя, так и ответы системы. Маршрутизаторы также могут учиться ассоциировать определенные закономерности запросов или демографические группы с конкретными моделями. Это может привести к систематически разным опытам в разных группах, потенциально укрепляя и усиливая существующие социальные предвзятости.
Другой ключевой проблемой является долгосрочный дрейф. Решения, которые принимает маршрутизатор сегодня, влияют на обучающие данные, используемые завтра. Если модели переобучиваются на выводе, влиянии маршрутизации, они могут учиться предпочтениям маршрутизатора, а не независимым подходам. Это может сделать ответы более унифицированными и внедрить предвзятости, которые сохраняются со временем.
Стратегии разрыва цикла
Снижение рисков скрытых петель требует активного проектирования и надзора. Обучение должно использовать разнообразные источники данных, а не только клики пользователей или переключения. Случайное маршрутизация может также предотвратить монополизацию одной модели над типом задачи. Мониторинг имеет важное значение. Регулярные аудиты могут показать,是否 маршрутизатор смещается к определенным закономерностям или слишком сильно полагается на одну модель. Прозрачность решений маршрутизатора помогает исследователям обнаружить предвзятость на ранней стадии.
Маршрутизаторы также должны быть переобучены периодически с свежими, сбалансированными данными, чтобы старые предвзятости не стали запертыми. Включение человеческого надзора, особенно в чувствительных областях, добавляет еще один уровень ответственности. Люди могут определить, когда маршрутизатор систематически отдает предпочтение одной модели или неправильно классифицирует определенные запросы.
Ключевым моментом является то, чтобы рассматривать маршрутизатор как модель, подверженную обратной связи, а не как фиксированный или нейтральный компонент. Признавая, как маршрутизаторы сами формируются данными, которые они создают, исследователи и разработчики могут проектировать системы, которые остаются справедливыми, адаптивными и надежными со временем.
Основная мысль
Модельные маршрутизаторы предлагают явные преимущества в эффективности и адаптивности, но они также несут скрытые риски. Петли обратной связи внутри этих систем могут тихо усиливать предвзятость, ограничивать разнообразие ответов и блокировать модели в узкие закономерности поведения. Когда эти архитектуры становятся более распространенными, распознавание и устранение этих рисков на ранней стадии будет ключевым для построения систем ИИ, которые остаются справедливыми, надежными и действительно адаптивными.












