Искусственный интеллект
Встраивание кода: подробное руководство

Встраивание кода — это преобразующий способ представления фрагментов кода в виде плотных векторов в непрерывном пространстве. Эти внедрения фиксируют семантические и функциональные связи между фрагментами кода, позволяя создавать мощные приложения для программирования с помощью искусственного интеллекта. Подобно внедрению слов в обработке естественного языка (NLP), внедрение кода размещает схожие фрагменты кода близко друг к другу в векторном пространстве, что позволяет машинам более эффективно понимать код и манипулировать им.
Что такое встраивание кода?
Встраивание кода преобразует сложные структуры кода в числовые векторы, которые отражают смысл и функциональность кода. В отличие от традиционных методов, которые рассматривают код как последовательность символов, внедрения фиксируют семантические отношения между частями кода. Это имеет решающее значение для различных задач разработки программного обеспечения, управляемых искусственным интеллектом, таких как поиск кода, завершение, обнаружение ошибок и многое другое.
Например, рассмотрим эти две функции Python:
def add_numbers(a, b):
return a + b
def sum_two_values(x, y):
result = x + y
return result
Хотя синтаксически эти функции выглядят по-разному, они выполняют одну и ту же операцию. Хорошее встраивание кода должно представлять эти две функции с похожими векторами, отражая их функциональное сходство, несмотря на их текстовые различия.

Векторное встраивание
Как создаются встраивания кода?
Существуют различные методы создания вложений кода. Один из распространенных подходов предполагает использование нейронных сетей для изучения этих представлений на основе большого набора данных кода. Сеть анализирует структуру кода, включая токены (ключевые слова, идентификаторы), синтаксис (структуру кода) и, возможно, комментарии, чтобы узнать взаимосвязи между различными фрагментами кода.
Давайте разберем процесс:
- Код как последовательность: Во-первых, фрагменты кода рассматриваются как последовательности токенов (переменных, ключевых слов, операторов).
- Обучение нейронной сети: нейронная сеть обрабатывает эти последовательности и учится отображать их в векторные представления фиксированного размера. Сеть учитывает такие факторы, как синтаксис, семантика и отношения между элементами кода.
- Улавливайте сходства: Целью обучения является размещение похожих фрагментов кода (с похожей функциональностью) близко друг к другу в векторном пространстве. Это позволяет решать такие задачи, как поиск похожего кода или сравнение функциональности.
Вот упрощенный пример Python, показывающий, как можно предварительно обработать код для встраивания:
import ast
def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = []
for node in ast.walk(tree):
if isinstance(node, ast.Name):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# Add more node types as needed
return tokens
# Example usage
code = """
def greet(name):
print("Hello, " + name + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# Output: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']
Это токенизированное представление затем можно передать в нейронную сеть для встраивания.
Существующие подходы к внедрению кода
Существующие методы встраивания кода можно разделить на три основные категории:
Методы на основе токенов
Методы на основе токенов рассматривают код как последовательность лексических токенов. Такие методы, как частота терминов, обратная частота документов (TF-IDF), и модели глубокого обучения, такие как КодBERT попасть в эту категорию.
Древовидные методы
Древовидные методы анализируют код в абстрактные синтаксические деревья (AST) или другие древовидные структуры, фиксируя синтаксические и семантические правила кода. Примеры включают древовидные нейронные сети и такие модели, как код2век и АСТНН.
Методы на основе графов
Методы на основе графов создают графы из кода, такие как графы потоков управления (CFG) и графы потоков данных (DFG), для представления динамического поведения и зависимостей кода. ГрафКодBERT это яркий пример.
TransformCode: платформа для встраивания кода
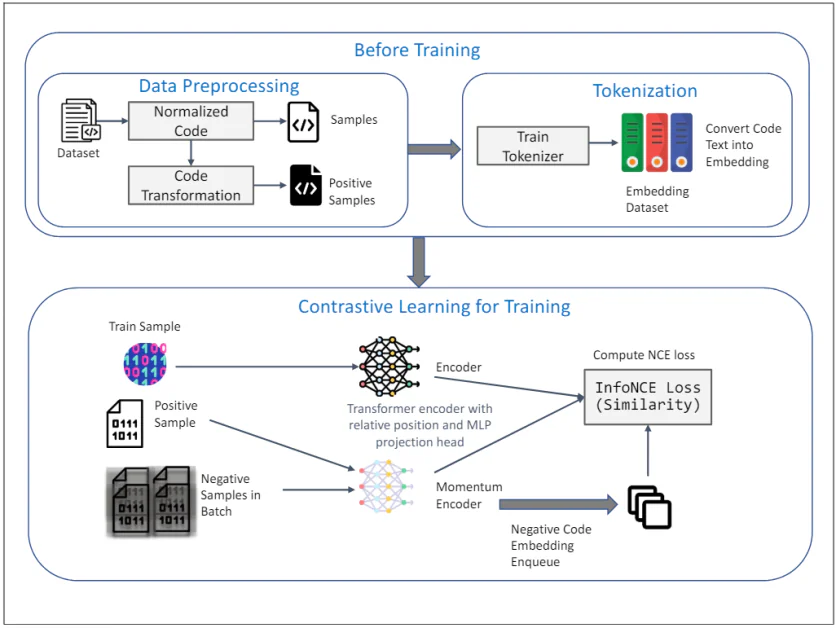
TransformCode: обучение внедрению кода без присмотра
Трансформкоде представляет собой структуру, которая устраняет ограничения существующих методов путем изучения встраивания кода методом контрастного обучения. Он не зависит от кодировщика и языка, что означает, что он может использовать любую модель кодера и обрабатывать любой язык программирования.
На диаграмме выше показана структура TransformCode для неконтролируемого обучения внедрению кода с использованием контрастного обучения. Он состоит из двух основных этапов: Перед тренировкой и Контрастное обучение для обучения. Вот подробное описание каждого компонента:
Перед тренировкой
1. Предварительная обработка данных:
- Набор данных: Исходные входные данные представляют собой набор данных, содержащий фрагменты кода.
- Нормализованный код: Фрагменты кода подвергаются нормализации для удаления комментариев и переименования переменных в стандартный формат. Это помогает уменьшить влияние именования переменных на процесс обучения и повышает обобщаемость модели.
- Преобразование кода: Затем нормализованный код преобразуется с использованием различных синтаксических и семантических преобразований для создания положительных образцов. Эти преобразования гарантируют, что семантическое значение кода остается неизменным, предоставляя разнообразные и надежные образцы для контрастного обучения.
2. Токенизация:
- Токенизатор поездов: Токенизатор обучается на наборе данных кода для преобразования текста кода во внедренные элементы. Это предполагает разбиение кода на более мелкие единицы, такие как токены, которые могут обрабатываться моделью.
- Встраивание набора данных: Обученный токенизатор используется для преобразования всего набора данных кода во встраивания, которые служат входными данными для этапа контрастного обучения.
Контрастное обучение для обучения
3. Процесс обучения:
- Образец поезда: В качестве представления кода запроса выбирается образец из набора обучающих данных.
- Положительный образец: Соответствующий положительный образец представляет собой преобразованную версию кода запроса, полученную на этапе предварительной обработки данных.
- Отрицательные образцы в партии: Отрицательные образцы — это все остальные образцы кода в текущем мини-пакете, которые отличаются от положительного образца.
4. Энкодер и датчик импульса:
- Трансформаторный энкодер с относительным положением и проекционной головкой MLP: И запрос, и положительные выборки подаются в кодировщик Transformer. Кодировщик включает кодирование относительного положения для фиксации синтаксической структуры и связей между токенами в коде. Проекционная головка MLP (многослойный персептрон) используется для отображения закодированных представлений в пространство более низкой размерности, где применяется контрастирующая цель обучения.
- Кодировщик импульса: Также используется импульсный кодер, который обновляется скользящим средним параметров запросного кодера. Это помогает поддерживать согласованность и разнообразие представлений, предотвращая коллапс контрастных потерь. Отрицательные образцы кодируются с помощью этого импульсного кодера и ставятся в очередь на процесс контрастного обучения.
5. Контрастная цель обучения:
- Вычисление потерь InfoNCE (сходство): Команда Потери InfoNCE (оценка контрастности шума) рассчитывается для максимизации сходства между запросом и положительными образцами при минимизации сходства между запросом и отрицательными образцами. Эта цель гарантирует, что изученные внедрения будут различительными и надежными, фиксируя семантическое сходство фрагментов кода.
Вся структура использует сильные стороны контрастного обучения для изучения осмысленных и надежных вложений кода из неразмеченных данных. Использование преобразований AST и импульсного кодировщика еще больше повышает качество и эффективность изученных представлений, что делает TransformCode мощным инструментом для различных задач разработки программного обеспечения.
Ключевые особенности TransformCode
- Гибкость и адаптивность: Может быть расширен для различных последующих задач, требующих представления кода.
- Эффективность и масштабируемость: Не требует большой модели или обширных обучающих данных, поддерживает любой язык программирования.
- Неконтролируемое и контролируемое обучение: Может применяться к обоим сценариям обучения путем включения меток или целей для конкретных задач.
- Регулируемые параметры: Количество параметров кодера можно регулировать в зависимости от доступных вычислительных ресурсов.
TransformCode представляет метод увеличения данных, называемый преобразованием AST, применяющий синтаксические и семантические преобразования к исходным фрагментам кода. Это генерирует разнообразные и надежные образцы для контрастного обучения.
Применение встраивания кода
Встраивание кода произвело революцию в различных аспектах разработки программного обеспечения, преобразовав код из текстового формата в числовое представление, используемое моделями машинного обучения. Вот некоторые ключевые приложения:
Улучшенный поиск кода
Традиционно поиск кода основывался на сопоставлении ключевых слов, что часто приводило к нерелевантным результатам. Встраивание кода обеспечивает семантический поиск, при котором фрагменты кода ранжируются на основе их сходства в функциональности, даже если они используют разные ключевые слова. Это значительно повышает точность и эффективность поиска соответствующего кода в больших кодовых базах.
Умное завершение кода
Инструменты завершения кода предлагают соответствующие фрагменты кода в зависимости от текущего контекста. Используя встраивание кода, эти инструменты могут предоставлять более точные и полезные рекомендации, понимая семантическое значение написанного кода. Это приводит к более быстрому и продуктивному программированию.
Автоматизированное исправление кода и обнаружение ошибок
Встраивание кода можно использовать для выявления шаблонов, которые часто указывают на ошибки или неэффективность кода. Анализируя сходство фрагментов кода и известных шаблонов ошибок, эти системы могут автоматически предлагать исправления или выделять области, которые могут потребовать дальнейшей проверки.
Улучшенное суммирование кода и создание документации
Большим базам кода часто не хватает надлежащей документации, что затрудняет понимание их работы новыми разработчиками. Встраивание кода позволяет создавать краткие описания, отражающие суть функциональности кода. Это не только повышает удобство сопровождения кода, но и облегчает передачу знаний внутри команд разработчиков.
Улучшенные проверки кода
Проверка кода имеет решающее значение для поддержания качества кода. Встраивание кода может помочь рецензентам, выявив потенциальные проблемы и предложив улучшения. Кроме того, они могут облегчить сравнение различных версий кода, делая процесс проверки более эффективным.
Межъязыковая обработка кода
Мир разработки программного обеспечения не ограничивается одним языком программирования. Встраивание кода обещает облегчить задачу обработки межъязыкового кода. Улавливая семантические отношения между кодом, написанным на разных языках, эти методы могут позволить решать такие задачи, как поиск и анализ кода на разных языках программирования.












