Искусственный интеллект
Эндрю Нг критикует культуру переобучения в машинном обучении
Эндрю Нг, один из самых влиятельных голосов в области машинного обучения за последнее десятилетие, в настоящее время выражает обеспокоенность относительно того, в какой степени сектор делает акцент на инновациях в архитектуре моделей по сравнению с данными, и, в частности, в какой степени он позволяет представлять «переобученные» результаты как обобщенные решения или достижения.
Это огульная критика современной культуры машинного обучения, исходящая от одного из ее высших руководителей, и она влияет на доверие в секторе, охваченном опасениями по поводу третий коллапс уверенности бизнеса в развитии ИИ в течение шестидесяти лет.
Нг, профессор Стэнфордского университета, также является одним из основателей deeplearning.ai и в марте опубликовал метательный на сайте организации, которая дистиллировала недавняя речь его до нескольких основных рекомендаций:
Во-первых, исследовательское сообщество должно перестать жаловаться на то, что очистка данных представляет собой 80% проблем в машинном обучении, и заняться разработкой надежных методологий и практик MLOps.
Во-вторых, ему следует отойти от «легких побед», которые можно получить путем подгонки данных под модель машинного обучения, чтобы он хорошо работал на этой модели, но не мог обобщать результаты или создавать широко применяемую модель.
Принятие вызова архитектуры и курирования данных
«Я считаю, — написал Нг, — что если 80 процентов нашей работы составляет подготовка данных, то обеспечение качества данных — важная задача команды машинного обучения».
Он продолжал:
«Вместо того, чтобы рассчитывать на то, что инженеры найдут лучший способ улучшить набор данных, я надеюсь, что мы сможем разработать инструменты MLOps, которые помогут сделать создание систем ИИ, включая создание высококачественных наборов данных, более воспроизводимым и систематическим».
«MLOps — это молодая область, и разные люди определяют её по-разному. Но я считаю, что важнейшим организационным принципом команд и инструментов MLOps должно быть обеспечение последовательного и высококачественного потока данных на всех этапах проекта. Это поможет многим проектам идти более гладко».
Выступление в Zoom в прямом эфире Вопросы и ответы В конце апреля Нг обратился к проблеме применимости систем анализа машинного обучения для радиологии:
«Оказывается, что когда мы собираем данные из Стэнфордской больницы, затем мы обучаем и тестируем данные из той же больницы, мы действительно можем публиковать документы, показывающие, что [алгоритмы] сопоставимы с радиологами-людьми в обнаружении определенных состояний.
«…[Когда] вы берете ту же модель, ту же систему ИИ в более старую больницу на той же улице, на более старой машине, и техник использует немного другой протокол обработки изображений, эти данные дрейфуют, что приводит к снижению производительности системы ИИ. значительно деградировать. Напротив, любой радиолог-человек может пройти по улице в старую больницу и все будет в порядке».
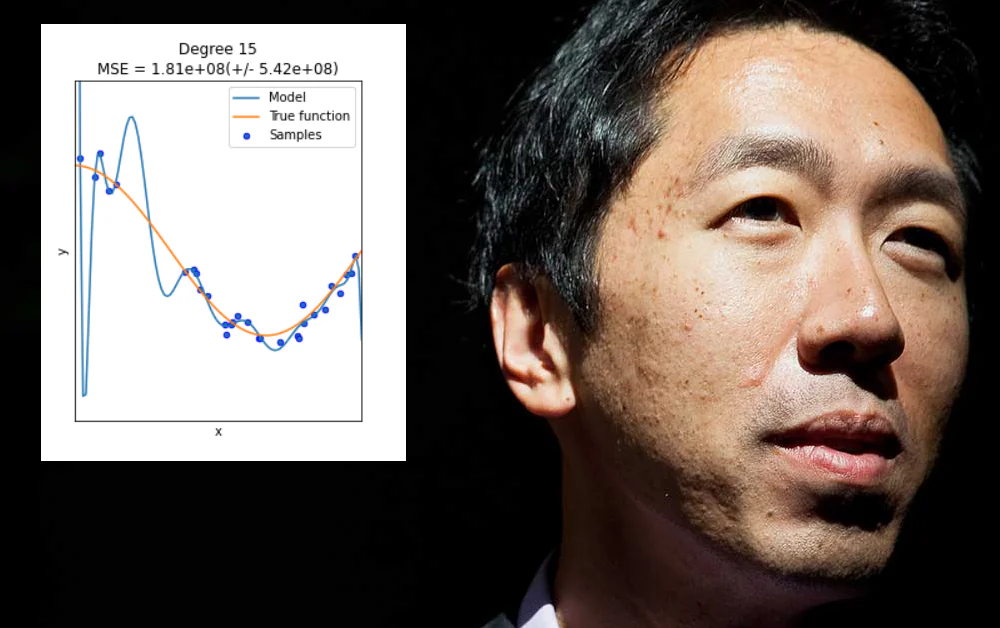
Заниженная спецификация — это не решение
Переобучение возникает, когда модель машинного обучения специально разработана с учётом особенностей конкретного набора данных (или способа их форматирования). Это может включать, например, указание весовых коэффициентов, которые дадут хорошие результаты для этого набора данных, но не будут «обобщаться» для других данных.
Во многих случаях такие параметры определяются на основе аспектов обучающего набора, не связанных с данными, таких как конкретное разрешение собранной информации или другие особенности, которые не обязательно будут повторяться в других последующих наборах данных.
Хотя было бы неплохо, переоснащение — это не проблема, которую можно решить путем слепого расширения объема или гибкости архитектуры данных или дизайна модели, когда на самом деле нужны широко применимые и очень важные функции, которые будут хорошо работать в диапазоне данных. среде – более сложная задача.
В целом, подобная «недоопределенность» приводит лишь к тем самым проблемам, которые недавно описал Нг: когда модель машинного обучения терпит неудачу на неизвестных данных. Разница в данном случае заключается в том, что модель терпит неудачу не потому, что данные или их форматирование отличаются от исходного переобученного обучающего набора, а потому, что модель слишком гибкая, а не слишком хрупкая.
В конце 2020 г. статье Недостаточная спецификация создает проблемы для доверия к современному машинному обучению подверг резкой критике эту практику и носил имена не менее сорока исследователей машинного обучения и ученых из Google и Массачусетского технологического института, а также других учреждений.
В статье критикуется «обучение по сокращенным траекториям» и рассматривается, как модели с недостаточной спецификой могут резко отклоняться от заданной начальной точки, с которой начинается обучение модели. Авторы отмечают:
«Мы увидели, что недостаточная спецификация повсеместно встречается в практических конвейерах машинного обучения во многих областях. Действительно, благодаря недостаточной спецификации существенно важные аспекты решений определяются произвольным выбором, таким как случайное начальное число, используемое для инициализации параметров».
Экономические последствия изменения культуры
Несмотря на свою научную репутацию, Нг не является легкомысленным академиком, но имеет глубокий и высокий опыт работы в отрасли, будучи соучредителем Google Brain и Coursera, бывшим главным научным сотрудником по большим данным и искусственному интеллекту в Baidu, а также основательницей Landing AI, которая управляет 175 миллионами долларов США для новых стартапов в этом секторе.
Когда он говорит: «Вся сфера искусственного интеллекта, не только здравоохранение, имеет разрыв между концепцией и производством», это призвано пробудить сектор, чей нынешний уровень шумихи и неоднозначная история все чаще характеризуют его как неопределенную долгосрочную бизнес-инвестицию. окружать по проблемам определения и объема.
Тем не менее, запатентованные системы машинного обучения, которые хорошо работают в реальных условиях и не работают в других условиях, представляют собой тот тип захвата рынка, который может окупить инвестиции в отрасль. Представление «проблемы переобучения» в контексте профессиональной опасности — это неискренний способ монетизировать корпоративные инвестиции в исследования с открытым исходным кодом и создание (эффективно) проприетарных систем, копирование которых конкурентами возможно, но проблематично.
Будет ли этот подход работать в долгосрочной перспективе, зависит от того, в какой степени по-прежнему требуются реальные прорывы в машинном обучении. все более высокий уровень инвестиций, и будут ли все производственные инициативы неизбежно в той или иной степени мигрировать в FAANG из-за колоссальных ресурсов, необходимых для хостинга и операций.












